Obviously Microsoft forgot about XInclude when they were shipping Visual Studio, so when you edit your XML and use XInclude you get no intellisense. It's easy to fix though. Just get this XInclude schema (standard XInclude schema improved a bit by Laurens Holst) and drop it into
{Visual Studio install drive}:\Program Files\Microsoft Visual Studio 9.0\Xml\Schemas
A very little known fact is that Visual Studio 2008 does support real XSLT intellisense - not a static XSLT schema-based one, but real dynamic intellisense enabling autocompletion of template names, modes, parameter/variable names, attribute set names, namespace prefixes etc.
For some obscure reason it is off by default and obviously completely undocumented. I'll show you how to turn it on. But before - a little teaser.
1. When you about to call a named template you are presented with a list of all named templates in your stylesheet. My favorite feature. Finally you don't have to remember all your template names:
2. In XSLT template parameters are passed by name, so when you call a template and want to pass parameters you actually have to know exactly what parameter names are. And you better know them for sure, because if you make a mistake you pass a parameter with wrong name you get no error or even warning. XSLT 1.0 specification allows such nonsense. That's why template parameter name autocompletion is a real time saver:
3. You can pass parameters when applying templates too. Obviously due to dynamic XSLT processing model it's hard to know in advance which template will be matched at run time, so it's hard to suggest list of parameter names. In this version of XSLT intellisense we get list of all parameters used in all templates, filtered by mode. I believe XML Tools could optimize it a bit by filtering the list when it's clear from the context which template will be matched. Anyway, very useful:
4. Autocompletion of template modes is also extremely useful. Make mistake in mode name and you can spend hours in debugger trying to figure out why your template isn't matched, because again this is not an error or even something wrong according to XSLT spec. That's why this is so cool:
5. Finally a couple of useful namespace prefix autocompletions. exclude-result-prefixes now becomes easier:
and <xsl:namespace-alias> (mostly used for generating XSLT using XSLT):
6. If you use <xsl:attribute-set> elements, you will be happy to see this one:
These are autocompletions I'm currently aware of. There might be more - it's currently completely undocumented and I probably the first one writing about this feature. For example key names are collected too, but I haven't found where they are used. If you happen to discover another XSLT autocompletion, report it in comments section please.
And finally how to turn this awesomeness on:
Yes, regedit. Create String value called "XsltIntellisense" under "HKEY_CURRENT_USER\Software\Microsoft\VisualStudio\9.0\XmlEditor" key. "True"/"False" are valid values.
If you don't want to mess with registry, wait till tomorrow. I'm going to release IronXSLT v0.3, which will turn XSLT intellisense on for you while installing.
But I'm not happy with this solution. There must be more elegant way. The problem just smells FXSL. Hopefully Dimitre can show me how FXSL can do it with beauty and style.
We are working on yet another language migration tool and faced once again Java source code generation problem. Unfortunately Java doesn't have anything similar to .NET's CodeDOM, so we had to build own own Java generator. This time our development platform is XSLT 2.0. Yes, we are converting COOL:Gen (obscure 4GL model-based language) to Java using XSLT 2.0.
XSLT 2.0 rocks by the way. This is first time I write production code in XSLT 2.0 and this is amazing experience. Suddenly all is so easy, everything is possible, no hassle. Despite poor authoring support (Eclipse XSLT editor sucks, while Visual Studio 2008 with XSLT 2.0 schema is ok, but cannot run Saxon), lack of debugger and Saxon quirks I had a blast practicing XSLT 2.0 for real.
At first I started generating Java beans simple way: output mode="text" and producing Java sources as text. Obviously it sucked big way. I spent a week and got it done, but with way too cumbersome and fragile code. Generating code and simultaneously coping with Java syntax and formatting is hard. Additional layer of indirection was needed desperately.
One of smart guys I work with came with a simple but brilliant idea. Vladimir took Java 6 ANTLR grammar and converted it to XML Schema. Then he developed a generic serializer (also in XSLT 2.0 of course) that is able to convert XML document confirming to Java XML schema (he called it JXOM - Java XML Object Model) into nicely formatted and optimized decent Java 6 source code.
Then I rebuilt my Java bean generator using JXOM instead in just one day. Building Java as XML is so much easier and cleaner, I believe it's even easier than using System.CodeDom in .NET (obviously CodeDom can do more than just generate C# or VB sources).
Anyway, anybody interested in Java generation - check out JXOM. This is really easy way to generate Java 9even Java 6.0) using XSLT. It's freely available and it just works. Here are more links:
Microsoft XML Tools team has released XSLT profiler addin for Visual Studio 2008. I've heard about this tool and even did a little testing long time ago (apparently it's very hard to release anything in Microsoft).
First thing you need to know about Microsoft XSLT profiler - it requires Visual Studio 2008 Team System edition with the Performance Tools feature installed. That actually sounds a bit steep for just XSLT profiler, but it starts to make sense once you realize this tool is just a thin wrapper around the F1 profiler (which only ships with Visual Studio Team System SKU).
Once installed, it adds "Profile XSLT" command (visible only in XSLT context, i.e. when active document is XSLT stylesheet) to the XML menu:
Before you see profiling results you should recall that XSLT in .NET starting with 2.0 is compiled to MSIL:
As you can see, an XSLT stylesheet is being compiled into a class and each template becomes a method with cool special name like <xsl:template match="book">. That was smart. And yes, MSIL is completely ok with such kind of method names. Beside template-mehods the generated class contains other auxiliary stuff. So don't be surprised with XSLT profiling results:
I'd say there is too much clutter in this form. I'd like to see only XSLT relevant info, but as you can understand now, it's the the results of profiling compiled assembly and XSLT part is here only because smart compilation tricks.
Still extremely useful tool. A must for anybody writing XSLT in Visual Studio. Besides Summary View there are: Call Tree View, Modules View, Caller/Callee, Functions, Marks and Processes Views. You can find more info about profiling report details at http://code.msdn.microsoft.com/xsltprofiler.
I'd be happy to see next version. With all clutter removed, more XSLT focused, linked to XSLT source (seems like currently there is no way to get back to template source from report), may be with some smart visualizations (what about coloring XSLT source view to indicate the hot spots?). Oh well, provided it took XML Tools team so long to ship this tool I better try to implement all these ideas myself in Iron XSLT (stay tuned, it's not dead as I'm back).
When you create new XSLT stylesheet in Visual Studio via project (Add/New Item) or globally (File/New/File aka Ctrl+N), you start with template content. This template is changing in every new Visual Studio version, probably because every new generation of developers working on XSLT tools in Visual Studio have different vision about what you should start with.
Visual Studio 2005 has two different templates for new XSLT stylesheet (!). When you create it via project you get the same as above empty stylesheet template. But if you go via Ctrl+N you get this fancy template:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:exsl="http://exslt.org/common"
exclude-result-prefixes="exsl">
<xsl:template match="/">
<html>
<body>
<!--
This is an XSLT template file. Fill in this area with the
XSL elements which will transform your XML to XHTML.
-->
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Yes, believe it or not, but some Microsoft developers were sure you should start with EXSLT namespace declaration in your stylesheet. The fact is that .NET 2.0 introduced partial native support for EXSLT, but it was never documented. It's still hidden portability gem.
No more EXSLT, back to basics - proprietary nonportable MSXSL namespace by default. This is sad.
Beside this weird proprietary comeback it's interesting that this new template contains identity transformation rule. This cumbersome looking <xsl:template> is the base of data transformation filtering. It processes every single node in source document recursively and outputs it as is. By adding more template rules you can override base behavior to add, remove or modify particular nodes. Very powerful technique. This is smart choice for new file template.
Creating a working stylesheet may seem like an end in itself, but once it’s written you may want it to run faster or you may not be sure that the output is correct (And if you are sure, how sure are you?).
Profilers, unit test frameworks, and other tools of conventional programming are similarly available for XSLT but are not widely used. This presentation surveys the available tools for ensuring the quality of your XSLT.
It is possible to extend the power of XSLT using JavaScript embedded into the XSL file. Therefore any web application that allows the user to upload their own XSL file will be vulnerable to Cross Site Scripting attacks.
