It is possible to extend the power of XSLT using JavaScript embedded into the XSL file. Therefore any web application that allows the user to upload their own XSL file will be vulnerable to Cross Site Scripting attacks.
Well, that's not exactly true, at least on Microsoft platform.
Microsoft tackled this issue long time ago. Both MSXML 6.0 and .NET (since 2.0) don't allow script extensions and document() function in XSLT by default. One has to enable them explicitly. So the truth is s bit different: any web application that allows the user to upload their own XSL file and explicitly allows executing embedded scripts will be vulnerable to Cross Site Scripting attacks.
While we at this, here is some refresher for this important to know topic:
Untrusted style sheets are those that come from an untrustworthy domain. There is no way to eliminate denial of service (DoS) attacks when processing untrusted style sheets or untrusted documents without removing necessary functionality. If denial of service is a concern, do not accept untrusted style sheets or untrusted documents for transformation.
Cross-Site Attacks
It is not safe to compile and execute an untrusted style sheet within a trusted page (such as a page from your local hard drive). The style sheet may contain the document() function or xsl:include / xsl:import statements, which are capable of loading trusted files and sending them back to the untrusted domain.
XSLT Scripts Are Prohibited by Default
The DOM supports XSLT transformations via calls to the transformNode method and transformNodeToObject method. XSLT supports scripting inside style sheets using the <msxsl:script> element. This allows custom functions to be used in an XSLT transformation. In MSXML 6.0 this feature is disabled by default. If you require scripting in your XSLT transformations, you can enable the feature by setting the AllowXsltScript Property to true.
To allow XSLT scripting (JScript):
doc.setProperty("AllowXsltScript", true);
To disallow XSLT scripting:
doc.setProperty("AllowXsltScript", false);
Internet Explorer uses MSXML 3.0 by default, so when using the MIME viewer to transform scripts, Internet Explorer's security settings are used.
However, if you use MSXML 6.0 via script in Internet Explorer to execute transformations, when the AllowXsltScript property is set to false scripting is disabled no matter what Internet Explorer's settings are. When AllowXsltScript is set to true, Internet Explorer's security settings are used for executing.
The XSLT document Function Is Disallowed by Default
The DOM supports XSLT transformations via calls to the transformNode and transformNodeToObject methods. The XSLT document function provides a way to retrieve other XML resources from within the XSLT style sheet beyond the initial data provided by the input stream. In MSXML 6.0 this feature is disabled by default. If you must use the document function in your XSLT transformations, you can enable the feature by setting the AllowDocumentFunction property to true.
The following is the JScript code to allow the document function:
doc.setProperty("AllowDocumentFunction", true);
To disallow the document function:
doc.setProperty("AllowDocumentFunction", false);
If you enable the document function, you should be aware that the document function runs with the same security settings as the style sheet. If your style sheet is running in a trusted security context, then all files loaded using the document function will run in the same security context. For example, if scripts are allowed in the main style sheet, they will be allowed in all the included and imported files. You should not load untrusted documents via the document function.
Loading External Files Is Prohibited by Default
External files loaded via xsl:include or xsl:import are allowed and processed by default in MSXML 4.0 and 5.0 for backward compatibility. In MSXML 6.0, external files are not processed by default – they must be explicitly enabled by the developer.
If you are using MSXML 6.0 and all of your XSLT style sheets and XML documents come from a secure site, you can allow external schemas by setting the resolveExternals property to true. If you are using MSXML 4.0 or 5.0 and your XSLT style sheets and XML documents do not come from a secure site, you can operate in a safer mode by setting resolveExternals to false.
The XslCompiledTransform class supports the xsl:import or xsl:include elements by default. The XslCompiledTransform class disables support for the document() function by default. The XsltSettings class is used to enable the document() function.
The Load and Transform methods include overloads that take an XmlResolver object as one of its arguments. If an XmlResolver is not specified, a default XmlUrlResolver with no credentials is used.
You can control how external resources are accessed by doing one of the following:
Restrict the resources that the XSLT process can access by using an XmlSecureResolver object.
Do not allow the XSLT process open any external resources by passing in null to the XmlResolver argument.
Script Blocks
The XslCompiledTransform class does not support script blocks by default. Script blocks are enabled using the XsltSettings class. XSLT scripting should be enabled only if you require script support and you are working in a fully trusted environment.
Extension Objects
Extension objects add programming capabilities to XSLT transformations. This feature is enabled by default. If extension objects are passed to the Transform method, they are used in the XSLT transformation.
Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets.
Now short documentation about running compiled XSLT stylesheets.
Let's say you have a stylesheet called mytransform.xsl. First you compile it using nxsltc:
nxsltc mytransform.xsl /out:mytransform.dll
The result is mytransform.dll, containing mytransform class.
-c option says you want to run compiled stylesheet. Instead of XSLT stylesheet file name you pass compiled stylesheet class name (fully qualified if it has a namespace). And you need to specify dll file, where compiled stylesheet can be found.
Of course if you can afford assume things you can make it shorter. If dll is named after stylesheet and can be found in the current directory, you can omit it:
nxslt3 document.xml -c mytransform
Alternatively if dll contains single compiled stylesheet you can specify dll and omit stylesheet:
nxslt3 document.xml -c -af mytransform.dll
If you happens to compile your stylesheets into a strongly named dll:
nxsltc mytransform.xsl /keyfile:d:\keys\test.snk
and then installed it into the GAC, you run it by specifying full or partial dll name after -an option:
And finally. nxslt3 is a free feature-rich .NET 3.5 XSLT command line utility and NAnt/MSBuild task which uses .NET XSLT processor - XslCompiledTransform class and supports XML Base, XInclude, XPointer, EXSLT, compiled stylesheets, embedded stylesheets, processing instruction, multioutput, custom URI resolving, custom extension functions, pretty printing, XHTML output, XSLT 2.0-like character maps and more.
nxslt3.exe/NxsltTask are free tools under BSD license. Download here.
I updated nxsltc - XSLT compiler for .NET 3.5 tool one more time. I added /version:<x.x.x.x> and /keyfile:<file> options. Former is used to specify resulting DLL version and latter - to sign it with a strong name.
D:\>nxsltc.exe /?
XSLT Compiler version 1.0beta2 for .NET 3.5
(c) 2007 Oleg Tkachenko, http://www.xmllab.net
Usage: nxsltc [options]
where possible options include:
/out: Specifies the output file name
/debug[+|-] Emit debugging information
/nowarn Disable all warnings
/namespace: Specifies namespace for compiled stylesheets
/version: Specifies assembly version
/keyfile: Specifies strong name key file
/help Display this usage message (Short form: /?)
/nologo Do not display compiler copyright banner
I also updated nxsltc.exe (well, just rebuilt it using Visual Studio 2008 Beta2).
nXSLTC is an experimental XSLT to MSIL compiler for the forthcoming .NET 3.5. nXSLTC compiles one or more XSLT stylesheets into DLL. Compiled stylesheets then can be used for transforming XML documents using XslCompiledTransform class.
What's the probability of having two car accidents in one month? It must be high enough. Just a month after the first one some asshole hit me and run away. I wonder if it's a bad luck or actually a good luck? Sure, my own car is totaled and a company car doesn't look good either, but hey, I didn't get even a scratch, so I believe I'm a lucky guy.
Ok, back to work. I uploaded version 2.3 of the nxslt2.exe/NxsltTask tool. It's probably the last version for .NET 2.0. Anyway, here is what's new:
nxslt.exe options files (@file option) - useful when your command line gets too long.
XHTML output mode (-xhtml option) - this approach in action.
XSLT 2.0-like character maps (-cm option) - just like in XSLT 2.0, but in a proprietary namespace. I have to blog about this feature.
nxslt and NxsltTask are now debuggable - as it turned out when round-tripping assemblies with ildasm/ilasm there is still a solution to keep them debuggable.
resolving XInclude for XSLT stylesheets is now off by default - because usually nobody needs it and it breaks Docbooks stylesheets.
-xslxi option to turn XInclude for XSLT stylesheets on - if you still want it.
fixed several bugs preventing running Docbook stylesheets - XslCompiledTransfrom + DTD in imported stylesheets and documents loaded via document() function + custom XmlReaders= nightmare.
Oh, just in case: nxslt2 is a free feature-rich .NET 2.0 XSLT command line utility and NAnt/MSBuild task which uses .NET 2.0 XSLT processor - XslCompiledTransform class and supports XML Base, XInclude, XPointer, EXSLT, embedded stylesheets, processing instruction, multioutput, custom URI resolving, custom extension functions, pretty printing, XHTML output, XSLT 2.0-like character maps and more.
It's known that .NET XSLT engine - XslCompiledTransform natively supports two EXSLT extension functions - exsl:node-set() and exsl:object-type(). Not that it's widely known (msdn still says nothing about it), but lots of people are using this handy feature. The main benefit is that using EXSLT's version of node-set() function allows complex XSLT stylesheets (and I guess 80% of complex stylesheets can't live without xxx:node-set() function) to be portable between .NET, Java and libxslt.
Now, let's admit this fact is very little known. I've seen even advanced XSLT developers still using annoying techniques like switching "http://exslt.org/common" and "urn:schemas-microsoft-com:xslt" namespaces or awkward xsl:choose "function-available('exslt:node-set')" blocks. That's wrong.
These days you don't need any special handling for EXSLT exsl:node-set() function in your server-side oriented XSLT stylesheets. Just use it. .NET, Java and libxslt all support it.
I think (.NET and MSXML)-only msxsl:node-set() function should be avoided. Unless you are targeting browsers (in which case you need this trick).
I found it useful to insert EXSLT common namespace declaration into Visual Studio templates for XSLT files. It works as a reminder and is just handy. Here is how you can do it. Open XSLT templates for "Add new item" and "New File" commands:
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\ItemTemplatesCache\CSharp\1033\XSLTFile.zip\XSLTFile.xslt
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\ItemTemplatesCache\VisualBasic\1033\XSLTFile.zip\XSLTFile.xslt
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\NewFileItems\xsltfile.xslt
and add xmlns:exsl="http://exslt.org/common" and exclude-result-prefixes="exsl" to the xsl:stylesheet element:
Producing XHTML using XSLT 1.0 processor is tough (no wonder - XSLT 1.0 is so old - it was published even before XHTML 1.0). While XHTML is just XML, XHTML spec defines a set of very specific formatting rules called "HTML Compatibility Guidelines". The goal is to facilitate rendering of XHTML by HTML browsers (such as Internet Explorer :).
The guidelines say for instance that elements with non-empty content model (such as <p>) must never be serialized in minimized form (<p />), while elements with empty content model (such as <br>) must never be serialized in full form (<br></br>).
While XML doesn't care about such nonsense, HTML browsers might be confused and so XHTML generation should be smart enough. And XSLT 1.0 processors can only output text, HTML or XML (XSLT 2.0 processors can also do XHTML). That's why generating XHTML using XSLT 1.0 processor is tough.
I implemented one simple solution to the problem in the Mvp.Xml library 2.3. Here is a sample that says it all:
XSLT stylesheet:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="yes"
doctype-system="http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
doctype-public="-//W3C//DTD XHTML 1.0 Transitional//EN"/>
<xsl:template match="/">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title/>
</head>
<body>
<p>Para element must have end tag even if empty:</p>
<p/>
<p>These elements must not have end tags:</p>
<p>
<br></br>
<hr></hr>
<img src="foo.jpg" alt="bar"></img>
</p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
The code:
using System;
using System.Xml.XPath;
using System.IO;
using Mvp.Xml.Common.Xsl;
class Program
{
static void Main(string[] args)
{
XPathDocument doc = new XPathDocument(
new StringReader(""));
MvpXslTransform xslt = new MvpXslTransform();
xslt.Load("../../XSLTFile1.xslt");
xslt.EnforceXHTMLOutput = true;
xslt.Transform(new XmlInput(doc), null,
new XmlOutput(Console.Out));
}
}
The result:
<?xml version="1.0" encoding="DOS-862"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title></title>
</head>
<body>
<p>Para element must have end tag even if empty:</p>
<p></p>
<p>These elements must not have end tags:</p>
<p>
<br />
<hr />
<img src="foo.jpg" alt="bar" />
</p>
</body>
</html>
If for some weird reason you don't want to use MvpXslTransform class, you can stay with XslCompiledTransform and just output via XhtmlWriter class:
using System;
using System.Xml.XPath;
using System.Xml.Xsl;
using System.Xml;
using System.IO;
using Mvp.Xml.Common;
class Program
{
static void Main(string[] args)
{
XPathDocument doc = new XPathDocument(
new StringReader(""));
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("../../XSLTFile1.xslt");
xslt.Transform(doc, null,
new XhtmlWriter(
XmlWriter.Create(Console.Out, xslt.OutputSettings)));
}
}
Saxon, famous XSLT 2.0 and XQuery processor, supports XInclude since version 8.9. But in Java version only! When I first heard about it I thought "I have good XInclude implementation for .NET in Mvp.Xml library, let's check out if Saxon on .NET works with XInclude.NET". I did some testing only to find out that they didn't play well together.