Well, that's not exactly true, at least on Microsoft platform.
Microsoft tackled this issue long time ago. Both MSXML 6.0 and .NET (since 2.0) don't allow script extensions and document() function in XSLT by default. One has to enable them explicitly. So the truth is s bit different: any web application that allows the user to upload their own XSL file and explicitly allows executing embedded scripts will be vulnerable to Cross Site Scripting attacks.
While we at this, here is some refresher for this important to know topic:
Untrusted style sheets are those that come from an untrustworthy domain. There is no way to eliminate denial of service (DoS) attacks when processing untrusted style sheets or untrusted documents without removing necessary functionality. If denial of service is a concern, do not accept untrusted style sheets or untrusted documents for transformation.
Cross-Site Attacks
It is not safe to compile and execute an untrusted style sheet within a trusted page (such as a page from your local hard drive). The style sheet may contain the document() function or xsl:include / xsl:import statements, which are capable of loading trusted files and sending them back to the untrusted domain.
XSLT Scripts Are Prohibited by Default
The DOM supports XSLT transformations via calls to the transformNode method and transformNodeToObject method. XSLT supports scripting inside style sheets using the <msxsl:script> element. This allows custom functions to be used in an XSLT transformation. In MSXML 6.0 this feature is disabled by default. If you require scripting in your XSLT transformations, you can enable the feature by setting the AllowXsltScript Property to true.
To allow XSLT scripting (JScript):
doc.setProperty("AllowXsltScript", true);
To disallow XSLT scripting:
doc.setProperty("AllowXsltScript", false);
Internet Explorer uses MSXML 3.0 by default, so when using the MIME viewer to transform scripts, Internet Explorer's security settings are used.
However, if you use MSXML 6.0 via script in Internet Explorer to execute transformations, when the AllowXsltScript property is set to false scripting is disabled no matter what Internet Explorer's settings are. When AllowXsltScript is set to true, Internet Explorer's security settings are used for executing.
The XSLT document Function Is Disallowed by Default
The DOM supports XSLT transformations via calls to the transformNode and transformNodeToObject methods. The XSLT document function provides a way to retrieve other XML resources from within the XSLT style sheet beyond the initial data provided by the input stream. In MSXML 6.0 this feature is disabled by default. If you must use the document function in your XSLT transformations, you can enable the feature by setting the AllowDocumentFunction property to true.
The following is the JScript code to allow the document function:
doc.setProperty("AllowDocumentFunction", true);
To disallow the document function:
doc.setProperty("AllowDocumentFunction", false);
If you enable the document function, you should be aware that the document function runs with the same security settings as the style sheet. If your style sheet is running in a trusted security context, then all files loaded using the document function will run in the same security context. For example, if scripts are allowed in the main style sheet, they will be allowed in all the included and imported files. You should not load untrusted documents via the document function.
Loading External Files Is Prohibited by Default
External files loaded via xsl:include or xsl:import are allowed and processed by default in MSXML 4.0 and 5.0 for backward compatibility. In MSXML 6.0, external files are not processed by default – they must be explicitly enabled by the developer.
If you are using MSXML 6.0 and all of your XSLT style sheets and XML documents come from a secure site, you can allow external schemas by setting the resolveExternals property to true. If you are using MSXML 4.0 or 5.0 and your XSLT style sheets and XML documents do not come from a secure site, you can operate in a safer mode by setting resolveExternals to false.
The XslCompiledTransform class supports the xsl:import or xsl:include elements by default. The XslCompiledTransform class disables support for the document() function by default. The XsltSettings class is used to enable the document() function.
The Load and Transform methods include overloads that take an XmlResolver object as one of its arguments. If an XmlResolver is not specified, a default XmlUrlResolver with no credentials is used.
You can control how external resources are accessed by doing one of the following:
Restrict the resources that the XSLT process can access by using an XmlSecureResolver object.
Do not allow the XSLT process open any external resources by passing in null to the XmlResolver argument.
Script Blocks
The XslCompiledTransform class does not support script blocks by default. Script blocks are enabled using the XsltSettings class. XSLT scripting should be enabled only if you require script support and you are working in a fully trusted environment.
Extension Objects
Extension objects add programming capabilities to XSLT transformations. This feature is enabled by default. If extension objects are passed to the Transform method, they are used in the XSLT transformation.
"Debug" page in XSLT Library project properties, which has Startup stylesheet dropdown list
"Set as StartUp Stylesheet" context menu item for XSLT stylesheets
"Start Debugging(F5)/Start Without Debugging(Ctrl+F5)" commands support - runs startup stylesheet
My goal was to make F5/Ctrl+F5 working intuitively right - when you work on XSLT Library project F5 should run project with debugger and Ctrl+F5 - without. When you have more that one stylesheet it's nice time saving feature, not to mention that start debugging command finally starts debugger as it should.
But what to run? So I introduced a notion of a startup XSLT stylesheet in a project. It's kinda like startup object in C# projects, but currently only affects debugging within Visual Studio. You mark your startup stylesheet either via project properties (Debug tab):
or via new context menu item I added to XSLT stylesheets:
Once you have startup stylesheet in XSLT Library project you can start it as you usually start project with or without debugging:
I also spent unbelievable amount of time trying to make startup stylesheet bolded in Solution Explorer. It still doesn't work on project load...
Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets.
Now short documentation about running compiled XSLT stylesheets.
Let's say you have a stylesheet called mytransform.xsl. First you compile it using nxsltc:
nxsltc mytransform.xsl /out:mytransform.dll
The result is mytransform.dll, containing mytransform class.
-c option says you want to run compiled stylesheet. Instead of XSLT stylesheet file name you pass compiled stylesheet class name (fully qualified if it has a namespace). And you need to specify dll file, where compiled stylesheet can be found.
Of course if you can afford assume things you can make it shorter. If dll is named after stylesheet and can be found in the current directory, you can omit it:
nxslt3 document.xml -c mytransform
Alternatively if dll contains single compiled stylesheet you can specify dll and omit stylesheet:
nxslt3 document.xml -c -af mytransform.dll
If you happens to compile your stylesheets into a strongly named dll:
nxsltc mytransform.xsl /keyfile:d:\keys\test.snk
and then installed it into the GAC, you run it by specifying full or partial dll name after -an option:
And finally. nxslt3 is a free feature-rich .NET 3.5 XSLT command line utility and NAnt/MSBuild task which uses .NET XSLT processor - XslCompiledTransform class and supports XML Base, XInclude, XPointer, EXSLT, compiled stylesheets, embedded stylesheets, processing instruction, multioutput, custom URI resolving, custom extension functions, pretty printing, XHTML output, XSLT 2.0-like character maps and more.
nxslt3.exe/NxsltTask are free tools under BSD license. Download here.
I updated nxsltc - XSLT compiler for .NET 3.5 tool one more time. I added /version:<x.x.x.x> and /keyfile:<file> options. Former is used to specify resulting DLL version and latter - to sign it with a strong name.
D:\>nxsltc.exe /?
XSLT Compiler version 1.0beta2 for .NET 3.5
(c) 2007 Oleg Tkachenko, http://www.xmllab.net
Usage: nxsltc [options]
where possible options include:
/out: Specifies the output file name
/debug[+|-] Emit debugging information
/nowarn Disable all warnings
/namespace: Specifies namespace for compiled stylesheets
/version: Specifies assembly version
/keyfile: Specifies strong name key file
/help Display this usage message (Short form: /?)
/nologo Do not display compiler copyright banner
I also updated nxsltc.exe (well, just rebuilt it using Visual Studio 2008 Beta2).
nXSLTC is an experimental XSLT to MSIL compiler for the forthcoming .NET 3.5. nXSLTC compiles one or more XSLT stylesheets into DLL. Compiled stylesheets then can be used for transforming XML documents using XslCompiledTransform class.
What's the probability of having two car accidents in one month? It must be high enough. Just a month after the first one some asshole hit me and run away. I wonder if it's a bad luck or actually a good luck? Sure, my own car is totaled and a company car doesn't look good either, but hey, I didn't get even a scratch, so I believe I'm a lucky guy.
Ok, back to work. I uploaded version 2.3 of the nxslt2.exe/NxsltTask tool. It's probably the last version for .NET 2.0. Anyway, here is what's new:
nxslt.exe options files (@file option) - useful when your command line gets too long.
XHTML output mode (-xhtml option) - this approach in action.
XSLT 2.0-like character maps (-cm option) - just like in XSLT 2.0, but in a proprietary namespace. I have to blog about this feature.
nxslt and NxsltTask are now debuggable - as it turned out when round-tripping assemblies with ildasm/ilasm there is still a solution to keep them debuggable.
resolving XInclude for XSLT stylesheets is now off by default - because usually nobody needs it and it breaks Docbooks stylesheets.
-xslxi option to turn XInclude for XSLT stylesheets on - if you still want it.
fixed several bugs preventing running Docbook stylesheets - XslCompiledTransfrom + DTD in imported stylesheets and documents loaded via document() function + custom XmlReaders= nightmare.
Oh, just in case: nxslt2 is a free feature-rich .NET 2.0 XSLT command line utility and NAnt/MSBuild task which uses .NET 2.0 XSLT processor - XslCompiledTransform class and supports XML Base, XInclude, XPointer, EXSLT, embedded stylesheets, processing instruction, multioutput, custom URI resolving, custom extension functions, pretty printing, XHTML output, XSLT 2.0-like character maps and more.
It's known that .NET XSLT engine - XslCompiledTransform natively supports two EXSLT extension functions - exsl:node-set() and exsl:object-type(). Not that it's widely known (msdn still says nothing about it), but lots of people are using this handy feature. The main benefit is that using EXSLT's version of node-set() function allows complex XSLT stylesheets (and I guess 80% of complex stylesheets can't live without xxx:node-set() function) to be portable between .NET, Java and libxslt.
Now, let's admit this fact is very little known. I've seen even advanced XSLT developers still using annoying techniques like switching "http://exslt.org/common" and "urn:schemas-microsoft-com:xslt" namespaces or awkward xsl:choose "function-available('exslt:node-set')" blocks. That's wrong.
These days you don't need any special handling for EXSLT exsl:node-set() function in your server-side oriented XSLT stylesheets. Just use it. .NET, Java and libxslt all support it.
I think (.NET and MSXML)-only msxsl:node-set() function should be avoided. Unless you are targeting browsers (in which case you need this trick).
I found it useful to insert EXSLT common namespace declaration into Visual Studio templates for XSLT files. It works as a reminder and is just handy. Here is how you can do it. Open XSLT templates for "Add new item" and "New File" commands:
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\ItemTemplatesCache\CSharp\1033\XSLTFile.zip\XSLTFile.xslt
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\ItemTemplatesCache\VisualBasic\1033\XSLTFile.zip\XSLTFile.xslt
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\NewFileItems\xsltfile.xslt
and add xmlns:exsl="http://exslt.org/common" and exclude-result-prefixes="exsl" to the xsl:stylesheet element:
Producing XHTML using XSLT 1.0 processor is tough (no wonder - XSLT 1.0 is so old - it was published even before XHTML 1.0). While XHTML is just XML, XHTML spec defines a set of very specific formatting rules called "HTML Compatibility Guidelines". The goal is to facilitate rendering of XHTML by HTML browsers (such as Internet Explorer :).
The guidelines say for instance that elements with non-empty content model (such as <p>) must never be serialized in minimized form (<p />), while elements with empty content model (such as <br>) must never be serialized in full form (<br></br>).
While XML doesn't care about such nonsense, HTML browsers might be confused and so XHTML generation should be smart enough. And XSLT 1.0 processors can only output text, HTML or XML (XSLT 2.0 processors can also do XHTML). That's why generating XHTML using XSLT 1.0 processor is tough.
I implemented one simple solution to the problem in the Mvp.Xml library 2.3. Here is a sample that says it all:
XSLT stylesheet:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="yes"
doctype-system="http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
doctype-public="-//W3C//DTD XHTML 1.0 Transitional//EN"/>
<xsl:template match="/">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title/>
</head>
<body>
<p>Para element must have end tag even if empty:</p>
<p/>
<p>These elements must not have end tags:</p>
<p>
<br></br>
<hr></hr>
<img src="foo.jpg" alt="bar"></img>
</p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
The code:
using System;
using System.Xml.XPath;
using System.IO;
using Mvp.Xml.Common.Xsl;
class Program
{
static void Main(string[] args)
{
XPathDocument doc = new XPathDocument(
new StringReader(""));
MvpXslTransform xslt = new MvpXslTransform();
xslt.Load("../../XSLTFile1.xslt");
xslt.EnforceXHTMLOutput = true;
xslt.Transform(new XmlInput(doc), null,
new XmlOutput(Console.Out));
}
}
The result:
<?xml version="1.0" encoding="DOS-862"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title></title>
</head>
<body>
<p>Para element must have end tag even if empty:</p>
<p></p>
<p>These elements must not have end tags:</p>
<p>
<br />
<hr />
<img src="foo.jpg" alt="bar" />
</p>
</body>
</html>
If for some weird reason you don't want to use MvpXslTransform class, you can stay with XslCompiledTransform and just output via XhtmlWriter class:
using System;
using System.Xml.XPath;
using System.Xml.Xsl;
using System.Xml;
using System.IO;
using Mvp.Xml.Common;
class Program
{
static void Main(string[] args)
{
XPathDocument doc = new XPathDocument(
new StringReader(""));
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("../../XSLTFile1.xslt");
xslt.Transform(doc, null,
new XhtmlWriter(
XmlWriter.Create(Console.Out, xslt.OutputSettings)));
}
}
Saxon, famous XSLT 2.0 and XQuery processor, supports XInclude since version 8.9. But in Java version only! When I first heard about it I thought "I have good XInclude implementation for .NET in Mvp.Xml library, let's check out if Saxon on .NET works with XInclude.NET". I did some testing only to find out that they didn't play well together.
Turned out Saxon (or JAXP port to .NET, don't remember) relies on somewhat rarely used in .NET XmlReader.GetAttribute(int) method (yes, accessing attribute by index), and XIncludingReader had a bug in this method.
Finally I fixed it and so XIncludingReader from recently released Mvp.Xml library v2.3 works fine with Saxon on .NET.
Here is a little sample how to process XML Inclusions in source XML document before XSLT transformation.
using System;
using Saxon.Api;
using Mvp.Xml.XInclude;
class Program
{
static void Main(string[] args)
{
Processor proc = new Processor();
XdmNode doc = proc.NewDocumentBuilder().Build(
new XIncludingReader("d:/test/document.xml"));
XsltExecutable xslt = proc.NewXsltCompiler().Compile(
new Uri("d:/test/foo.xsl"));
XsltTransformer trans = xslt.Load();
trans.InitialContextNode = doc;
Serializer ser = new Serializer();
ser.SetOutputStream(Console.OpenStandardOutput());
trans.Run(ser);
}
}
I released version 2.3 of the Mvp.Xml Library, which is part of the Mvp.Xml Project developed by Microsoft MVPs in XML technologies worldwide. It is aimed at supplementing .NET framework XML processing functionality. Mvp.Xml Library provides .NET implementations of the EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes and tools making XML programming in .NET platform easier, more productive and effective.
This is another minor release of the Mvp.Xml Library for .NET 2.0. Version 2.3 fixes lots of bugs and introduces some new features. Most important new features include:
XHTML output mode for the MvpXslTransform class
XSLT2-like output character mapping for the MvpXslTransform class
XmlWrappingReader and XmlWrappingWriter to simplify creating of custom XmlReader or XmlWriter
XIncludingReader now implements IXmlLineInfo interface
MvpXslTransform.AddExsltExtensionObjects() method allows to add EXSLT extension functions to your XsltArgumentList instance
XIncludingReader.Encoding property
New Mvp.Xml Library API documentation site generated using Sandcastle/DocProject, hosted at http://www.xmllab.net/mvpxml
Most important bugs fixed:
XIncludingReader now works well with Saxon.NET, XmlSerializer, DataSet and others
Library DLL is now debuggable
No more XmlValidatingReader and XmlTextReader used
Microsoft XML Team posted a series of screencasts unveiling some new features in Visual Studio Orcas 2008. Short ones, but to the point, without blablahblah. I particularly like XML Editor ability to generate stub XML document from XML schema in just one tab click. Oh, and XSLT debugging is getting better and better. Data breakpoints is a great feature.