Turned out Saxon (or JAXP port to .NET, don't remember) relies on somewhat rarely used in .NET XmlReader.GetAttribute(int) method (yes, accessing attribute by index), and XIncludingReader had a bug in this method.
Finally I fixed it and so XIncludingReader from recently released Mvp.Xml library v2.3 works fine with Saxon on .NET.
Here is a little sample how to process XML Inclusions in source XML document before XSLT transformation.
using System;
using Saxon.Api;
using Mvp.Xml.XInclude;
class Program
{
static void Main(string[] args)
{
Processor proc = new Processor();
XdmNode doc = proc.NewDocumentBuilder().Build(
new XIncludingReader("d:/test/document.xml"));
XsltExecutable xslt = proc.NewXsltCompiler().Compile(
new Uri("d:/test/foo.xsl"));
XsltTransformer trans = xslt.Load();
trans.InitialContextNode = doc;
Serializer ser = new Serializer();
ser.SetOutputStream(Console.OpenStandardOutput());
trans.Run(ser);
}
}
I released version 2.3 of the Mvp.Xml Library, which is part of the Mvp.Xml Project developed by Microsoft MVPs in XML technologies worldwide. It is aimed at supplementing .NET framework XML processing functionality. Mvp.Xml Library provides .NET implementations of the EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes and tools making XML programming in .NET platform easier, more productive and effective.
This is another minor release of the Mvp.Xml Library for .NET 2.0. Version 2.3 fixes lots of bugs and introduces some new features. Most important new features include:
XHTML output mode for the MvpXslTransform class
XSLT2-like output character mapping for the MvpXslTransform class
XmlWrappingReader and XmlWrappingWriter to simplify creating of custom XmlReader or XmlWriter
XIncludingReader now implements IXmlLineInfo interface
MvpXslTransform.AddExsltExtensionObjects() method allows to add EXSLT extension functions to your XsltArgumentList instance
XIncludingReader.Encoding property
New Mvp.Xml Library API documentation site generated using Sandcastle/DocProject, hosted at http://www.xmllab.net/mvpxml
Most important bugs fixed:
XIncludingReader now works well with Saxon.NET, XmlSerializer, DataSet and others
Library DLL is now debuggable
No more XmlValidatingReader and XmlTextReader used
I mean pre-XProc XSLT pipeline - just when you need to transform an XML document by a sequence of XSLT stylesheets - output from the first transformation goes as input to the second one and so on. This is useful technique helping dramatically simplify your complex multi-stage XSLT stylesheets. Unfortunately there is no simple way to perform such task effectively in .NET 2.0. Here I show you how Mvp.Xml project comes to the rescue.
Note: there is old crappy Microsoft KB article 320847 suggesting pipelining XSLT via byte buffer, Bleh!, don't do this.
The problem is that while the most efficient (fastest, taking less memory) XML store for doing XSLT transformations in .NET 2.0 is still old good XPathDocument (not surprisingly specially designed and optimized for XPath and XSLT), there is no way to take XSLT output directly to XPathDocument. XslCompiledTransform doesn't provide XmlReader over its output. It can do XmWriter, but XPathDocument cannot be loaded via XmlWriter (this is likely to be fixed in post Orcas .NET version).
The problem was solved though. Sergey Dubinets from the Microsoft XML Team contributed his excellent XslReader implementation, which provides an efficient way to read XSLT results as XmlReader. I later wrapped it all into MvpXslTransform class, which extends capabilities of the XslCompiledTransform class by adding support for transforming into XmlReader , vast collection of EXSLT extension functions, multiple outputs and transforming of IXPathNavigable along with XmlResolver.
Here is finally code sample that says it all:
using System;
using System.Xml.Xsl;
using System.Xml.XPath;
using System.Xml;
using Mvp.Xml.Common.Xsl;
class Program
{
public static void Main()
{
MvpXslTransform xslt1 = new MvpXslTransform();
xslt1.Load("../../XSLTFile1.xslt");
MvpXslTransform xslt2 = new MvpXslTransform();
xslt2.Load("../../XSLTFile2.xslt");
XPathDocument doc = new XPathDocument("../../source.xml");
XmlReader stage1Output = xslt1.Transform(new XmlInput(doc), null);
xslt2.Transform(new XmlInput(stage1Output), null,
new XmlOutput(Console.Out));
}
}
So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas"). Get it here (free open-source). I probably shouldn't be building this tool, but I have my reasons.
Why not? As a matter of fact, Mike Champion has announced back in February that Microsoft will provide XSLTC.exe tool in the next Visual Studio "Orcas", but apparently it didn't make it into March CTP, at least I didn't manage to find it. It probably will be included into the next drop.
Why yes? First - this is the best way of learning new technology and then - I plan to build something bigger, which Microsoft won't be doing - XSLT project for Visual Studio, so I need this code anyway.
Ok, so nXSLT.exe. It's a command line XSLT compiler for .NET 3.5. It compiles one or more XSLT stylesheets into DLL. These compiled stylesheets can be later used to transform XML documents using XslCompiledTransform class.
Microsoft decided to shut down GotDotNet site by July 2007. The official announcement goes like this:
Microsoft will be phasing out the GotDotNet site by July 2007.
Microsoft will phase out all GotDotNet functionality by July 2007. We will phase out features according to the schedule below. During the phase-out we will ensure that requests for features or pages that are no longer available will render enough information for you to understand what has changed. If you have any questions please don’t hesitate to contact the GotDotNet Support team. We are phasing out GotDotNet for the following reasons:
Microsoft wants to eliminate redundant functionality between GotDotNet and other community resources provided by Microsoft
Traffic and usage of GotDotNet features has significantly decreased over the last six months
Microsoft wants to reinvest the resources currently used for GotDotNet in new and better community features for our customers
If you still hosting anything at the GotDotNet - here is your moving deadlines:
Phase Out Schedule The GotDotNet phase out will be carried out in phases according the following timetable:
Target Date Areas to be Closed
February 20 Partners, Resource Center, Microsoft Tools
March 20 Private workspaces, Team pages, Message Boards
April 24 GDN CodeGallery (projected date)
May 22 GDN User Samples (projected date)
June 19 GDN Workspaces (projected date)
Well, obviously that was inevitable. GotDotNet sucked big despite any efforts made. Looks like Microsoft was learning how to do open source project hosting on the web and GotDotNet was first that first pancake that is always spoiled. CodePlex definitely tastes better.
There are couple of projects still hosted at the GotDotNet that I care about:
Chris Lovett's SgmlReader. Awesome tool for reading HTML via XmlReader. I suggested Chris to contribute SgmlReader to the Mvp.Xml project, let's see if he likes the idea.
XPathReader. Cool pull-based streaming XML parser supporting XPath queries. I'm admin there actually, so I think we are going to move XPathReader under the Mvp.Xml project umbrella real soon.
Our users have made it very clear that they want an XSLT 2.0 implementation once the Recommendation is complete. A team of XSLT experts is now in place to do this, the same people who have been working on the XSLT enhancements that will be shipped in the forthcoming "Orcas" release of Visual Studio / .NET 3.5. Orcas development work is winding down in advance of Beta releases over the next several months, so there is no possibility of shipping XSLT 2.0 in Orcas. The XSLT team will, however, be putting out Community Technology Previews (CTP) with the XSLT 2 functionality and appropriate tooling as the implementation matures. The eventual release date and ship vehicles (e.g. a future version of .NET or a standalone release over the Web) have not been determined, and depend on technical progress, customer demand, and other currently unknowable factors.
Good. Very good news for those who invested in XSLT. XSLT 2.0 is sooooo much better,so much easier to develop with language. And I'm sure this new Microsoft XSLT 2.0 engine is gonna rock.
XslCompiledTransform implements the following useful MSXML extension functions. But what if you need to use them in XPath-only context - when evaluating XPath queries using XPathNavigator?
HtmlAgilityPack is an open source project on CodePlex. It provides standard DOM APIs and XPath navigation -- even when the HTML is not well-formed!
Well, DOM and XPath over malformed HTML isn't new idea. I've been using XPath when screenscraping HTML for years - it seems to me way more reliable method that regular expressions. All you need in .NET is to read HTML as XML using wonderful SgmlReader from Chris Lovett. SgmlReader is an XmlReader API over any SGML document such as HTML.
But what I don't get is why would anyone (but browser vendors) want to implement DOM and XPath over HTML as is? Reimplementing not-so-simple XML specs over malformed source instead of making it wellformed and using standard API? May be I'm not agile anough but I don't think that's a good idea. I prefer standard proven XML API.
Here is Josh's sample that validates that Microsoft's home page lists Windows as the first item in the navigation sidebar implemented using SgmlReader:
SgmlReader r = new SgmlReader();
r.Href = "http://www.microsoft.com";
XmlDocument doc = new XmlDocument();
doc.Load(r);
//pick the first <li> element in navigation section
XmlNode firstNavItemNode =
doc.SelectSingleNode("//div[@id='Nav']//li");
//validate the first list item in the Nav element says "Windows"
Debug.Assert(firstNavItemNode.InnerText == "Windows");
I'm missing something obvious and spent already about two hours on that simple problem. I hope somebody profficient in MSBuild drops me a line. How do I build MSBuild custom task that has XML subtree?
How do I build custom MSBuild task that accepts such <parameters> subtree??? The documentation on MSBuild sucks. I mean it's fine if you just using tasks, but if you want to build your own task you screwd up.
XML Notepad 2006 was released on the 1st September 2006, and 2 months later it had 175,000 downloads! So it looks like this little utility has found a useful place in your toolkit which is exactly what we were hoping. Thanks for all the great feedback and bug reports; many of which have been incorporated and fixed in this new version. While this is mostly a bug fix release (like fixing the install on Vista!) there are also a few new features thrown in just for fun.
New in this version:
Added keyboard accelerators for find again (F3) and reverse find (SHIFT+F3).
Added support for loading IXmlBuilder and IXmlEditor implementations from different assemblies using new vs:assembly attribute.
Made source code localizable by moving all error messages and dialog strings to .resx files.
Added a default XSL transform.
New icons, a play on the Vista "Notepad" icons.
XML Notepad 2006 2007 is a tree view based XML editor, and it's not in my tool list because I can't work with XML editor which won't show me XML source, but then I'm XML geek and I feel more comfortable seeing angle brackets than tree view, while I'm sure lots of people will love it. Give it a try anyway.
I only wonder why all this stuff isn't in Visual Studio? Why is that Microsoft XML team can afford playing with another XML editor while Visual Studio XML Editor still sucks having no XML diff, no XPath search, no refactoring, no decent XSLT editor nor XML Schema designer?
Back in 2005 I was writing about speeding up Muenchian grouping in .NET 1.X. I was comparing three variants of the Muenchian grouping (using generate-id(), count() and set:distinct()). The conclusion was that XslTransform class in .NET 1.X really sucks when grouping using generate-id(), performs better with count() and the best with EXSLT set:distinct().
Here is that old graph:
Today a reader reminded me I forgot to post similar results for .NET 2.0 and its new shiny XslCompiledTransform engine. So here it is. I was running simple XSLT stylesheet doing Muenchian grouping. Input documents contain 415, 830, 1660, 3320, 6640, 13280, 26560 and 53120 orders to be grouped.
Besides being pretty damn faster that XslTransform, XslCompiledTransform shows expected results - there is no difference in a way you are doing Muenchian grouping in .NET 2.0 - all three variants I was testing are performing excellent with very very close results. Old XslTransform was full of bad surprises. Just switching to count() instead of generate-id() provided 7x performance boost in grouping. That was bad. Anybody digging into XslTransform sources knows how ridiculously badly generate-id() was implemented. Now XslCompiledTransform shows no surprises - works as expected. No tricks needed. That's a sign of a good quality software.
Reporting errors in XSLT stylesheets is a task that almost nobody gets done right. Including me - error reporting in nxslt sucks in a big way. Probably that's because I'm just lazy bastard. But also lets face it - XslCompiledTransform API doesn't help here.
Whenever there are XSLT loading (compilation) errors XslCompiledTransform.Load() method throws an XsltException containing description of the first error encountered by the compiler. But as a matter of fact internally XslCompiledTransform holds list of all errors and warnings (internal Errors property). It's just kept internal who knows why. Even Microsoft own products such as Visual Studio don't use this important information when reporting XSLT errors - Visual Studio's XML editor also displays only first error. That sucks.