Ok, done with sweet part. Black hat on. XSLT debugger still must be run using separate obscure button, called "Debug XSLT", which even has no keyboard shortcut. Hitting F5 will obviously start debugging C# or whatever actual project is. That sucks.
Every debugging menu item works for XSLT debugger, except well, "Start Debugger". I made this mistake zillion times - working on XSLT, want to debug, hit F5, getting C# debugger. Oh, wait, no I meant this button, where is it? That's wasted time. But come on, you are in C# project, that's why F5 starts C# debugger.
My solution to the problem is dedicated XSLT project type for Visual Studio I'm building in the IronXSLT. Separating is good here. The whole project is XSLT-centric, including of course F5 button. In XSLT project F5 will naturally start XSLT debugger.
Another painful point. Derek says his favorite XML Editor feature is "Go to definition":
One of my favorite 'hidden' features is goto-definition. Position the cursor on an element in a document with an associated schema, and F12 will jump you to the part of the schema that governs that element. I occasionally get some very complex customer schemas. F12 can also be used to navigate with-in a schema, from an element declaration to the declaration of it's type, or to the base type declaration. When the schema spans megabytes and multiple files, this is invaluable.
Call me a freak, but I hate "Go to definition" feature in Visual Studio XML Editor. Not because I think going to the definition is bad idea, but because it fools me too many times. It's useful feature when editing XML, but terrible joke when editing XSLT. And 80% of time spent in XML Editor I'm editing XSLT. Huge XSLT stylesheet, call to some template: <xsl:call-template name="go-find-me-template"/>. I want to see the template. Click on "go-find-me-template", F12 - Boom - XSD definition for xsl:template element. That sucks.
I mean it's not fully done. XSLT Editor must override "Go to definition" command and provide meaningful implementation. Currently it's wrong. Nobody wants to see XSD schema for XSLT. It's like when hitting F12 on a variable in C# code being shown C# grammar rule.
Again, I'm going to fix it in the IronXSLT. Not sure if I can override default "Go to definition" command, but at least I can provide my own, which will actually be useful in XSLT.
I found this gem in David Carlisle's blog. Smart Javascript trick allows to mask msxsl:node-set() extension function as exsl:node-set() and so you can easily write crossbrowser XSLT stylesheets using exsl:node-set() functionality. Opera 9, Internet Explorer 6-7 and Firefox 3 are covered, but sadly Firefox 2 is out of the game. Julian Reschke came with a nice trick using Javascript expressiveness:
That reminds me old days of mine when I came with a similar trick for EXSLT extension functions implemented in C# (for EXSLT.NET project). Except that C# isn't so dynamic as Javascript so I had to escape to renaming method names in MSIL bytecode. That trick still drives EXSLT.NET (now module of the Mvp.Xml library).
By the way just to remind you - .NET (XslCompiledTransform) supports exsl:node-set() function natively.
Yes, I'm trying to change the way you work with XSLT in Microsoft Visual Studio. It must be a pleasure to develop and rocket fast at runtime. Yes, Visual Studio already supports editing, running and even debugging XSLT, but it's still a painfully limited support. So I'm started building IronXSLT - Visual Studio plugin aimed to provide total integration of the XSLT language in Visual Studio IDE.
Current list of planned and already implemented IronXSLT features includes:
XSLT Library Project (Visual Studio project type for compiling XSLT into DLL)
XSLT Refactorings
Multiple XSLT engines
XSLT Profiler
Extensive library of XSLT code snippets
XPath Intellisense
Visual XSLT builder
XSLT2XLinq and XLinq2XSLT converters
IronXSLT version 0.1 implements first point.
IronXSLT supports only forthcoming Microsoft Visual Studio version, codenamed "Orcas", which is about to be released later this year. That also makes IronXSLT ship date.
IronXSLT is free for personal and commercial usage, but not open source currently.
I was reading Scott's post on Reflector Addins and had this idea... Now (well, not now but in the next .NET version - Orcas) that XSLT can be compiled into dll, it must be time to think about XSLT decompiler (and appropriate Reflector addin of course). I believe that must be feasible. Would it be useful for you?
I mean pre-XProc XSLT pipeline - just when you need to transform an XML document by a sequence of XSLT stylesheets - output from the first transformation goes as input to the second one and so on. This is useful technique helping dramatically simplify your complex multi-stage XSLT stylesheets. Unfortunately there is no simple way to perform such task effectively in .NET 2.0. Here I show you how Mvp.Xml project comes to the rescue.
Note: there is old crappy Microsoft KB article 320847 suggesting pipelining XSLT via byte buffer, Bleh!, don't do this.
The problem is that while the most efficient (fastest, taking less memory) XML store for doing XSLT transformations in .NET 2.0 is still old good XPathDocument (not surprisingly specially designed and optimized for XPath and XSLT), there is no way to take XSLT output directly to XPathDocument. XslCompiledTransform doesn't provide XmlReader over its output. It can do XmWriter, but XPathDocument cannot be loaded via XmlWriter (this is likely to be fixed in post Orcas .NET version).
The problem was solved though. Sergey Dubinets from the Microsoft XML Team contributed his excellent XslReader implementation, which provides an efficient way to read XSLT results as XmlReader. I later wrapped it all into MvpXslTransform class, which extends capabilities of the XslCompiledTransform class by adding support for transforming into XmlReader , vast collection of EXSLT extension functions, multiple outputs and transforming of IXPathNavigable along with XmlResolver.
Here is finally code sample that says it all:
using System;
using System.Xml.Xsl;
using System.Xml.XPath;
using System.Xml;
using Mvp.Xml.Common.Xsl;
class Program
{
public static void Main()
{
MvpXslTransform xslt1 = new MvpXslTransform();
xslt1.Load("../../XSLTFile1.xslt");
MvpXslTransform xslt2 = new MvpXslTransform();
xslt2.Load("../../XSLTFile2.xslt");
XPathDocument doc = new XPathDocument("../../source.xml");
XmlReader stage1Output = xslt1.Transform(new XmlInput(doc), null);
xslt2.Transform(new XmlInput(stage1Output), null,
new XmlOutput(Console.Out));
}
}
So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas"). Get it here (free open-source). I probably shouldn't be building this tool, but I have my reasons.
Why not? As a matter of fact, Mike Champion has announced back in February that Microsoft will provide XSLTC.exe tool in the next Visual Studio "Orcas", but apparently it didn't make it into March CTP, at least I didn't manage to find it. It probably will be included into the next drop.
Why yes? First - this is the best way of learning new technology and then - I plan to build something bigger, which Microsoft won't be doing - XSLT project for Visual Studio, so I need this code anyway.
Ok, so nXSLT.exe. It's a command line XSLT compiler for .NET 3.5. It compiles one or more XSLT stylesheets into DLL. These compiled stylesheets can be later used to transform XML documents using XslCompiledTransform class.
Kzu, being also one of the Mvp.Xml project users has this wild feature request. He wants to reverse XInclude resolving back. The scenario is simple: you load XML document A.xml containing XML Inclusions for B.xml and C.xml, XInclude processor resolves XML Inclusions, you get a combined document, edit it and then you save it back to A.xml, B.xml and C.xml. So if you have modified an element coming from B.xml then B.xml gets updated on save.
Well, that sounds like a reasonable feature, but how it can be done? To be able to reverse XML Inclusions one has to know exactly where each node came from, i.e. to preserve original context in a post-XInclude document.
Inclusion preserving context information is also known as a transclusion. Visual transclusion is traditionally associated with XLink instead and technically speaking XInclude has nothing to do with it. From XInclude 1.0 spec:
1.1 Relationship to XLink
XInclude differs from the linking features described in the [XML Linking Language], specifically links with the attribute value show="embed". Such links provide a media-type independent syntax for indicating that a resource is to be embedded graphically within the display of the document. XLink does not specify a specific processing model, but simply facilitates the detection of links and recognition of associated metadata by a higher level application.