Anyway here is a piece of code written by Anton Lapounov, one of the guys behind XslCompiledTransform. It shows how to use internal Errors list via reflection (just remember you would need FullTrust for that) to report all XSLT compilation errors and warnings. The code is in the public domain - feel free to use it. I'm going to incorporate it into the next nxslt release. I'd modify it a little bit though - when for some reason (e.g. insufficient permissions) errors info isn't available you still have XsltException with at least first error info.
private void Run(string[] args) {
XslCompiledTransform xslt = new XslCompiledTransform();
try {
xslt.Load(args[0]);
}
catch (XsltException) {
string errors = GetCompileErrors(xslt);
if (errors == null) {
// Failed to obtain list of compile errors
throw;
}
Console.Write(errors);
}
}
// True to output full file names, false to output user-friendly file names
private bool fullPaths = false;
// Cached value of Environment.CurrentDirectory
private string currentDir = null;
///
/// Returns user-friendly file name. First, it tries to obtain a file name
/// from the given uriString.
/// Then, if fullPaths == false, and the file name starts with the current
/// directory path, it removes that path from the file name.
///
private string GetFriendlyFileName(string uriString) {
Uri uri;
if (uriString == null ||
uriString.Length == 0 ||
!Uri.TryCreate(uriString, UriKind.Absolute, out uri) ||
!uri.IsFile
) {
return uriString;
}
string fileName = uri.LocalPath;
if (!fullPaths) {
if (currentDir == null) {
currentDir = Environment.CurrentDirectory;
if (currentDir[currentDir.Length - 1] != Path.DirectorySeparatorChar) {
currentDir += Path.DirectorySeparatorChar;
}
}
if (fileName.StartsWith(currentDir, StringComparison.OrdinalIgnoreCase)) {
fileName = fileName.Substring(currentDir.Length);
}
}
return fileName;
}
private string GetCompileErrors(XslCompiledTransform xslt) {
try {
MethodInfo methErrors = typeof(XslCompiledTransform).GetMethod(
"get_Errors", BindingFlags.NonPublic | BindingFlags.Instance);
if (methErrors == null) {
return null;
}
CompilerErrorCollection errorColl =
(CompilerErrorCollection) methErrors.Invoke(xslt, null);
StringBuilder sb = new StringBuilder();
foreach (CompilerError error in errorColl) {
sb.AppendFormat("{0}({1},{2}) : {3} {4}: {5}",
GetFriendlyFileName(error.FileName),
error.Line,
error.Column,
error.IsWarning ? "warning" : "error",
error.ErrorNumber,
error.ErrorText
);
sb.AppendLine();
}
return sb.ToString();
}
catch {
// MethodAccessException or SecurityException may happen
//if we do not have enough permissions
return null;
}
}
Feel the difference - here is nxslt2 output:
An error occurred while compiling stylesheet 'file:///D:/projects2005/Test22/Test22/test.xsl':
System.Xml.Xsl.XslLoadException: Name cannot begin with the '1' character, hexadecimal value 0x31.
And here is Anton's code output:
test.xsl(11,5) : error : Name cannot begin with the '1' character, hexadecimal value 0x31.
test.xsl(12,5) : error : Name cannot begin with the '0' character, hexadecimal value 0x30.
test.xsl(13,5) : error : The empty string '' is not a valid name.
test.xsl(14,5) : error : The ':' character, hexadecimal value 0x3A, cannot be included in a name.
test.xsl(15,5) : error : Name cannot begin with the '-' character, hexadecimal value 0x2D.
It's surprisingly easy in .NET 2.0. Obviously it can't be done with pure XSLT, but an extension function returning line number for a node takes literally two lines. The trick is to use XPathDocument, not XmlDocument to store source XML to be transformed.
The key is IXmlLineInfo interface. Every XPathNavigator over XPathDocument implements this interface and provides line number and line position for every node in a document. Here is a small sample:
using System;
using System.Xml;
using System.Xml.XPath;
using System.Xml.Xsl;
public class Test
{
static void Main()
{
XPathDocument xdoc = new XPathDocument("books.xml");
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("foo.xslt", XsltSettings.TrustedXslt,
new XmlUrlResolver());
xslt.Transform(xdoc, null, Console.Out);
}
}
Ability to report line info is another reason to choose XPathDocument as a store for your XML (in read-only scenarios such as query or transformation) - in addition to better performance and smaller memory footprint.
If you really need the same, but with XmlDocument, you have to extend DOM.
.NET's XmlReader is a great XML parser, but it has one big flaw in its API: XmlReader doesn't expose attribute types. XML actually defines 8 attribute types: CDATA, ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS. Yes, it's DTD, which apparently Microsoft considers to be dead, but ID, IDREF, IDREFS types are really important ones. They provide support for cross-references and many XML languages rely on them, particularly XPath, XSLT, XQuery, XPointer, XInclude.
That means XmlReader cannot be used to develop third-party implementations of those languages unless one sticks to XPathDocument/XmlDocument, which know attribute types internally.
I wonder if XLinq will have this information, because if not - XSLT over XLinq won't be supporting id() function.
Btw, in Java SAX and Stax both happily expose attribute types... Makes me envy.
I though I filed it as a bug years ago, but I didn't. So although it's too late, here it is. I'm sure it will be another "thanks for suggestion, we'll consider it for the next release", but anyway. Vote please whoever cares.
Another coding horror story was reported in the microsoft.public.dotnet.xml newsgroup:
I've been experiencing OutOfMemory errors on our prodution webserver for a few weeks now. I've finally managed to isolate (I think) the problem to our use of c# script blocks in our xsl files. While debugging I discovered that the app domain for one of our sites had 13000+ assemblies loaded.
Cool. This is just a remainder for those who use XSLT scripting (msxsl:script) in .NET: watch out, this feature can be pure evil if used unwisely - it leaks memory and there is nothing you can do about it.
The problem is that when XSLT stylesheet is loaded in .NET, msxsl:script is compiled into an assembly via CodeDOM and then loaded into memory, into the current application domain. Each time the stylesheet is loaded above process is repeated - new assembly is being generated and loaded into the application domain. But it's impossible to unload an assembly from application domain in .NET!
Here is KB article on the topic. It says it applies to .NET 1.0 only, but don't be confused - the problem exists in .NET 1.1 and 2.0. Moreover I'm pretty much pessimistic about if it's gonna be fixed in the future.
The solution is simple - just don't use script in XSLT unless you really really really have to. Especially on the server side - XSLT script and ASP.NET should never meet unless you take full resonsibility for caching compiled XslCompiledTransform. Use XSLT extension objects instead.
Update. Of couse Yuriy reminds me that msxsl:script runs faster than an extension object, because msxsl:script is available at compile time and so XSLT compiler can generate direct calls, while extension objects are only available at run-time and so can only be called via reflection.
That makes msxsl:script a preferrable but danger solution when your stylsheet makes lots of calls to extension functions.
In a perfect world of course msxsl:script would be compiled into dynamic methods (just like XSLT itself), which are GC reclaimable, but I don't think CodeDOM is capable of doing this currently. I wonder if it's possible to compile C#/VB/J# method source into dynamic method anyway?
Also it's interesting how to improve extension objects performance - what if extension objects could be passed at compile time? They are usually available anyway at that time too. Or what if compiled stylesheet could be "JITted" to direct calls instead of reflection?
This is second part of the post. Find first part here.
So what is a better way of creating custom XmlReader/XmlWriter in .NET 2.0? Here is the idea - have an utility wrapper class, which wraps XmlReader/XmlWriter and does nothing else. Then derive from this class and override methods you are interested in. These utility wrappers are called XmlWrapingReader and XmlWrapingWriter. They are part of System.Xml namespace, but unfortunately they are internal ones - Microsoft XML team has considered making them public, but in the Whidbey release rush decided to postpone this issue. Ok, happily these classes being pure wrappers have no logic whatsoever so anybody who needs them can indeed create them in a 10 minutes. But to save you that 10 minutes I post these wrappers here. I will include XmlWrapingReader and XmlWrapingWriter into the next Mvp.Xml library release.
Well, "XSLT 2.0 in .NET" survey at the XML Lab site has ended back in January and I forgot to select a winner. Ooops. Let's finish this now.
I obviously made a mistake requiring user registration for voting, but then I needed some way to identify a winner... Anyway, 40 people registered and voted (thanks guys), which is not bad for such a small unknown site. 72% need XSLT 2.0, 25% think it would be nice to have, 2% happy with XSLT 1.0. Quite predictable given my audience.
And the winner (choosen truly randomly using EXSLT random:random-sequence() function) is Yoeri Van de Moortel from Belgium. Congratulations, Yoeri! Get in touch with me, I need your address to send the "XSLT 2.0 Programmer's Reference" book by Mike Kay (or some other XSLT book if you happens to own this one already).
Ok, I'm back. I have updated eXml Web Server Control, which uses XslCompiledTransform, supports 70+ EXSLT functions, XInclude, friendly XML rendering, <?xml-stylesheet?>, embedded stylesheets etc.
Martin Szugat found some bugs and kindly provided patches, thanks Martin! Additionally I implemented one small but useful feature users kept asking for - cache dependencies for imported/included stylesheets. That's when you have included or imported stylesheet and modify it - now eXml control notices it and recompiles XSLT on the next request. Go get eXml Web server control v1.1.
Now I think about eXmlDataSource control... Free asp:XmlDataSource analog running XslCompiledTransform, supporting EXSLT, XInclude, <?xml-stylesheet?> and embedded stylesheets - it sounds useful, isn't it?
Vote now and get a chance to win the "XSLT 2.0" book by Mike Kay!
When the survey ends one lucky survey taker from whatever part of the world choosen randomly will get the book.
Note: you have to be registered on the Xml Lab site to vote. Sorry, but I need some simple way to identify the winner. Registration is simple and public - no email verification or something like, just fill in your name, password and email and then vote.
Now that XslCompiledTransform in .NET 2.0 supports exsl:object-type() extension function I think a little intro is needed as this is really new function for Microsoft-oriented XSLT developers.
There are two new killer but undocumented features in Microsoft .NET 2.0 pertaining to EXSLT. Anybody like me regularly digging in System.Xml assembly probably knows it, but general audience is still unaware. So I want to share these secrets.
Slowly, gradually and with not much loud buzz both modern managed platforms - Java and .NET have switched to compiling XSLT implementations by default. First Java 5.0 made compiling Apache XSLTC processor a default transformer in JAXP 1.3 (instead of interpreting Apache XALAN). Then Microsoft released .NET 2.0 with new XSLT implementation - XslCompiledTransform replacing now obsolete XslTransform (guess what - interpreting one). XSLTC compiles XSLT into Java bytecode just like Java compiler, while XslCompiledTransform compiles XSLT into Microsoft Intermediate Language (MSIL) just like C# or VB compiler. The similarity is striking. Does it mean the era of interpreting XSLT processors is over and XSLT compilation is the future?
This is the first Microsoft product using XInclude via Mvp.Xml library. Hope not the last one, way to go guys. I truly hope to see one day Microsoft Biztalk release including our EXSLT implementation.
As a matter of interest - Mvp.Xml project is an open-source project hosted at SourceForge, led by Microsoft MVPs and supplementing XML processing functionality in .NET. We currently provide .NET implementations of EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes and tools making XML programming in .NET platform easier, more productive and effective. Microsoft has licensed the Mvp.Xml project and has rights to use and distribute our code base.
Dare thinks I'm making fruitless noise asking people if they need XSLT 2.0:
I'm not sure how an informal survey in a blog would convince Microsoft one way or the other about implementing a technology. A business case to convince a product team to do something usually involves showing them that they will lose or gain significant marketshare or revenue by making a technology choice. A handful of XML geeks who want to see the latest and greatest XML specs implemented by Microsoft does not a business case make.
Well Dare you underestimate the power of geeks and blogs :) Of course I'm not making a busines case. I'm looking for real world XSLT2 business cases (and not without results btw) trying to help Microsoft XML Team. I can't disclose more, but believe me guys we really can help now with such obviousboring stuff like real world scenarios for XSLT2.
Then he comes with some good advice:
My advice to Oleg, if you want to see XSLT 2.0 in the .NET Framework then gather some like minded souls and build it yourself. Efforts like the MVP.XML library for the .NET Framework shows that there are a bunch of talented developers building cool enhancements to the basic XML story Microsoft provides in the .NET Framework.
First of all as one of developers who runs Mvp.Xml project I should say that "a bunch" is a big overstatement here. Unfortunately only a really handful people are willing/have a chance to contribute to the project. Actually now, 3 years after I switched to .NET I'm pretty much pessimistic about open-source .NET projects altogether. There is something with people's attitude, it's different from that one in Java or linux world. And so I'm also kinda pessimistic about community developed .NET XSLT2 as I know the field. But that's of course my backup plan in any case.
Also I found interesting some comments made to Dare's post. Take a look.
And my personal take is similar to the one expressed by Mike Champion: Microsoft will implement XSLT2 anyway. The question is only when.
I run into this article "Harnessing the BackPack API" by Michael K. Campbell in the new and very cool "XML 4 Fun" column at MSDN. The article is otherwise brilliant and really fun, but XML processing code samples are not so good. It's actually a great collection of XML processing antipatterns. Let's see.