XInclude, on the other hand, specifies a media-type specific (XML into XML) transformation. It defines a specific processing model for merging information sets. XInclude processing occurs at a low level, often by a generic XInclude processor which makes the resulting information set available to higher level applications.
Simple information item inclusion as described in this specification differs from transclusion, which preserves contextual information such as style.
So in an ideal world I'd just suggest Kzu to use XLink instead of XInclude for transclusions. The problem though is that XLink is basically dead for years now and unfortunately there is none XLink implementations for .NET. That's why XInclude.
The inclusion history of each top-level included item is recorded in the extension property include history. The include history property is a list of element information items, representing the xi:include elements for recursive levels of inclusion. If an include history property already appears on a top-level included item, the xi:include element information item is prepended to the list. If no include history property exists, then this property is added with the single value of the xi:include element information item.
So basically for each node in a post-XInclude document it's possible to figure out it's original context:
If a node has no ancestors having "include history" property, it belongs to the including XML document.
If there is such ancestor node then "include history" can be used to find out where this node came from.
Of course that only sounds simple. For starters Mvp.Xml XInclude implementation doesn't support "include history". XIncludingReader keeps internal stack of xi:include elements though and can expose it in some way. Then "include history" should be preserved in XML Infoset implementation, e.g. XML DOM - XmlDocument. That means XIncludeXmlDocument class extending XmlDocument. And then "include history" should be used when saving XmlDocument. Still sounds feasible.
Problems. What about partial inclusions with XPointer? if a node was included from inside a document its full XPath must be preserved in "include history" so it can be saved back at exactly the same location. Still feasible.
Editing combined document opens Pandora's box. New nodes - where they should be saved. Deleting nodes - how to detect? Moving nodes around. Multiple inclusions of the same node - how to resolve conflicts?
Well, still it sounds mostly feasible to implement transclusion on top of XInclude.
Any comments? Does anybody think it might be useful?
Welcome to the new XForms.org Community Web Portal, a central clearinghouse for articles and resources on XForms based technologies. This site is intended as one gateway into the XForms community (the other primary one being http://www.xforms.org itself), and provides the static side of the XForms.org community.
openxml.biz announced the availability of the OpenXML Writer - open source text editor for creating OpenXML WordprocessingML files (.docx). Supported features include "text formatting options like bold, italic, underline, font color, font name , font size, paragraph justification and text indentation. Basic editing functions like cutting, copying, pasting and spell check are also provided".
Here is a problem: XSLT 1.0 sucks on generating XML character or entity references. I mean getting &foo; out of XSLT 1.0 is hard. The only ugly solution is disable-output-escaping hack, but it's a) optional, b)doesn't work in all scenarios (only when XSLT engine controls output serialization into bytes and c) works only on text nodes. Latter is real showstopper - you can't generate character or entity reference in attribute using XSLT 1.0. But now that we have XSLT 2.0, which is oh so better. What's XSLT 2.0 solution for the problem?
Everybody who speaks English can communicate with anybody else who also happens to speak English. You can talk, you can mail, you can read books written in English by others.
Sure you can invent your own language, no big deal. You can even make somebody learn it and then talk to her.
But most prefer easy way and speak XML, I mean English.
[Well, technically speaking majority on this planet prefer Chinese anyway].
But why oh why would anyone embed their XSLT in the assembly? The point is to separate design from logic. Even if the xslt does a non-presentational transform it _will_ be a pain to have to redeploy the assembly instead of just the stylesheet. Or not?
Our users have made it very clear that they want an XSLT 2.0 implementation once the Recommendation is complete. A team of XSLT experts is now in place to do this, the same people who have been working on the XSLT enhancements that will be shipped in the forthcoming "Orcas" release of Visual Studio / .NET 3.5. Orcas development work is winding down in advance of Beta releases over the next several months, so there is no possibility of shipping XSLT 2.0 in Orcas. The XSLT team will, however, be putting out Community Technology Previews (CTP) with the XSLT 2 functionality and appropriate tooling as the implementation matures. The eventual release date and ship vehicles (e.g. a future version of .NET or a standalone release over the Web) have not been determined, and depend on technical progress, customer demand, and other currently unknowable factors.
Good. Very good news for those who invested in XSLT. XSLT 2.0 is sooooo much better,so much easier to develop with language. And I'm sure this new Microsoft XSLT 2.0 engine is gonna rock.
2007-01-22: The World Wide Web Consortium has published eight new standards in the XML family for data mining, document transformation, and enterprise computing from Web services to databases. "Over 1,000 comments from developers helped ensure a resilient and implementable set of database technologies," said Jim Melton (Oracle). XSLT transforms documents into different markup or formats. XML Query can perform searches, queries and joins over collections of documents. Using XPath expressions, XSLT 2 and XQuery can operate on XML documents, XML databases, relational databases, search engines and object repositories.
Wow. Congrats to everybody envolved. Lots of reading now.
And the winners are Dave Pawson and Leon Bambrick. Both of them are getting Visual Studio 2005 Team Suite with 1 year MSDN Premium Subscription. Congrats guys! I hope it will help with your work and so benefit the community.
Sorry to the rest - I only have 2 cards to give away...
Now, Dave and Leon please contact meASAP. I'm on vacation in heavily raining Seattle and tomorrow will be on 2 days flight back to Israel, while your offer is expired Dec 31.
XslCompiledTransform implements the following useful MSXML extension functions. But what if you need to use them in XPath-only context - when evaluating XPath queries using XPathNavigator?
HtmlAgilityPack is an open source project on CodePlex. It provides standard DOM APIs and XPath navigation -- even when the HTML is not well-formed!
Well, DOM and XPath over malformed HTML isn't new idea. I've been using XPath when screenscraping HTML for years - it seems to me way more reliable method that regular expressions. All you need in .NET is to read HTML as XML using wonderful SgmlReader from Chris Lovett. SgmlReader is an XmlReader API over any SGML document such as HTML.
But what I don't get is why would anyone (but browser vendors) want to implement DOM and XPath over HTML as is? Reimplementing not-so-simple XML specs over malformed source instead of making it wellformed and using standard API? May be I'm not agile anough but I don't think that's a good idea. I prefer standard proven XML API.
Here is Josh's sample that validates that Microsoft's home page lists Windows as the first item in the navigation sidebar implemented using SgmlReader:
SgmlReader r = new SgmlReader();
r.Href = "http://www.microsoft.com";
XmlDocument doc = new XmlDocument();
doc.Load(r);
//pick the first <li> element in navigation section
XmlNode firstNavItemNode =
doc.SelectSingleNode("//div[@id='Nav']//li");
//validate the first list item in the Nav element says "Windows"
Debug.Assert(firstNavItemNode.InnerText == "Windows");
I completely forgot that I still have one Visual Studio 2005 Team Suite with MSDN Premium Subscription gift card to give away. And it expires 12/31! Oh boy, what do I do now??? So for the next 2 weeks I'll be holding the "The Coolest XML Project Contest".
Better late than never - forthcoming Java 6 (currently Release Candidate) will include StAX, pull based streaming XML API. .NET has pull based XML parser (XmlReader) from the very beginning and Microsoft was arguing .NET's XmlReader is better than SAX since at least 2002. No, I'm not saying Java catches .NET up with one more feature, no. I'm just glad I wil be able to parse XML using the same model and very similar API on both platforms.
I was building NAnt and MSBuild tasks for the nxslt tool last two days and the bottom line of my experience is "previously I thought NAnt sucks, but now I know NAnt is brilliant and it's MSBuild who sucks really big way".
My complaints about NAnt were that
NAnt being .NET Ant clone somehow has different license - while Java Ant is under Apache License, NAnt is under GPL. Now that Sun GPL-ed Java it might sound no big deal, but I personally was in a situation when a project manager said no we won't use NAnt because it's GPL and we don't want such a component in our big bucks product.
NAnt core dlls aren't signed. That in turn means I can't sign my assembly and so can't put it into GAC. Weird.