Moving along business cases Microsoft seeks to implement XSLT 2.0 I'm trying to gather some opinion statistics amongs developers working with XML and XSLT. So I'm holding this survey at the XML Lab site:
Would you like to have XSLT 2.0 implementation in the .NET Framework?
The possible answers are:
Yes, I need XSLT 2.0
Yes, that would be nice to have
No, continue improving XSLT 1.0 impl instead
No, XSLT 1.0 is enough for me
Vote now and get a chance to win the "XSLT 2.0" book by Mike Kay!
When the survey ends (probably in a month or so) one lucky survey taker from whatever part of the world choosen randomly will get the book.
Note: you have to be registered on the Xml Lab site to vote. Sorry, but I need some simple way to identify the winner. Registration is simple and public - no email verification or something like, just fill in your name, password and email, get registered and then vote.
Take your chance to influence Microsoft's decision on XSLT 2.0 and win XSLT 2.0 book!
I'm glad to announce first release of the eXml - extended ASP.NET Xml Web Server Control.
eXml is a free open-source ASP.NET 2.0 Web server control extending and improving standard ASP.NET XML Web server control. eXml Web server control uses new .NET 2.0 XSLT processor - XslCompiledTransform class to perform XSL transformations thus providing in average 400% performance boost and improved standard compliance. Additionally eXml Web server control provides built-in support for 70+ EXSLT extension functions, XML Inclusions (XInclude) 1.0, friendly XML rendering, <?xml-stylesheet?> XML processng instruction, embedded stylesheets and conditional whitespace stripping.
nxslt v2.0 (aka nxslt2) is available for download. This is first nxslt release for .NET 2.0.
nxslt is a free feature-rich command line utility that allows to perform XSL Transformations (XSLT) using .NET Framework 2.0 XSLT implementation - System.Xml.Xsl.XslCompiledTransform class. nxslt is compatible with Microsoft's MSXSL.EXE tool and additionally supports XInclude 1.0, 70+ EXSLT and EXSLT.NET extension functions, multioutput, embedded stylesheets, custom XmlResolvers and custom extension functions, pretty printing etc etc etc.
I'm glad to announce release 2.0 of the Mvp.Xml library. This is first Mvp.Xml release for .NET 2.0. Download it here.
Mvp.Xml project is developed by Microsoft MVPs in XML technologies and XML Web Services worldwide. It is aimed at supplementing .NET framework XML processing functionality available through the System.Xml namespace and related namespaces such as System.Web.Services. Mvp.Xml project currently provides .NET implementations of EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes such as XmlSerializerCache, IndexingXPathNavigator, SubtreeXPathNavigator, XPathNavigatorIterator, XslReader, MpXslTransform and tools making XML programming in .NET platform easier, more productive and effective.
After initial announcement XLinq hubbub seems to be more and more quiet - users are busy moving to .NET 2.0 and Microsoft is working on the next preview version. Anyway, there are some news:
This is an updated version of the LINQ Technical Preview unveiled at PDC 2005. It includes samples, whitepapers, hands-on labs and compiler support to create LINQ-enabled applications using the RTM release of Visual Studio 2005 or Visual C# 2005 Express Edition.
Similar update for VB is available too. Note that LINQ homepage is obsolete at this point
There is a knownproblem with new XSLT processor in just released Microsoft .NET 2.0 - XslCompiledTransform class doesn't support pull mode XSLT - outputting XSLT result in XmlReader form as obsolete XslTransform class did. I'm happy to announce that the problem is solved now. Sergey Dubinets from the Microsoft XML Team has developed XslReader implementation which allows to read XSLT output via XmlReader in a very efficient way - i.e. without full output buffering. It's concurrent writer-reader bridge, which runs XSLT in another thread and lets it to produce another output portion whenever reader wants to read more.
And Sergey kindly donated his code to the Mvp.Xml project, so it will be part of the Common module of Mvp.Xml library v2.0, which is going to be released really really really really soon. Kudos to Sergey! Stay tuned.
Another minor nxslt release is available - v1.6.4. This version adds support for the "extension-element-prefixes" attribute and fixes a glitch in transformation timings reporting.
What's the problem with "extension-element-prefixes" attribute? When using <exsl:document> extension element to produce multiple outputs some EXSLT-aware XSLT tools (like 4XSLT) rightly require "exsl" prefix to be registered in the "extension-element-prefixes" attribute. The problem was that .NET's XslTransform class while not supporting extension elements at all, throws an exception once encountering "extension-element-prefixes" attribute. So for running the same stylesheet with nxslt one had to remove "extension-element-prefixes" attribute, and with other tools - add it. Bad bad bad. So in nxslt 1.6.4 I fixed the issue by hiding "extension-element-prefixes" attribute from XslTransform class, so now you can use it in you stylesheets and enjoy better portability.
As a matter of interest, new .NET 2.0 XSLT processor - XslCompiledTransform class, while still not supporting extension elements, at least ignores "extension-element-prefixes" attribute. Good.
In .NET 2.0 ValidationType.Auto value is made obsolete. What's worse - it doesn't work for XmlReaders created via XmlReader.Create() factory method. But how do you validate against either DTD and/or schema, i.e. against DTD if document has a DOCTYPE and/or schema if any is applicable? The answer is: you can chain two XmlReaders, one set up for performing DTD validation and second - schema validation.
Microsoft XML Team has published an article "Migrating to XslCompiledTransform" by my pals Sergey Dubinets and Anton Lapunov. It explains how to migrate to the new XSLT 1.0 processor in .NET 2.0 - XslCompiledTransform class. XslCompiledTransform is a revolutionary XSLT processor - it's gonna be the first truly compiled mainstream XSLT processor. It's fast and conformant just as MSXML4.
The article covers: how XslCompiledTransform works, differences in API, in behaviour, new functionality, faq, howto.
The article is meant to be updated on a regular basis. Once a new migration issue is discovered the article will be updated with a solution. So bookmark it. And the article is not complete yet, some parts are still to be done. Keep up your great work, guys.
nxslt 1.6.1 is available for download at the xmllab.net. This is bug fix only release. Marc Stober reported that when running into XInclude error he got MissingManifestResourceException. Apparently XInclude string resources weren't compiled into the nxslt.exe. This release fixes this bug. Thanks for reporting, Marc!
nxslt is free feature-rich command line .NET XSLT utility, supporting EXSLT.NET, XInclude, multiple output etc etc etc.
No new features in this release. Instead I'm working on nxslt2 - nxslt for .NET 2.0.
I finally got some time (18 hours in a plane to Seattle :) to settle down my mind about XLinq. Erik Meijer's excellent article, which explains XLinq from functional programming point of view made me changing my mind on some issues I wrote earlier, some hands on experience and some comments from smart readers helped me to see a bigger picture.
XLinq is at early stages, but what else would I like to see in XLinq? Here are my crazy wishes.
Shortcuts. In C# I need book["title"] instead of book.Element("title").
last() and position()
Literal XML just like in C-omega, not "kinda pseudo XML literals" like in VB9.
Fine control over serialization just like in XQuery
XPath support. I know it anyway and many do, so why to learn any new way to select nodes in XML tree? XPath is small, concise and intuitive. I want to write less code, so XPath is the way to go.
Nodes in XLinq overload ToString() method to provide pretty-printed outer XML representation. At the same time nodes contain (familiar for MSXML users and new for .NET users) readonly Xml property, which returns raw (not pretty-printed) outer XML representation. At also at the same time casting element to a string returns element's value (string value with no angle brackets). There are also WriteTo() methods and Save() methods to complete the picture. I believe that's unnecessary confusing. Not only cast to string and ToString() do completely different things, but also there are many different ways of serializing nodes.
In XLinq XML Tree is exposed in a heterogenos way, that is nodes in a tree don't belong to a common type. Traditionally XML tree models are homogeneous, e.g. in DOM every node belongs to a specific kind of XmlNode class. But in XLinq attributes and text nodes aren't actually nodes. Instead attributes are just name-value properties of element nodes and text nodes while being internally normal nodes, never get exposed as such, but only as values they contain, so in effect what you can get out of XLinq tree is XNode (XElement etc), XAttribute and String values (which you can cast to appropriate CLR types). Apparently the goal was to simplify API and data model comprehension for users.
XLinq is new and hot technology everybody seems to be happy with. I'm going to post a different review series - not what I like, but what I dislike and want to be fixed in XLinq. Sorry in advance for bitter words, but it's better when your friend says them.
Being excited about XLinq I couldn't stop myself from grabbing XLinq.NET domain name. I'm going to try to build a community portal for the XLinq technology. The goal is basically to push XLinq by growing a community around it. There is definitely a need for Microsoft-independent easily accessible place where developers can find XLinq resources or share their experience.
Well, that's my vision at the moment. There is not much content at the site currently, just basic info and links. If you've got any ideas/suggestions about what would like to find at XLinq.Net, please drop me a line.
C# 3.0 Language Enhancements
Description: Can't attend PDC but still want to talk to the C# team? This chat is your chance! Join the C# team to discuss the newly announced C# 3.0 features like extension methods, lambda expressions, type inference, anonymous types and the .NET Language Integrated Query Framework. You've been hearing rumblings about this for a while, now we finally talk in depth about the future of the C# language.
I've seen some people talking and some leaving comments that newly introduced XPathNavigator.SelectSingleNode() method is actually a wrapper around XPathNavigator.Select and so it provides no performance benefits. This is both true and false. It's true that you won't get any performance boost from moving to XPathNavigator.SelectSingleNode() method, because it's really just a wrapper around XPathNavigator.Select() returning first selected node. But that's also false that there is something wrong with it. No performance boost because XPathNavigator.Select() is efficient itself and never selects all nodes, returning instead XPathNodeIterator, which actually selects nodes once its MoveNext() method is called. So there is no perf difference, both are very fast and XPathNavigator.SelectSingleNode() method is mostly just about code elegance and convenience for a coder.
It's surprisingly tricky to get BinHex encoded data out of XmlDocument tree in .NET 1.X. XmlConvert class, which apparently has to support such conversions has a method FromBinHexString(), but weird - it only public for .NET Compact Framework. It's internal for regular .NET Framework. It's obvious that lots of .NET functionality isn't supported in .NET Compact Framework, but this is first time I see anything that .NET CF implements and .NET doesn't. Hmm, and in the forthcoming .NET 2.0 it's the same, do I miss something? Anyway, here is a workaround.
If you thought that some smell of XML in C-omega was amazing, believe me that's nothing. Major XML and .NET integration stories are still ahead of us. Something big is cooking inside the house. Look at these news.
XPathReader is originally developed inside Microsoft and then dropped out as open-source implementation of a pull-based XML parser that supports XPath queries while parsing the XML document. It's basically XmlReader that supports streaming subset of XPath 1.0. Read "The Best of Both Worlds: Combining XPath with the XmlReader" article for more info about XPathReader.
New in this release:
Support for look-ahead in predicates such as "foo[bar='baz']". This is done via internal caching using XmlBookmarkReader. This behaviour can be turned off using XPathReader.LookAheadInPredicates property.
XPathReader.dll is now has a strong name, so it can be called from strongly named assemblies
AllowPartiallyTrustedCallers attribute is applied, so XPathReader.dll can be called by partially trusted callers (e.g. in ASP.NET)
In .NET 2.0 XPathNavigator finally has SelectSingleNode() method! MSXML and XmlDocument (XmlNode actually) have it forever and it's so widely used because it's soooo handy. Obviously despite its name, XPathNavigator.SelectSingleNode() returns not a node, but node equivalent in XPathNavigator's data model - XPathNavigator. And this method is even better than XmlNode's one, because it has overloads accepting compiled XPathExpression, so when running within a loop you don't have to pay XPath compilation price on each iteration. That's another reason to switch completely to XPathNavigator API when processing XML in .NET 2.0.
nxslt 1.6 and nxslt2 Beta1 are available for download. For those not familiar with nxslt: nxslt is free feature-rich .NET XSLT Command Line Utility.
nxslt 1.6 is the next version for the .NET 1.X Frameworks. New features include optionality for source XML or stylesheet, pretty printing, ASCII only escaped output and support for "omit-xml-declaration" attribute of the exsl:document extension element.
nxslt2 Beta1 is the first beta version of the next major nxslt release. nxslt2 uses new XSLT 1.0 processor in the .NET 2.0 Framework - System.Xml.Xsl.XslCompiledTransform class. Hence it requires .NET 2.0 Beta2 (which you can download here) or higher. As a first beta version, nxslt2 Beta1 is quite limited - no support for XInclude, EXSLT, multiple output and embedded stylesheets. As far as I port EXSLT.NET and XInclude.NET to .NET 2.0 I'll update nxslt2.
New Microsoft XSLT Processor (XslCompiledTransform) is a great stuff. Compiles XSLT to MSIL and runs as fast as MSXML4. I'll be writing about it a lot soon. With nxslt2 you can give it a whirl.
I was wrong in my last post. Here is how one can output HTML with XslCompiledTransform when XmlResolver needs to be passed to Transform() method.
using (XmlReader src = XmlReader.Create("../../source.xml"))
{
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("../../style.xslt");
XmlWriter result = XmlWriter.Create(Console.Out, xslt.OutputSettings);
xslt.Transform(src, null, result, new XmlUrlResolver());
}
The key line is emphasized. One just needs to pass XslCompiledTransform's OutputSettings (after XSLT stylesheet is loaded) to XmlWriter.Create() method and then resulting XmlWriter will output transformation results according to <xsl:output> settings in the XSLT stylesheet. Really nice once I get it.
I'm porting nxslt utility to .NET 2.0 with XslCompiledTransform as XSLT processor and I just found out XslCompiledTransform API is really severe broken. I was writing before that the only Transform() method overload that accepts XmlResolver outputs to XmlWriter. So if you want to create HTML and to have some control over document() function resolving (or just provide user credentials), you are out of luck with XslCompiledTransform. Quite common scenario, isn't it? Too bad, XML Team should hire better testers.
What I dislike in System.Xml v2.0 (and v1.X for that matter) is a poor support for push-based XML processing. Somehow it's all about pull - XmlReader, while push - XmlWriter seems to be a second class citizen. For instance one can't populate XML into XPathDocument or XSLT stylesheet into XslCompiledTransform with XmlWriter. One can't deserialize an object from XML if XML is represented as XmlWriter etc. In a nutshell: XML producers in .NET write XML into XmlWriter, while XML consumers read XML from XmlReader. The problem with this mix of pull and push arises when one tries to pipeline a XML producer and a XML consumer, i.e. a component that writes to XmlWriter and another one which reads from XmlReader. Ooops! Think about feeding XML created with XSLT into SqlXml or deserializing an object from an XML modified by XSLT or chaining two XSLT transformations when output from the first one goes as input to the second one or generating XSLT stylesheet on the fly. Most of these problems can't be solved in .NET 2.0 in a streaming fashion and require interim buffering of the whole XML effectively killing scalability and performance. Look here and here. I'm really sorry to see interim buffering with serializing/reparsing involved as an XML pipelining solution in a modern technology like .NET 2.0.
I'm working (again) on the XML Chapter to our upcoming book. The book is all about ASP.NET 2.0, but XML is such an important part of ASP.NET that this chapter gets bigger and bigger. I've been updating it from the original Beta 1 version this last few months and noticed that the namespace qualification for the XmlDataSource is still broken/incomplete as it was last year in September. I talked to a bunch of people at TechEd including a number of very helpful devs and PMs who were very much interested in resolving this issue. However, unfortunately it looks like this'll be one of those features that won't make it into the final, which means one of us will have to write our own.
That's a bummer. I feel a smell of degradation here. When a brand new XML-specific ASP.NET control doesn't support XML namespaces, uses obsoleted XslTransform class and they can't get it fixed during a year - that's really lame. I'm really sorry seeing such stuff coming from Microsoft.
Definitely we need to provide a fixed version.
Excellent articles. Part 3 is expected too according to Alex's site. Yeah, I just found out Alex Homer has a site and even very interesting blog (with no RSS feed and not so frequently updated though). It's http://www.daveandal.net/alshed.asp. Alex, you really need RSS feed on your site!
It's official now - we (XML MVPs) agreed and Dare (as EXSLT.NET project owner) has approved an integration of the EXSLT.NET project into the Mvp.Xml library. All EXSLT.NET project contributors may ask to be added as developers to the Mvp.Xml project. I will be moving code soon, as well as doing some EXSLT.NET development. Current plans are: .NET 2.0 version and support for XSLT 2.0 stylesheet functions. Stay tuned.
XSLT 2.0 -
1. Do we need to support XSLT 2.0 ?
2. What are the most useful features of XSLT 2.0 that you would like to see implemented? (like grouping , support for datetime etc)
3. Do you believe support for the entire 2.0 spec is useful? If yes , why?
A fellow MVP asked if there is a way to dump XML content while reading it from a stream without buffering the whole XML document. Here is a scenario - an XML document being read from a HttpWebResponse stream and needs to be passed as an XmlReader to an XmlSerializer to deserialize it into objects. This works fine in a streaming way - just create an XmlReder over the stream and pass it to an XmlSerializer. But what if incoming XML needs to be logged? Of course then one could go buffer-log-process architecture, effectively killing performance and scalability. Fortunately there is a better way - by extending XmlReader one can make it dumping current node it's positioned at. Here is how.
Altsoft N.V. has announced a relase of the Xml2PDF formatting engine version 2.3, now supporting WordML. Altsoft Xml2PDF is a .NET based formatting engine for converting
various XML-based formats to PDF. It supports XSL-FO, SVG, XHTML,
WordML and
XML+XSLT as an input and generates PDF as an output. The prices are from $49 for the Workstation version to $1599 for the API version. Free evaluation versions are available.
SourceForge has fixed the stat system and now we can analyze Mvp.Xml project statistics. The numbers are good - 8-15K hits/mo and 700-800 downloads/mo, not bad for a 1.0 release.
On behalf of the Mvp.Xml project team our one and the only lawyer - XML MVP Daniel Cazzulino aka kzu has signed a license for Microsoft to use and distribute the Mvp.Xml library. That effectively means Microsoft can (and actually wants to) use and distribute XInclude.NET and the rest Mvp.Xml goodies in their products. Wow, I'm glad XML MVPs could come up with something so valuable than Microsoft decided to license it.
Mvp.Xml project is developed by Microsoft MVPs in XML technologies and XML Web Services worldwide. It is aimed at supplementing .NET framework functionality available through the System.Xml namespace and related namespaces such as System.Web.Services. Mvp.Xml library version 1.0 released at January 2005 includes Common, XInclude.NET and XPointer.NET modules.
Part 1 of my "Indexing XML" article went live at the MSDN XML Dev Center. In this article I discuss various aspects of indexing standalone XML documents - XML IDs, XSLT Keys and introduce IndexingXPathNavigator class, part of the Mvp.Xml library, which enables lazy or eager indexing of any IXPathNavigable XML store (XmlDocument, XPathDocument or XmlDataDocument) thus providing alternative fast way to select nodes directly from the index table and not searhing the XML tree. This allows drastically decrease selection time and improve scalability on preindexed selections.
Here is benchmark results on searching 1000 random orders by order ID from differently sized XML documents using XmlDocument, XPathDocument and IndexingXPathNavigator:
'nuf said.
Any comments are welcome! In the next part of the article I'm focusing on XML indexing aspects of the SQL Server 2005.
Muenchian technique of grouping is de-facto standard way of grouping in XSLT 1.0. It uses keys and is usually very fast, efficient and scalable. There used to be some problems with using Muenchian grouping in .NET though, in particular the speed was in question. To put it another way - .NET implementation of keys and generate-id() function is slow. Reportedly, as per KB article 324478, keys performance has been fixed, though I have no idea if the fix is within .NET 1.1 SP1 (.NET version 1.1.4322.2032). Anyway, writing the article on XML indexing I did some perf testing for XSLT keys and got interesting results I want to share.
I finally finished that article and sent it to the MSDN XML Dev Center. It's two-part article discussing various XML indexing aspects. In the first part I covered techniques for indexing standalone XML documents - XML IDs, XSLT Keys and IndexingXPathNavigator. The next part will be completely focused on XML indexing in forthcoming SQL Server 2005.
Dan Wahlinstarts online video series on using XML APIs in the .NET framework. Watch the first video segment devoted to XmlDocument class here.
This video segment demonstrates some XmlDocument class fundamentals including how the Document Object Model (DOM) works, parsing RSS feeds, filtering with XPath, and editing XML.
It's already 2005 and everybody's aware of SQL injection attacks nowadays. But it's silly to think that this kind of attack is only about SQL, right? SQL injection is just one particular case of a general code injection attack - when somebody too gullible allows user input to become a part of an executable code. So it's always bothers me when I see how often people (even XML geeks) are building XPath expressions concatenating them with user input. Admit it - that's common practice to have something like
which is just a front door open for any evil person, which knows a little bit XPath. And there are many of them just in here, so having selections like above in your production code is most likely a hidden security vulnerability.
I'm working with the 2.0 beta of .NET and it has XQuery 1.0 support - you
are saying that it will not be supported? That sounds rather strange to me -
please explain.
Pieter Reint Siegers Kort
So we better be prepared for a wave of disappointed developers once Beta 2 is out. Blogging on that isn't enough, some official MSDN article is needed. People should be warned ASAP not to waste their time/money on that.
Hey, I've got another idea. XQuery and XSLT2 are surely huge undertakings (we can truly thank W3C for that), but still there is plenty of plain poor .NET devs struggling with limitations of XSLT 1.0 and XPath 1.0. What if Microsoft implements XSLT 1.1 + EXSLT in .NET 2.0, would you like to see it?
Irwin Dolobowsky says we should expect very interesting articles at MSDN XML Dev Center, especially I'm looking forward to this one - "Helena Kupkova will show us how to create bookmarks in XML Streams with the ResetableXmlReader." Hmmm, sweet. AFAIR we've been discussing it with my fellows XML MVPs, but concluded we need to rewrite XmlTextReader substantially to achieve it.
Microsoft XML Team has a team blog now - subscribe here.
Mike Champion nicely wraps up a discussion on the recent changes in thinking on the the next generation of Microsoft XML-related products. Convincing enough. What I still dislike is the lack of a consistency. A subset of XQuery (which is considered as stable enough) is still going to be supported in SQL Server 2005, but not in .NET. Weird, but you know, admit it - SQL Server team just can afford it.
Oh that big news - Michael Champion is now Program Manager for XML Standards in the Microsoft's XML WebData team. Wow, wow, wow - that's the only words I can say. Here is his intro on his new blog (hey, he is a Microsoft employee, so it's http://blogs.msdn.com/mikechampion, not http://weblogs.asp.net/mikechampion, but actually both URLs work). Subscribed.
The focus of my job at MS (as I understand it -- I'm still new!) is to help the WebData team track XML technologies and specifications as they emerge, mature, and are standardized, and to be a source for information needed to decide which specs to support in what timeframes.
I think we can translate that as "my job is to help Microsoft to avoid wasting resources on black hole projects in XML field", such as XmlDocument,XPathDocument,XmlDocument story or cut XQuery support in .NET2.0. Well, that's definitely going to benefit both Microsoft and us - ordinary .NET XML devs.
I still don't see any way to create a XslTransform from a XmlDocument?
That's not the first time I see it actually. The answer of course is - XmlDocument implements IXPathNavigable, so just pass it to Load() method as is. Many developers don't see it, I wonder why?
I'd like to ask - do YOU think XslTransform class provide intuitive enough API (I mean these 5 overloads of Load() and 9 Transform() methods, not including obsolete ones)?
As you can see he decided to embed preprocessing instructions into comments. Too bad. Why? First of all because comments are for comments and reusing a tool for a purpose it wasn't designed for is always bad idea. Second - surprise! XML has native syntax for expressing processing instructions - it's called processing instructions. And third - a much better way (at least comparatively to using comments and PIs) of mixing data with different meaning in XML is called XML namespaces.
Now back to our mundane world. Unfortunately in .NET one cannot embed elements in a proprietary namespace or even plain XML processing instructions into standard sections of config files! So using such poor hacks as embedding data into comments is the only workaround. Too bad. That's just another example of how violating a basic principle called "Allow All XML Syntax" makes your customers to invent poor hacks when they only want to extend your product.
I was doing some catch up reading feeds I'm subscribed and I found this one item that made me feeling some sort of bitter nostalgia. It's right on MSDN TV site, a new episode where Mark Fussel explains new XML features in upcoming .NET 2.0. The episode is dated December 02, but apparently it was filmed long time before. Why? Because more than a half new features Mark is talking about are officially cut and Mark himself has left XML team already.
There was recently an interesting thread in the microsoft.public.dotnet.xml newsgroup on document("") function call in .NET. A guy was porting some app from using MSXML to .NET. Something didn't work... You know these common bitter (and usually completely lame) complaints:
It is strange, this all works just fine using MSXML4 objects instead of XML.NET
I guess between the implementation of MSXML4 and XML.NET they forgot the
purpose of the special case document('').
...
W3C spec or not, it is too bad that XML.NET is intrinsically tied to the
file system. My program has access neither to write nor read from the file
system. I guess I will use MSXML4.
So what's wrong with document("") in .NET comparatively to MSXML?
Just for the record: I updated EXSLT.NET to support for omit-xml-declaration attribute on the exsl:document element. If somebody desperately needs it, it's in the source repository already.
Comega is an experimental language which extends C# with new constructs for relational and semi-structured data access and asynchronous concurrency.
Cw is an extension of C# in two areas:
- A control flow extension for asynchronous wide-area concurrency (formerly known as Polyphonic C#).