Really minor ones as I realize now. Besides - NAnt is brilliant. While MSBuild appears to be more rigid and limited. Apparently it's impossible to create MSBuild task that uses something more than just attributes. I mean in NAnt I have this:
MSBuild doesn't seem to be supporting such kind of tasks. MSBuild task only can have attributes, not children elements. It can have references to some global entities defined at the project level, such as properties and task items. At first I thought task items seem good candidates for holding XSLT parameters, because task items can have arbitrary metadata. And that's exactly how the Xslt task from the MSBuild Community Tasks Project passes XSLT parameters:
Parameters here get attached to an XSLT file item definition, which seems to be reasonable until you realize that you might want to run the same stylesheet with different parameters?
And what worse - above is actually plain wrong because it only provides "name=value" for a parameter, while in XSLT a parameter name is QName, i.e. XSLT parameter is a "{namespace URI}localname=value". And item metadata happens to be limited only to plain name=value. Metadata element can't have attributes or namespace prefix or be in a namespace... It's clear that MSBuild task item is a bad place to define XSLT parameters for my task.
Last option I tried and on which I settled down is defining XSLT task parameters as global MSBuild project properties. Thanks God at least properties can have arbitrary XML substructure! Here is how it looks:
And here is how you implement it: create a string property "Parameters" in your task class. At the task execution time this property will receive <XsltParameters>element content (as a string!). Parse it with XmlReader and you are done. Beware - it's XML fragment, so parse it as such (ConformanceLevel.Fragment).
Two problems with this approach - it makes me to define parameters globally, not locally (as in NAnt) - hence if I have several transformations in one project I should carefully watch out which parameters are for which transformation. Second - XML content as a string??? Otherwise it's good enough.
Tomorrow I'm going to finish documenting the nxslt NAnt/MSBuild task and release it.
Used to control and organize the flow of documents, the XProc language standardizes interactions, inputs and outputs for transformations for the large group of specifications such as XSLT, XML Schema, XInclude and Canonical XML that operate on and produce XML documents.
The "Proc" part stands for "Processing", so it's XML processing language.
Here is a sample "validate and transform" pipeline just to give you a taste of what XProc is about:
Syntax can spoil everything. We need visual XProc editor!
After all I think it's pretty damn good idea. I need it now. And we've got everything in .NET to implement it - XInclude, XSLT, validation, Canonical XML. So I'm going for this. This will be great addition to the Mvp.Xml project.
XML Notepad 2006 was released on the 1st September 2006, and 2 months later it had 175,000 downloads! So it looks like this little utility has found a useful place in your toolkit which is exactly what we were hoping. Thanks for all the great feedback and bug reports; many of which have been incorporated and fixed in this new version. While this is mostly a bug fix release (like fixing the install on Vista!) there are also a few new features thrown in just for fun.
New in this version:
Added keyboard accelerators for find again (F3) and reverse find (SHIFT+F3).
Added support for loading IXmlBuilder and IXmlEditor implementations from different assemblies using new vs:assembly attribute.
Made source code localizable by moving all error messages and dialog strings to .resx files.
Added a default XSL transform.
New icons, a play on the Vista "Notepad" icons.
XML Notepad 2006 2007 is a tree view based XML editor, and it's not in my tool list because I can't work with XML editor which won't show me XML source, but then I'm XML geek and I feel more comfortable seeing angle brackets than tree view, while I'm sure lots of people will love it. Give it a try anyway.
I only wonder why all this stuff isn't in Visual Studio? Why is that Microsoft XML team can afford playing with another XML editor while Visual Studio XML Editor still sucks having no XML diff, no XPath search, no refactoring, no decent XSLT editor nor XML Schema designer?
Back in 2005 I was writing about speeding up Muenchian grouping in .NET 1.X. I was comparing three variants of the Muenchian grouping (using generate-id(), count() and set:distinct()). The conclusion was that XslTransform class in .NET 1.X really sucks when grouping using generate-id(), performs better with count() and the best with EXSLT set:distinct().
Here is that old graph:
Today a reader reminded me I forgot to post similar results for .NET 2.0 and its new shiny XslCompiledTransform engine. So here it is. I was running simple XSLT stylesheet doing Muenchian grouping. Input documents contain 415, 830, 1660, 3320, 6640, 13280, 26560 and 53120 orders to be grouped.
Besides being pretty damn faster that XslTransform, XslCompiledTransform shows expected results - there is no difference in a way you are doing Muenchian grouping in .NET 2.0 - all three variants I was testing are performing excellent with very very close results. Old XslTransform was full of bad surprises. Just switching to count() instead of generate-id() provided 7x performance boost in grouping. That was bad. Anybody digging into XslTransform sources knows how ridiculously badly generate-id() was implemented. Now XslCompiledTransform shows no surprises - works as expected. No tricks needed. That's a sign of a good quality software.
Reporting errors in XSLT stylesheets is a task that almost nobody gets done right. Including me - error reporting in nxslt sucks in a big way. Probably that's because I'm just lazy bastard. But also lets face it - XslCompiledTransform API doesn't help here.
Whenever there are XSLT loading (compilation) errors XslCompiledTransform.Load() method throws an XsltException containing description of the first error encountered by the compiler. But as a matter of fact internally XslCompiledTransform holds list of all errors and warnings (internal Errors property). It's just kept internal who knows why. Even Microsoft own products such as Visual Studio don't use this important information when reporting XSLT errors - Visual Studio's XML editor also displays only first error. That sucks.
Anyway here is a piece of code written by Anton Lapounov, one of the guys behind XslCompiledTransform. It shows how to use internal Errors list via reflection (just remember you would need FullTrust for that) to report all XSLT compilation errors and warnings. The code is in the public domain - feel free to use it. I'm going to incorporate it into the next nxslt release. I'd modify it a little bit though - when for some reason (e.g. insufficient permissions) errors info isn't available you still have XsltException with at least first error info.
private void Run(string[] args) {
XslCompiledTransform xslt = new XslCompiledTransform();
try {
xslt.Load(args[0]);
}
catch (XsltException) {
string errors = GetCompileErrors(xslt);
if (errors == null) {
// Failed to obtain list of compile errors
throw;
}
Console.Write(errors);
}
}
// True to output full file names, false to output user-friendly file names
private bool fullPaths = false;
// Cached value of Environment.CurrentDirectory
private string currentDir = null;
///
/// Returns user-friendly file name. First, it tries to obtain a file name
/// from the given uriString.
/// Then, if fullPaths == false, and the file name starts with the current
/// directory path, it removes that path from the file name.
///
private string GetFriendlyFileName(string uriString) {
Uri uri;
if (uriString == null ||
uriString.Length == 0 ||
!Uri.TryCreate(uriString, UriKind.Absolute, out uri) ||
!uri.IsFile
) {
return uriString;
}
string fileName = uri.LocalPath;
if (!fullPaths) {
if (currentDir == null) {
currentDir = Environment.CurrentDirectory;
if (currentDir[currentDir.Length - 1] != Path.DirectorySeparatorChar) {
currentDir += Path.DirectorySeparatorChar;
}
}
if (fileName.StartsWith(currentDir, StringComparison.OrdinalIgnoreCase)) {
fileName = fileName.Substring(currentDir.Length);
}
}
return fileName;
}
private string GetCompileErrors(XslCompiledTransform xslt) {
try {
MethodInfo methErrors = typeof(XslCompiledTransform).GetMethod(
"get_Errors", BindingFlags.NonPublic | BindingFlags.Instance);
if (methErrors == null) {
return null;
}
CompilerErrorCollection errorColl =
(CompilerErrorCollection) methErrors.Invoke(xslt, null);
StringBuilder sb = new StringBuilder();
foreach (CompilerError error in errorColl) {
sb.AppendFormat("{0}({1},{2}) : {3} {4}: {5}",
GetFriendlyFileName(error.FileName),
error.Line,
error.Column,
error.IsWarning ? "warning" : "error",
error.ErrorNumber,
error.ErrorText
);
sb.AppendLine();
}
return sb.ToString();
}
catch {
// MethodAccessException or SecurityException may happen
//if we do not have enough permissions
return null;
}
}
Feel the difference - here is nxslt2 output:
An error occurred while compiling stylesheet 'file:///D:/projects2005/Test22/Test22/test.xsl':
System.Xml.Xsl.XslLoadException: Name cannot begin with the '1' character, hexadecimal value 0x31.