- A data type extension for XML and table manipulation (formerly known as Xen and as X#).
The preview download includes Cw command line compiler, Visual Studio .NET 2003 package which extends VS.NET ti support Cw (really nice integration) and lots of samples. Cw supports XML as native data type, so you can write something like
// This class returns the sample bib.xml data as the above Comega objects.
public class BibData
{
public static bib GetData() {
return <bib>
<book year="1994">
<title>TCP/IP Illustrated</title>
<author><last>Stevens</last><first>W.</first></author>
<publisher>Addison-Wesley</publisher>
<price> 65.95</price>
</book>
</bib>;
}
}
And what's more interesting - Cw partially supports XQuery-like constructs natively:
XML Base is a tiny W3C Recommendation, just couple of pages. It facilitates defining base URIs for parts of XML documents via semantically predefined xml:base attribute (similar to that of HTML BASE element). It's XML Core spec, standing in one line with "Namespaces in XML" and XML InfoSet. Published back in 2001. Small, simple, no strings attached or added mind-boggling complexity. Still unfortunately neither MSXML nor System.Xml of .NET support it (Dare Obasanjo wrote once on the reasons and plans to implement it). Instead, XmlResolver is the facility to manipulate with URIs. But while XmlResolvers are powerful technique for resolving URIs, they are procedural facility - one has to write a custom resolver to implement resolving per se, while XML Base is a declarative facility - one just has to add xml:base attribute on some element and that's it, base URI for this element and the subtree is changed. So now that you see how it's useful, here is small how-to introducing amazingly simple way to implement XML Base for .NET.
XmlTextWriter in .NET 1.X only supports indentation of the following node types: DocumentType, Element, Comment, ProcessingInstruction, and CDATA. No attributes. So how to get attributes indented anyway? If you can - wait .NET 2.0 with cool XmlWriterSettings.NewLineOnAttributes, otherwise - here is a hack how to get attributes indented with XmlTextWriter in .NET 1.X.
DonXML writes on viral coding examples in presentations on using XML in .NET:
Joe Fawcett (fellow XML MVP) came across a great example (from the Microsoft.Public.Xml newsgroup) of one of my biggest pet peeves, "We (the community) are doing a very poor job teaching the average developer how to use XML properly in .Net".
I want to draw your attention to a line from the original post:
"So, is it possible to directly modify the xml file instead of using the dataset."
And the first response was:
"you can do it using Data Island"
Why does thing question bug me so much? Because we (the community) have done a very bad job using XML correctly in our articles and presentations.
Yeah, samples are in fact templates, a stuff to copy-n-paste. Keep that om mind while preparing samples for your presentation/article/blog.
Karl Waclawek has announced the first production release of the SAX for .NET library - open source C#/.NET port of the SAX API. It contains API and Expat-based implementation. AElfred-based implementation is expected soon.
The question raised in the microsoft.public.dotnet.xml newsgroup today: "How to retrieve the namespace collection of all the document namespaces for which there is at least one element in the document". The purpose is a validation against different schemas. Well, the most effective way of doing it is during XML document reading phase, not after that. In .NET it means to add a slim layer into XML reading stack (aka SAX filter in Java world). In this layer, which is just custom class extending XmlTextReader, one can have a handler for an element start tag, whose only duty is to collect element's namepace and delegate the real work for the base XmlTextReader. Here is how easy it can be implemented.
public class NamespaceCollectingXmlReader : XmlTextReader
{
private Hashtable namespaces = new Hashtable();
//Add constructors as needed
public NamespaceCollectingXmlReader(string url) : base(url) {}
public Hashtable CollectedNamespaces
{
get { return namespaces; }
}
public override bool Read()
{
bool baseRead = base.Read();
if (base.NodeType == XmlNodeType.Element &&
base.NamespaceURI != "" &&
!namespaces.ContainsKey(base.NamespaceURI))
namespaces.Add(base.NamespaceURI, "");
return baseRead;
}
}
And here is how it can be used to collect namespaces while loading XML into a XmlDocument.
XmlDocument doc = new XmlDocument();
NamespaceCollectingXmlReader ncr = new NamespaceCollectingXmlReader("foo.xml");
doc.Load(ncr);
foreach (object ns in ncr.CollectedNamespaces.Keys)
Console.WriteLine(ns);
While old gray XPath 1.0 supports only DTD-determined IDs, XPointer Framework also supports schema-determined IDs - an element in XML document can be identified by a value of an attribute or even child element, whose type is xs:ID. I've been implementing support for schema-determined IDs for the XPointer.NET/XInclude.NET library (has no online presence currently after gotdotnet's workspace crashed and I moved the code to the mvp-xml.sf.net).
I was using my old hack - custom XmlReader that emulates dummy DOCTYPE to enforce .NET's System.Xml (both XmlDocument and XPathDocument) to use ID info collected from a schema. But you know, as it turned out, that hack is quite limited - System.Xml is only recognizing ID attributes (not elements) and only for globally defined elements! Oh. Looks like that piece of code in System.Xml was designed only for DTDs, where all elements are globally defined and it works for schemas too only due to the unified implementation in System.Xml.Schema. Ok, so XPointer.NET's support for schema-determined IDs is going to be rather limited - only ID typed attributes and only for gloablly defined elements.
In between re-writing and updating the chapters for the beta version of the my book A First Look at ADO.NET and System.Xml V2.0, I found some time to write an article on Building Custom XmlResolvers for MSDN.
It's really good artilce, highly recommended reading for those who still don't feel the magic power of XmlResolvers.
Well, here are some clarifications on how to join XQP project. You have to be registered at the SourceForge.net (here is where you can get new user accout) and then send some free-worded request along with SourceForge user name to me. That's it. Oh, and subscribe to the xqp-development mail list - that's the meeting place (actually you don't have to be XQP team member to subscribe - it's an open list).
Well, I was talking about it a lot and finally decided to stop rambling and start doing. Here is my new toy: XQP project. XQP stands for XML Query Processor of course. It's going (if my karma is good enough) to be free open-source XPath2.0/XQuery1.0/XSLT2.0 engine for the .NET platform. SourceForge team kindly approved the project and now we have everything to deliver a killer application!
The main idea behind XQP is to develop a single core runtime engine based on XPath2.0/XQuery1.0 algebra and then to provide XPath 2.0, XQuery 1.0 and XSLT 2.0 compilers for that engine. It's not something brand new of course. Saxon implements both XSLT 2.0, XPath 1.0 and XQuery 1.0 with a single engine. Microsoft went even further ineventing Common Query Runtime (CQR) and common intermediate format (QIL) and implementing its bits in Whidbey as System.Xml.Query. I believe that's a mainstream design pattern, very obvious considering the XPath/XQuery intimacy and XQuery/XSLT functional overlap.
There are some issues I'd like to be clear.
What for? Why not to wait .NET 2.0?
Well, it was announced that System.Xml v2.0 won't support neither XSLT 2.0 nor XPath 2.0. Being XSLT and .NET aficionado I can't imagine the situation when Java has XSLT 2.0 and .NET doesn't. If Microsoft can't deliver it - we can do it.
What's wrong with Saxon.NET?
Well, nothing wrong, cool project. I just don't believe in effective porting of any big system. Saxon is too tied to Java. And after all porting is so boooooring, while I enjoy to develop :)
Why new project?
I considered starting XQP as part of Mvp-Xml project or even Mono, but realized that due to experimental nature of the project I want to rule the it by myself.
Isn't it too huge project?
Well, I'm not afraid of it. I was participating in developing two XSLT 1.0 processors (a commercial one and an open-source one) and being Apache committer I was watching closely how the Xalan is cooking. There is nothing scary in implementing XPath or XSLT, all standard techniques like building optimizing compilers apply, after all it's just another programming language to implement, probably the most interesting task for a programmer.
Needless to say, everybody interested is invited to participate. We are currently in the team gathering and initial planning stage. And by the way, we are receiveing donations. If you can't help us developing, but want to support the project - you can donate some money to the XQP project.
Well, XInclude.NET workspace at GotDotNet seems to be severely broken. I've sent a solid dozen of requests to fix it and now they even don't answer. Ok, moving the project to sf.net, specifically to the Mvp-Xml project. I'm adding XInclude.NET v1.2 sources to the CVS right now. After some setup I will be able finally to deliver new release, aligned with April 2004 XInclude CR. Stay tuned. And after that I'm going to pack nxslt.exe with latest EXSLT.NET and XInclude.NET and release it too (there are some minor new features too).
As it turned out unfortunatley I introduced nasty bug into date:day-name(), date:day-abbreviation() and date:month-abbreviation() functions while testing EXSLT.NET 1.1 before the release. Saturday and December never appeared :( Thanks to Chris Bayes for prompt bug report. Hence - EXSLT.NET 1.1.1 release. Please update.
So I'm in a critic mood today... I recently found out that XInclude.NET workspace is down for at least a month. Not surprisingly the feedback on the "Combining XML Documents with XInclude" article was so low - all the article links to XInclude.NET: homepage, message board and bug tracker are dead. Moreover and what's worse I can't get access to the XInclude.NET source code for at least a week! Holy cow! Looks like I was too optimistic about GotDotNet Workspaces.
Needless to say I decided to move XInclude.NET project out of there. It needs more reliable home, sorry. It's official now - XInclude.NET will be incorporated into Mvp-Xml project at SourceForge. It's a real pain to move stable project, but I have no choice.
Here we go again - I'm pleased to announce EXSLT.NET 1.1 release. It's ready for download. The blurb goes here:
EXSLT.NET library is community-developed free open-source implementation
of the EXSLT extensions to XSLT for the .NET platform. EXSLT.NET fully
implements the following EXSLT modules: Dates and Times, Common, Math,
Random, Regular Expressions, Sets and Strings. In addition EXSLT.NET
library provides proprietary set of useful extension functions.
Support for time zone in date-time functions has been implemented.
Multithreading issue with ExsltTransform class
has been fixed. Now ExsltTransform class is
thread-safe for Transform() method
calls just like the System.Xml.Xsl.XslTransform
class.
Lots of minor bugs has been fixed. See EXSLT.NET
bug tracker
for more info.
We switched to Visual Studio .NET 2003, so building of the project has been
greatly simplified.
Complete suite of NUnit tests for each extension function has been implemented
(ExsltTest project).
Any comments and bug reports are welcome!
PS. Well, despite Dimitre's and my light side's objections I implemented dyn2:evaluate(). I know, I'm evil...
Lots of activity in the EXSLT.NET project recently. We implemented more functions such as random:random-sequence(), str:encode-uri() and str:decode-uri(). Lots of bugs have been fixed. Support for time zone in date-time functions has been implemented. We switched to Visual Studio .NET 2003 so simplifying our custom build process. Currently I'm writing unit tests for each function (and we have something about 80 of functions already!). After I finish it up I'm going to update documentation and release EXSLT.NET 1.2, so stay tuned.
Btw, I was thinking about adding some simple function for dynamic XPath evaluation. Of course we have no chance to implement dyn:evaluate() as extension function in .NET, but we could provide some simplified proprietary version, e.g.
object dyn2:evaluate(node-set, string)
where first argument is context node and second one is XPath expression (as string) to evaluate. This would allow to build and evaluate XPath expressions on the fly, the feature XSLT 1.0 doesn't and XSLT 2.0 won't support. It's gonna be limited of course - no variables, no keys etc., but anyway. Would you like to have such function in EXSLT.NET?
PS. I know, it smells provocatively, but it should attract more users to EXSLT.NET library.
My latest article "Building Practical Solutions with EXSLT.NET" has been published at the MSDN XML Developer Center. This is an overview of the EXSLT.NET library and its extension functions from the practical XPath/XSLT programming point of view. Basically I wanted to show how to use EXSLT.NET functionality in practice, so I went through all EXSLT modules and showed how these functions can solve frequent XSLT problems such as multistep transformations, date and time manipulations, doing math, parsing and matching using regexp, calculating sets difference, intersection or getting distinct nodes, padding, splitting, tokenizing, replacing and other advanced string manipulations etc etc etc.
Comments are welcome!
EXSLT.NET is sort of answer to "No XSLT 2.0 in .NET???" question and as such it unexpectedly becomes more and more important. In recent Online Chat with Microsoft XML Team, Arpan Desai, Microsoft PM on XPath, XSLT, and XQuery stack said: "Although EXSLT.NET is not officially supported by Microsoft, we will endeavor to make sure it works ;)". Another question was about moving EXSLT.NET into the core System.Xml to make it available out of box, more performant and what's more important - to eliminate full trust security requirement. They said they are considering it. Meanwhile there are some bugs and improvements on EXSLT.NET I wanted to work on. For reasons beyond my control I've got some free time this week, so...
It's obvious, but I didn't realize that till recently - Chris Lovett's SgmlReader doesn't supprot namespaces. Why? SgmlReader is SGML reader in the first place and you know, there is no namespaces in SGML. So whenever you want to cheat and process malformed XML with SgmlReader - beware of namespaces.