And here is Anton's code output:
test.xsl(11,5) : error : Name cannot begin with the '1' character, hexadecimal value 0x31.
test.xsl(12,5) : error : Name cannot begin with the '0' character, hexadecimal value 0x30.
test.xsl(13,5) : error : The empty string '' is not a valid name.
test.xsl(14,5) : error : The ':' character, hexadecimal value 0x3A, cannot be included in a name.
test.xsl(15,5) : error : Name cannot begin with the '-' character, hexadecimal value 0x2D.
It's surprisingly easy in .NET 2.0. Obviously it can't be done with pure XSLT, but an extension function returning line number for a node takes literally two lines. The trick is to use XPathDocument, not XmlDocument to store source XML to be transformed.
The key is IXmlLineInfo interface. Every XPathNavigator over XPathDocument implements this interface and provides line number and line position for every node in a document. Here is a small sample:
using System;
using System.Xml;
using System.Xml.XPath;
using System.Xml.Xsl;
public class Test
{
static void Main()
{
XPathDocument xdoc = new XPathDocument("books.xml");
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("foo.xslt", XsltSettings.TrustedXslt,
new XmlUrlResolver());
xslt.Transform(xdoc, null, Console.Out);
}
}
Ability to report line info is another reason to choose XPathDocument as a store for your XML (in read-only scenarios such as query or transformation) - in addition to better performance and smaller memory footprint.
If you really need the same, but with XmlDocument, you have to extend DOM.
When working with XPath be it in XSLT or C# or Javascript, apostrophes and quotes in string literals is the most annoying thing that drives people crazy. Classical example is selections like "foo[bar="Tom's BBQ"]. This one actually can be written correctly as source.selectNodes("foo[bar=\"Tom's BBQ\"]"), but what if your string is something crazy as A'B'C"D" ? XPath syntax doesn't allow such value to be used as a string literal altogether- it just can't be surrounded with neither apostrophes nor quotes. How do you eliminate such annoyances?
The solution is simple: don't build XPath expressions concatenating strings. Use variables as you would do in any other language. Say no to
selectNodes("foo[bar=\"Tom's BBQ\"]")
and say yes to
selectNodes("foo[bar=$var]")
How do you implement this in .NET? System.Xml.XPath namespace provides all functionality you need in XPathExpression/IXsltContextVariable classes, but using them directly is pretty much cumbersome and too geeky for the majority of developers who just love SelectNodes() method for its simplicity.
I still own xsl.info and xpath.info domain names and still have no time to build anything around there. If anybody have any ideas about any community driven projects - let me know, I'm willing to donate domain name and may be participate.
And if anybody want to buy these domain names - I'm willing to sell.
.NET's XmlReader is a great XML parser, but it has one big flaw in its API: XmlReader doesn't expose attribute types. XML actually defines 8 attribute types: CDATA, ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS. Yes, it's DTD, which apparently Microsoft considers to be dead, but ID, IDREF, IDREFS types are really important ones. They provide support for cross-references and many XML languages rely on them, particularly XPath, XSLT, XQuery, XPointer, XInclude.
That means XmlReader cannot be used to develop third-party implementations of those languages unless one sticks to XPathDocument/XmlDocument, which know attribute types internally.
I wonder if XLinq will have this information, because if not - XSLT over XLinq won't be supporting id() function.
Btw, in Java SAX and Stax both happily expose attribute types... Makes me envy.
I though I filed it as a bug years ago, but I didn't. So although it's too late, here it is. I'm sure it will be another "thanks for suggestion, we'll consider it for the next release", but anyway. Vote please whoever cares.
Another coding horror story was reported in the microsoft.public.dotnet.xml newsgroup:
I've been experiencing OutOfMemory errors on our prodution webserver for a few weeks now. I've finally managed to isolate (I think) the problem to our use of c# script blocks in our xsl files. While debugging I discovered that the app domain for one of our sites had 13000+ assemblies loaded.
Cool. This is just a remainder for those who use XSLT scripting (msxsl:script) in .NET: watch out, this feature can be pure evil if used unwisely - it leaks memory and there is nothing you can do about it.
The problem is that when XSLT stylesheet is loaded in .NET, msxsl:script is compiled into an assembly via CodeDOM and then loaded into memory, into the current application domain. Each time the stylesheet is loaded above process is repeated - new assembly is being generated and loaded into the application domain. But it's impossible to unload an assembly from application domain in .NET!
Here is KB article on the topic. It says it applies to .NET 1.0 only, but don't be confused - the problem exists in .NET 1.1 and 2.0. Moreover I'm pretty much pessimistic about if it's gonna be fixed in the future.
The solution is simple - just don't use script in XSLT unless you really really really have to. Especially on the server side - XSLT script and ASP.NET should never meet unless you take full resonsibility for caching compiled XslCompiledTransform. Use XSLT extension objects instead.
Update. Of couse Yuriy reminds me that msxsl:script runs faster than an extension object, because msxsl:script is available at compile time and so XSLT compiler can generate direct calls, while extension objects are only available at run-time and so can only be called via reflection.
That makes msxsl:script a preferrable but danger solution when your stylsheet makes lots of calls to extension functions.
In a perfect world of course msxsl:script would be compiled into dynamic methods (just like XSLT itself), which are GC reclaimable, but I don't think CodeDOM is capable of doing this currently. I wonder if it's possible to compile C#/VB/J# method source into dynamic method anyway?
Also it's interesting how to improve extension objects performance - what if extension objects could be passed at compile time? They are usually available anyway at that time too. Or what if compiled stylesheet could be "JITted" to direct calls instead of reflection?
The FXSL functional programming library for XSLT provides XSLT programmers with a powerful reusable set of functions and a way to implement higher-order functions and use functions as first class objects in XSLT .
Now XPath 2.0 functions, operators and constructors as well as XSLT 2.0 functions have "higher-order FXSL wrappers that makes possible to use them as higher order functions and to create partial applications from them".
While Ajax can greatly improve the usability of a Web application, it can also create several opportunities for possible attack if the application is not designed with security in mind. Since Ajax Web applications exist on both the client and the server, they include the following security issues:
• Create a larger attack surface with many more inputs to secure • Expose internal functions of the Web application server • Allow a client-side script to access third-party resources with no builtin security mechanisms
From all dangers one sounds the most horrible - authors claim that "Ajax Amplifies XSS". Ajax allows cross-site scripting (XSS) attacks to spread like a virus or worm. And that's not an imaginary threats, the attacks are already happening.
In 2006 "The Yamanner worm" infested Yahoo Mail and managed to capture thousands email addresses and uploaded them to a still unidentified Web site.
Provided that the problem wasn't that Yahoo or MySpace staff is incompetent:
"The problem isn't that Yahoo is incompetent. The problem is that filtering JavaScript to make it safe is very, very hard," said David Wagner, assistant professor of computer science at the University of California at Berkeley
It's for sure just a matter of time before Google or Microsoft Ajax based applications will be hacked, not to mention vendors with less experienced developers driving to Ajax by the hype and widely leveraging "cut and paste” coding technique.
"JavaScript was dangerous before Ajax came around," noted Billy Hoffman, lead R&D researcher at SPI Dynamics Inc., a computer security firm. With the addition of Ajax functionality in many other Web applications, the problem is going to get worse before it gets better, he said.
Pessimistic summary, but what would you expect in a "Worse is Better" world?
XML processing is changing. In Java SAX slowly but steadily goes away or at least goes into low level and nowadays Java with StAX is not so different from .NET XmlReader. I found it pretty interesting to compare approaches to streaming filtering XML in Java and .NET. Filtering is a very useful technique for transforming XML on the fly, while XML is being read. Filtering out parts or branches application isn't interested to process is a great way to simplify XML reading code, which is especially important in streaming XML processing which usually tends to be more complicated than in-memory based (XML DOM) processing.
Let's say we have this dummy XML and we want to extract "interesting data" out of it.