Sometimes some of us want to narrow encoding of an output XML document, while to preserve data fidelity. E.g. you transform some XML source with arbitrary Unicode text into another format and you need the resulting XML document to be ASCII encoded (don't ask me why). Here is fast and simple solution for that problem.
Daniel implemented SubtreeXPathNavigator I was talking about. That's a way cool stuff, I really like it. Now I'm not sure about XmlNodeNavigator - do we need it in Mvp.Xml library or we better remove it to not confuse users with different forms of the same navigator?
I feel a bit guilty about Mvp.Xml project and the June plans I announced. Sorry, I just did nothing. I'm way busy with another unexpected stuff I just had to finish first.
Say you've got a DataSet and you want to save its data as XML. DataSet.WriteXml() method does it perfectly well. But what if you need saved XML to have a reference to an XSLT stylesheet - xml-stylesheet processing instruction, such as <?xml-stylesheet type="text/xsl" href="foo.xsl"?> ? Of course you can load saved XML into XmlDocument, add the PI and then save it back, but don't you remember Jan Gray's Performance Pledge we took:
"I promise I will not ship slow code. Speed is a feature I care about. Every day I will pay attention to the performance of my code. I will regularly and methodically measure its speed and size. I will learn, build, or buy the tools I need to do this. It's my responsibility."
Come on, forget about XmlDocument. Think about perf and don't be lazy to look for a performance-oriented solution in the first place. Here is one simple streaming solution to the problem - small customized XmlWriter, which adds the PI on the fly during XML writing.
Split Complex Transformations into Several Stages
You can incrementally transform an XML document by using multiple XSLT style sheets to generate the final required output. This process is referred to as pipelining and is particularly beneficial for complex transformations over large XML documents.
More Information
For more information about how to split complex transformations into several stages, see Microsoft Knowledge Base article 320847, "HOW TO: Pipeline XSLT Transformations in .NET Applications," at http://support.microsoft.com/default.aspx?scid=kb;en-us;320847.
Sounds great, but referred KB article 320847 is actually a huge green fly in the ointment - it still suggests using temporary MemoryStream to pipeline XSL transformations! What a crap, didn't they hear about new XPathDocument(xslt.Transform(doc, args))??? I've reported that glitch more than a year ago and I've been told they are working to fix it. Still not fixed. Ok, probably that's time to use my MVP connections to get it finally fixed.
Another one I've stumbled upon:
XPathNavigator. The XPathNavigator abstract base class provides random read - only access to data through XPath queries over any data store. Data stores include the XmlDocument, DataSet, and XmlDataDocument classes.
Somehow "the XML data store" XPathDocument is forgotten once again :(
Here is another piece of a must reading - "Chapter 9 - Improving XML Performance" of the "Improving .NET Application Performance and Scalability" guide from the Microsoft Pattern and Practices group. Here are the objectives : Optimize XML processing design, Parse XML documents efficiently, Validate XML documents efficiently, Optimize your XML Path Language (XPath) queries, Write efficient XSL Transformations (XSLT). Wow, amazingly good paper.
Daniel writes about transforming a portion of XML document using XPathNavigatorReader. That's a common bad surprise for MSXML-experienced people, who used to fooNode.transformNode() method, where only fooNode and its descendants are visible in XSLT. In .NET that's different - no matter which DOM node you pass to XslTransform.Transform() method, the whole XmlDocument tree is visisble in XSLT. MSDN suggests to load the portion of XML you want to transform into a temporary XmlDocument and pass it to the transformation. Too bad.
What Daniel proposes instead is to load the portion of XML to be transformed into a temporary XPathDocument instead of XmlDocument. Well, that's better, but what I'd like to ask is why do one need any temporary tree at all? It's a piece of cake to write custom XPathNavigator that would limit navigation only to a specified subtree. I did that once with XmlNodeNavigator, which represents XPathNavigator over XmlNode. Less than 10Kb of code. It's ideal solution to transform only a subtree of an XmlDocument. No temporary objects, just lightweight code between XmlDocument and XSLT that limits navigation not higher that specified node.
That's perfect for XmlDocument. For XPathDocument we need another one. Or better we need generic XPathNavigatorNavigator (did we really go nuts with these XML beasts?). XPathNavigatorNavigator should allow to navigate over given XPathNavigator, but should not allow to move it outside the subtree. Comments?
XPathNavigatorReader and XmlNodeNavigator are both parts of Mvp.Xml project.
May be I missed something, but looks like Travis Bright is converting Apache Xerces XML parser to .NET. I wonder what for?
Aha, he's PM for the Java Language Conversion Assistant (JLCA). That explains. Btw, one day I stumbled across CSS parsing in .NET. Java version of the product I've been working on used W3C's Flute CSS parser and I didn't manage to find any .NET CSS parsers. So I just created J# project in Visual Studio, imported Flute's java sources, compiled them into dll with no any hitch and that's it - it just worked.
Daniel says he's disappointed in SAX.NET project I was writing about. Unlike lazy me, he downloaded it and inspected implementation. Well, I mostly agree with him. This piece of direct thoughtless porting of complex convolute Java API to .NET looks weird and kinda unnatural. "namespace System.Xml.Sax {" isn't what I like to see altogether. Too many conventions are broken. Too bad to taste good. Well, I hope are they will improve things. At least todays conversation in xml-dev gives some hopes to think that.
Attributes2 and friends are traces of long SAX API evolution. SAX was created in a vacuum, there wasn't standard Java XML API at that time, while SAX.NET is going to live in .NET land and must be System.Xml-friendly. The question is is it feasible at all?
A long and convolute discussion about security problems of using EXSLT.NET in ASP.NET took place in EXSLT.NET message board. Here I'd like to formulate some short summary.
Hey, SAX for .NET topic is becoming hot. I was aware of one implementation (to be unveiled really soon), being developed by my fellow MVP/XmlInsider, but apparently there is another one, by Karl Waclawek. Here is what he writes in xml-dev mail list:
What's mostly untested is the helper classes.
The rest has already undergone usability testing
in the form of implementing an adapter for Expat.
Karl is known as seasoned XML developer, I particularly know him as one of Expat XML parser devs. Expat is a great XML parser, originally developed by James Clark (enough said). It's written in C and is magically fast one. At my work we use it as base XML parser for all XML tools we write for mainframes, yeah, that's really good one.
I'm glad to see growing appreciation of the .NET in broad XML community and I do believe community-developed implementation of SAX for .NET would be great step forward this way. The very fact of emerging SAX for .NET projects doesn't mean XmlReader's pull-based XML parsing paradigm is bad or disappoints some of us. Both pull and push parsing paradigms have pros and contras and having both available in .NET is a good sign of the technology maturity.
Here I go again with another experimental creature from my XML Bestiary: IndexingXPathNavigator. This one was inspired by Mark Fussell's "Indexing XML, XML ids and a better GetElementByID method on the XmlDocument class". I've been experimenting with Mark's extended XmlDocument, played a bit with XPathDocument and "idkey()" extension function Mark was talking about. Finally I came to a conclusion that 1)XPath is the way to go (that' not the first time I say it, right? :) and thus what should be extended is XPathNavigator; 2)no need to reinvent the wheel as XSLT's keys is proved excellent stuff. That is what IndexingXPathNavigator is - XPathNavigator, augmented with XSLT keys functionality: it supports declaring keys, lazy or eager indexing and retriving indexed nodes via key() function all as per familiar and proved XSLT semantics.
Somehow it happened that one of the most commonly used XmlReader usage patterns ignores NameTable.
That's really unfortunate! Everybody, including Microsofties, MVPs and of course zillions of users blindly follow it, carelessly slowing down XmlReader's parsing speed.
XML.com has published good article "Using XML Catalogs with JAXP". XML Catalogs are successors of SGML Catalogs and in simple words it's a system for defining resolving of resource identifiers (URIs or Public Identifiers) in XML. If you are .NET minded - it's about having XML document (called catalog), where you declaratively define how URIs in DOCTYP, xsi:schemaLocation, xsl:include/xsl:import/document() etc should be resolved by XmlResolver. So instead of writing you own XmlResolver you declare that "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd" should be resolved as "C:/dtds/xhtml1-strict.dtd" in catalog file and get things done.
I'm going to implement EXSLT Random module for EXSLT.NET lib. It contains the only extension function: number+ random:random-sequence(number?, number?)
The function returns a sequence of random numbers between 0 and 1 (as text nodes obviously). The first argument is number or random numbers to generate (1 by default) and the second one is a seed.
The problem is that .NET's Random class accepts seed as int, while in XPath numbers are double. So simple (I hope) question: how do you think it should be converted?
We were planning to add support for xml:base to the core XML parser as part of implementing XInclude but given that that it recently went from being a W3C candidate recommendation to going back to being a W3C working draft (partly due to a number of the architectural issues raised by Murata Makoto) the future of the spec is currently uncertain so we've backed off on our implementation.
Yeah, XInclude makes its tangled way to the Recommendation status really slowly. It's been CR for a long time and even there were some slips about PR, but then it's been backed off to WD soapbox again. These days XInclude is ready to climb up again. Many architectural issues have been fixed, syntax and semantics have been modified with respect to the Web architecture, there are enough full implementations for all major platforms (.NET, Java, C). And here is what Jonathan Marsh writes today in www-xml-xinclude-comments@w3.org maillist:
We believe this is resolution completes our resolution of outstanding
issues on XInclude, and we plan to release a new CR draft soon.
By the way, I wrote an article about XInclude and XInclude.NET and hope it'll be published soon.
Meantime some of you guys sent me logos for the XInclude.NET logo contest. Thanks! I'm going to arrange a page with a poll to see public opinions.
At last some good news. Streaming subset of XInclude I was talking about gets blessing from the W3C XML Core WG. Here is what Jonathan Marsh (MSFT, editor of XInclude) writes:
It appears to be impossible to improve streamability without removing
functionality from XInclude. The WG decided instead to bless a kind of
"streamable subset" by adding text along these lines:
_______
The abscense of a value for the href attribute, either by the appearance
of href="" or by the absence of the href attribute, represents a case
which may be incompatible with certain implementation strategies. For
instance, an XInclude processor might not have a textual representation
of the source infoset to include as parse="text", or it may be unable to
access another part of the document using parse="xml" and an xpointer
because of streamability concerns. An implementation may choose to treat
any or all absences of a value for the href attribute as resource
errors. Implementors should document the conditions under which such
resource errors occur.
_______
New version of XInclude spec is going to be published soon. As they are slightly changing syntax again (removing accept-charset attribute), I think it will be Working Draft again.
Well, I know I stink on graphics. Yesterday I tried to develop a logo for the XInclude.NET project and here is what I ended up. The idea was about Lego and intergration or parts into a round thing, whatever.
I'd like to hear what do you guys think about this logo?
I'm personally not really satisfied with it and I doubt I can make it better, so let's have a logo contest. You send me your logo variants (find my email in top right corner of this page), I put them to some page and after some time we vote for a winner logo.
Prize? Well, XInclude.NET project doesn't have sponsors, so we can't afford anything more valuable than "The logo design by" line in every bit of XInclude.NET documentation and of course a pile of eternal gratitude.
When your hard disk dies Monday morning, that's nice week start. Low type tasks on recovering your data, sources, reinstalling and configuring all the stuff you cannot work without... Refreshing.
Basically I've recovered already. Surprisingly I cannot now install Office 2003, it says "You've got McAffee VirusScan Enterprise installed, Office 2003 Pro cannot be installed on the same machine with that crap." Hmmmm... Anybody seen that? I failed to google any workarounds.
I've updated my XML Bestiary as a consequence of users and my own feedback. First of all I renamed WritableXPathNavigator to SerializableXPathNavigator. That's much less confusing name IMO. Beside that I unified all distributions (the same namespace, project structure etc). More beasts to come soon, I've got several growing up in an incubator.
It's definitely love-to-steaming-strikes-back day today. Here is another sample of how streaming XML processing approach fails.
The only XInlcude feature still not implemented in XInlcude.NET project is intra-document references. And basically I have no idea how to implement it in .NET pull environment (as well as Elliotte Rusty Harold has no idea how to implement it in his SAX-based implementation). What's the problem?
Meanwhile I managed to create simple dummy online demo of ForwardXPathNavigator (XPathNavigator implementation over XmlReader) I was talking about. Here it is.
XSE is not about querying with an specific expression language/format (i.e. XPath or SXPath). XSE is just a mechanism for encapsulating state machines checking for matches against a given expression. What the expression looks like depends on the factory that creates the strategy.
Therefore, the factories I showed (i.e. my RootedPath and RelativePath) are only encapsulating code generation for different FSMs, based on an expression language that fits a need. Therefore, I could even create a factory implementing SXPath and still remain in Xml Streaming Events land.
The XSE idea is to provide a callback metaphor to XML parsing, instead of the pull-model of the XmlReader. In fact, it's a sort of evolution over SAX, in that at the same time it offers both worlds: pull model directly from the XseReader, events-based for your registered handlers.
Now that's finally clear to me. And the approach starts to delight me. Really, really not bad. I need to dig around it before I can say some more.
Actually Oleg is closer and yet farther from the truth than he realizes. Although
I wrote about a hypothetical ForwardOnlyXPathNavigator in my article entitled Can
One Size Fit All? for XML Journal my planned article which should show up
when the MSDN XML Developer Center launches in a month or so won't be using it. Instead
it will be based on an XPathReader that is very similar to the one used in BizTalk
2004, in fact it was written by the same guy. The XPathReader works similarly
to Daniel Cazzulino's XseReader but uses the XPath subset described in Arpan Desai's Introduction
to Sequential XPath paper instead of adding proprietary extensions to XPath
as Daniel's does.
Danielwrites about performant (and inevitably streaming) XML processing, introducing XSEReader (aka Xml Streaming Events Reader). While he didn't publish the implementation itself yet, but only teasing with samples of its usage, I think I get the idea. Basically I know what he's talking about. I've been playing with such beasts, making all kinds of mistakes and finally I came up with a solution, which I think is good, but I didn't publish it yet. Why? Because I'm tired to publish spoilers :) It's based on "ForwardOnlyXPathNavigator" aka XPathNavigator over XmlReader, Dare is going to write about in MSDN XML Dev Center and I wait till that's published.
Dare has been talking recently about the disconnects developers may feel once they make the shift from tree based (XmlDocument) to cursor based (XPathNavigator) model. My personal XML learning curve has started with DOM (I remember those long convolute ugly DOM navigational programs I wrote back in Y2K), then I fell in love with SAX and only then I became XmlReader and XPathNavigator fan. But despite the fact I'm probably not an average developer (as I spend most of my time dealing exclusively with XML) I can feel the disconnect too. DOM is kinda ground zero for many of us and not feeling it underfoot is a bit like flying in zero-gravity. Hurts at first, but fun and cool once you get used to it. I think that's not by accident DOM implemenation in .NET has been named XmlDocument, that reflected some basic attitude at that time, although some of us believe now DOMDocument was a better name.
Anyway, here is my small humble contribution to XPathNavigator appreciation - SerializableXPathNavigator. It's really small wrapper around XPathNavigator, which extends it adding InnerXml/OuterXml properties and WriteTo()/WriteContentTo() methods. That's unfortunate omission XPathNavigator doesn't have such fuctionality in .NET 1.0/1.1 and this fact adds some degree to the discronnect devs feel, because devs do like OuterXml and use it frequently. It's fixed in .NET 2.0, but till then I propose this implementation.
Here is local copy and here is GotDotNet's copy. Free and open source of course.
Usage pattern:
XPathDocument doc = new XPathDocument("books.xml");
XPathNavigator nav = doc.CreateNavigator();
XPathNodeIterator ni = nav.Select("/catalog/book[title='Creepy Crawlies']");
ni.MoveNext();
SerializableXPathNavigator snav = new SerializableXPathNavigator(ni.Current);
Console.WriteLine(snav.OuterXml);
Console.WriteLine(snav.InnerXml);
Couple of details - SerializableXPathNavigator is XPathNavigator itself, which wraps another XPathNavigator and exposes the following additional members: OuterXml - gets the XML markup representing the current node and all its child nodes. InnerXml - gets the XML markup representing only the child nodes of the current node. WriteTo(XmlWriter) - saves the current node to the specified XmlWriter. WriteContentTo(XmlWriter) - saves all the child nodes of the current node to the specified XmlWriter.
Implementation details - see sources.
Hope you can find it useful. As usual I appreciate any comments/bugs/critics.
Did you know XslTransform class allows custom XmlResolver to return not only Stream (it's only what default XmlResolver implementation - XmlUrlResolver class supports), but also XPathNavigator! Sounds like undeservedly undocumented feature. What it gives us? Really efficient advanced XML resolving scenarios such as just mentioned recently on asp.net XML forum - getting access to XML fragments from within XSLT. Or looking up for cached in-memory XML documents. Or constructing XML documents on the fly for XSLT, e.g. via accessing SQL Server database from within XSLT stylesheet and processing the result. Well, part of it could be done also with XSLT parameters and extension functions, but XmlResolver is more powerful, flexible and elegant approach.
Here is a sample XmlFragmentResolver, which allows XSLT to get access to external XML fragments (XML fragment aka external general parsed entity is well-formed XML with more than one root elements):
public class XmlFragmentResolver : XmlUrlResolver
{
override public object GetEntity(Uri absoluteUri, string role,
Type ofObjectToReturn)
{
using (FileStream fs = File.OpenRead(absoluteUri.AbsolutePath))
{
XmlTextReader r = new XmlTextReader(fs,
XmlNodeType.Element, null);
XPathDocument doc = new XPathDocument(r);
return doc.CreateNavigator();
}
}
}
Don't forget to pass its instance to Transform() method (in .NET 1.0 - set it to XslTransform.XmlResolver property):
xslt.Transform(doc, null, Console.Out, new XmlFragmentResolver());
And here is how then you can access XML fragments from within XSLT:
Note, that instead you can load XML fragment and pass it as a parameter, but then you should know statically in advance all XML fragments/documents XSLT would ever require. XmlResolver approach allows XSLT to take over and access external documents or fragments really dynamically, e.g. when a file name cannot be known prior to the transformation.
Have you noted this thread in microsoft.public.dotnet.xml newsgroup? A guy was trying to get list of unique values from XML document of 46000 records. Using Muenchian grouping method. For MSXML4 it took 20 seconds, while in .NET 1.0 and 1.1 it effectively hung.
Well, as all we know Muenchian method works deadly slowly in .NET unfortunately. MSXML4 optimizes generate-id($node1) = generate-id($node2) expression by making direct comparison of nodes instead of generating and comparing ids. .NET implementation isn't so sophisticated. Emerging .NET 1.1 sp1 is going to make it faster, but what's today's solution?
Somehow many believe it's impossible to get OuterXml/InnerXml out of XPathNavigator, but in fact it's merely one-screen-of-code class. And by the way, in System.Xml v2 XPathDocument2 class does have such properties already.
So I've written a small class, which exposes this omitted functionality. It's lightweight wrapper around XPathNavigator, which adds two more properties - OuterXml and InnerXml along with two more methods - WriteTo(XmlWriter) and WriteContentTo(XmlWriter).
Now the question is how to name such class. All names I came up - WritableXPathNavigator, SerializableXPathNavigator or even XPathNavigatorWriter sound too confusing. I'm asking for community help here, any ideas, please guys.
In the beginning Microsoft created the Microsoft.XMLDOM, known today as Msxml2.DOMDocument. And people like(d) it much. Then .NET happened and people were given XmlReader, XmlWriter, XmlDocument, XPathDocument, XPathNavigator and XmlDataDocument. Surprisingly most of us stuck to XmlDocument for no-matter-which scenario. Now we've been notified the Gods decided to kill XmlDocument and glorify XPathDocument instead. Be prepared...
Seriously, why XmlDocument is so overused? I think there are several reasons, from psychological to usability-related ones.
For anybody with MSXML experience DOM is the obvious choice. DOM was the only data store in MSXML and the API. It's my understanding that MSXML SAX is almost only used by memory-anxious nerds. No surprise anybody with MSXML background coming to .NET takes XmlDocument with no any doubts. Such situation just cannot be changed quickly.
XmlDocument is editable, XPathDocument is readonly. Unbeatable now, but System.Xml v2.0 gonna change it.
XmlDocument API is simpler and more natural WRT MSXML background than XPathDocument's one in many common usage scenarios such as selecting a string value, especially it strikes the eyes when namespaces involved:
XmlNamespaceManager nsmgr = new XmlNamespaceManager(doc.NameTable);
nsmgr.AddNamespace("foo", "http://foo.com");
string val = doc.SelectSingleNode("/foo:bar/text()", nsmgr).Value;
vs
XPathNavigator nav = doc.CreateNavigator();
XPathExpression expr = nav.Compile("/foo:bar/text()");
XmlNamespaceManager nsmgr = new XmlNamespaceManager(nav.NameTable);
nsmgr.AddNamespace("foo", "http://foo.com");
expr.SetContext(nsmgr);
XPathNodeIterator ni = nav.Select(expr);
ni.MoveNext();
string val = ni.Current.Value;
XmlDocument exposes nodes, XPathDocument - cursor based API (but uses XPathNode's internally). Developers somehow like being able to select a node from document, dunno, may be it gives some secure non-virtual feelings to them?
XmlDocument is closer to XML syntax level than XPathDocument. Developers like to work with XML declarations, entities, CDATA and OuterXml. They feel good when data store reflects XML syntax they see in Notepad. Don't ask me why.
Developers don't care about perf. Sometimes they complain instead.
Well, we can do nothing with first and the last issues. System.Xml v2 will fix 2nd issue. Additionally XPathDocument will be improved with XSD types support, changes tracking, ability to validate, to reflect relational data via XmlAdapter etc. I'm sure they will make API more simple for ordinar developer too. In fact, System.Xml v2 gonna rock! So the only issue to cope with is community-wide DOM habit. How to kill it? I believe only with improving alternative APIs, leaving it out of XQuery-related future mainstream and evangelizing-evangelizing-evangelizing... Last task should be taken by XmlInsiders.
Btw, did you know that "dom" word means "home" in Russian?
The D00D: Oh LOL, XSLT. I wondered where the conditionals were, and read more
Sam: Does this wok with custom XSD . I have custom read more
Anonymous: Check this: http://msdn.microsoft.com/en-us/library/system.collections.sortedlist.contains.aspx Towards the middle of the page you read more
Buzzer: As for the & ampersand issue, simply call HTTPUtility.HTMLEncode in read more
Ethyl Kruk: Have you read any of Cem Kaner's books? He is read more
steve oak: yes, tried and it works! you know what? I even read more
Tim: @Martin Kool Thanks for the registry-hint read more
nokola: Hi Oleg, This is indeed very interesting finding! I tried read more
Anonymous: The total of the first line is 1, the total read more
lior: the url are broken is the code still free source read more

 Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets.
Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets. I updated
I updated 
 So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas").
So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas"). .gif)
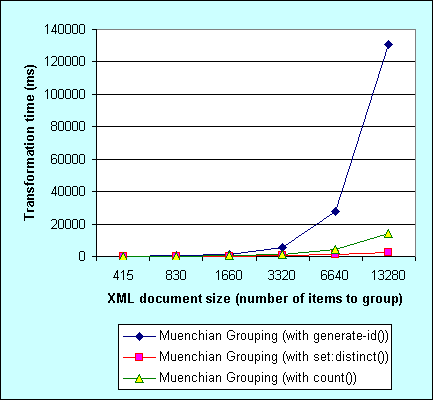
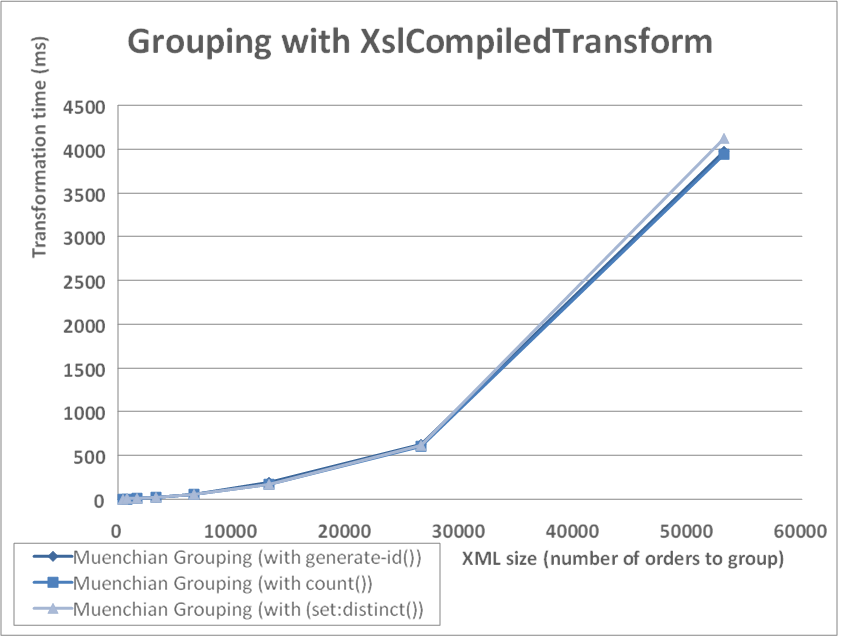
 Ok, I'm back. I have updated
Ok, I'm back. I have updated 

 Well, I know I stink on graphics. Yesterday I tried to develop a logo for the
Well, I know I stink on graphics. Yesterday I tried to develop a logo for the
Recent Comments