<root>
<ignoreme>junk</ignoreme>
<data>interesting data</data>
</root>
StAX API has a dedicated built-in facility for filtering - StreamFilter/EventFilter (as it happens in Java world StAX is a bit overengineered and contains actually two APIs - iterator-style and cursor-based one). Here is how it looks in Java with wonderful StAX:
XMLInputFactory xif = XMLInputFactory.newInstance();
XMLStreamReader reader = xif.createXMLStreamReader(
new StreamSource("foo.xml"));
reader = xif.createFilteredReader(reader, new StreamFilter() {
private int ignoreDepth = 0;
public boolean accept(XMLStreamReader reader) {
if (reader.isStartElement()
&& reader.getLocalName().equals("ignoreme")) {
ignoreDepth++;
return false;
} else if (reader.isEndElement()
&& reader.getLocalName().equals("ignoreme")) {
ignoreDepth--;
return false;
}
return (ignoreDepth == 0);
}
});
// move to <root>
moveToNextTag(reader);
// move to <data>
moveToNextTag(reader);
// read data
System.out.println(reader.getElementText());
reader.close();
Where moveToNextTag() is an utility method doing what its name says:
do {
reader.next();
} while (!reader.isStartElement() && !reader.isEndElement());
XmlStreamReader actually provides method nextTag(), but weirdly enough it can't skip text (even text filtered out by an underlying filter!) and throws an exception.
Now .NET code. Unlike StAX, .NET doesn't provide any facility for XML filtering so usual approach is to implement filter as a full-blown custom XmlReader and then chain it to another XmlReader instance. As I said before implementing custom XmlReader even .NET 2.0 still sucks (holy cow - 26 abstract methods or deriving from legacy nonconormant XmlTextReader). So I'm going to use XmlWrappingReader helper I was recommending to use:
public class Test
{
private class XmlFilter : XmlWrappingReader
{
public XmlFilter(string uri)
: base(XmlReader.Create(uri)) { }
public override bool Read()
{
bool baseRead = base.Read();
if (NodeType == XmlNodeType.Element &&
LocalName == "ignoreme")
{
Skip();
return base.Read();
}
return baseRead;
}
}
static void Main(string[] args)
{
XmlFilter filter = new XmlFilter("../../foo.xml");
XmlReader r = XmlReader.Create(filter, null);
//move to <root>
r.MoveToContent();
//Move to <data>
MoveToNextTag(r);
Console.WriteLine(r.ReadString());
}
private static void MoveToNextTag(XmlReader r)
{
do
{
r.Read();
} while (!(r.NodeType == XmlNodeType.Element) &&
!(r.NodeType == XmlNodeType.EndElement));
}
}
Amazingly similar but not so cool because of lack of anonymous classes in .NET 2.0 (expected in .NET 3.0).
In short - what I like in Java version - built-in support for XML filtering, anonymous classes. What I don't like in Java version: filter can be called more than one time on the same position, what means that real filter implementation must support such scenario; very ascetic API, too few utility methods.
What I like in .NET version: lots of useful methods in XmlReader such as Skip(), ReadToXXX() etc. What I don't like - no built-in support for filters, no anonymous methods.
Besides - if you work with StAX you can readily work with .NET XmlReader and the other way. Great unification saves hours learning for developers. I wonder if streaming XML processing API should be standardized?
Microsoft, BEA, IBM, Cisco, Intel , HP etc mix XML Schema, Schematron and XPointer to create a draft of
the Service Modeling Language (SML) used to model complex IT services and systems, including their structure, constraints, policies, and best practices.
A model in SML is realized as a set of interrelated XML documents. The XML documents contain information about the parts of an IT service, as well as the constraints that each part must satisfy for the IT service to function properly. Constraints are captured in two ways:
1. Schemas - these are constraints on the structure and content of the documents in a model. SML uses a profile of XML Schema 1.0 [2,3] as the schema language. SML also defines a set of extensions to XML Schema to support inter-document references.
2. Rules - are Boolean expressions that constrain the structure and content of documents in a model. SML uses a profile of Schematron [4,5,6] and XPath 1.0 [9] for rules.
Once a model is defined, one of the important operations on the model is to establish its validity. This involves checking whether all data in a model satisfies the schemas and rules declared.
This specification focuses primarily on defining the profile of XML Schema and Schematron used by SML, as well as the process of model validation.
Sort of XML Schema without some crappy features enhanced with Schemtron rules and XPointer based partial inclusions. Sounds cool not only in the domain of the service modeling. I wish I could use it for plain XML validation.
Just in case if somebody have missed this cool new tool - check out DonXML's into into XPathmania. It's free open-source Visual Studio add-in for XPath development. I just can't live without it already. Very cool stuff, part of our Mvp.Xml project.
Microsoft finally released MSXML6 (aka Microsoft Core XML Services) SDK. I've been told it was expected back in December. Anyway, it's ready. Now it would be nice if Microsoft updated MSXSL utility to support MSXML6 (I know it was also ready back in December too).
How would you validate XSLT output on the fly without caching transformation result as a whole? That's easy - just use MvpXslTransform class that adds to the XslCompiledTransform class ability to transform into XmlReader and wrap that reader witth a validating reader. As a result - streaming validation, no memory hogging and ability to abort transformation at first validation error. Simple sample below.
XPathDocument doc =
new XPathDocument("source.xml");
MvpXslTransform xslt = new MvpXslTransform();
xslt.Load("XSLTFile1.xslt");
XmlReader resultReader =
xslt.Transform(new XmlInput(doc), null);
XmlReaderSettings settings = new XmlReaderSettings();
settings.ValidationType = ValidationType.Schema;
settings.Schemas.Add("", "orders.xsd");
XmlReader validatingReader =
XmlReader.Create(resultReader, settings);
XmlWriter w = XmlWriter.Create(Console.Out);
w.WriteNode(validatingReader, false);
w.Close();
You can get MvpXslTransform class with Mvp.Xml library v2.0 at the Mvp.Xml project site.
New C# 2.0 features like Anonymous Methods, Anonymous Delegates and Generics
BCL additions.
Lightweight Code Generation (LCG).
Stub-based dispatch. (What the hell is that?)
Numerous bug fixes.
There is always the Reflector, but Rotor is different - you build it, debug with it, learn and extend CLI. Now what do I want to play with? Editable XPathDocument or XSLT2DLL compiler or extendable XmlReader factory may be...
And going on with Word as XSL-FO editor theme - take a look at a brand new tool called foActive <X>Styler:
foActive <X>Styler is a plug-in for Microsoft Word 2003 Professional which allows a user to design and test dynamic document templates right from within the Word authoring environment.
<X>Styler is used to create XSL templates for server-based transformation for high-volume dynamic document print applications such as direct mail, correspondence, invoicing, statements, contracts, and legal forms.
And more:
Writing XSL templates that generate XSL FO output can be a difficult task, one suited for an engineer and not a marketing person. What the industry needed was an easy-to-use tool for designing templates to convert XML to XSL FO using XSL. There are applications that have recently emerged to do just this, however these are standalone applications designed from the ground-up for just this purpose. As such, they can be unnecessarily complex and require specific custom training to master. They expose all the functionality and complexities of XSL to the end-user.
And so foActive designed <X>Styler, merging the most common desktop application in use -- Microsoft Word -- with the difficult to master XSL design. We coupled the whole system to the industry's best XSL FO engine -- RenderX -- to deliver a complete solution for a wide variety of XSL design tasks.
jCatalog Software AG has releaed XSLfast 3.0 - XSL-FO WYSIWYG editor. What's new in version 3.0. In general XSL-FO doesn't meant to be authored, the idea is that XSL-FO is generated using XSLT. Unfortunately that requires knowledge of XSL-FO twisted vocabulary and, well, XSLT. I always knew WYSIWYG editor could save XSL-FO and XSLfast might be that one. If only the price wasn't freaking 890,00 EUR per license. And that probably doesn't include XSL-FO formatter itself!
Btw, after years and years Apache FOP Team's finally discussing 1.0 release...
And you thought XML is done? No way. It's alive and kicking technology. And here is just one more proof: yet another new XML API from Microsoft - the XmlLite. It's a native library for building high-performance secure XML-based applications. XmlLite library is a small one by design - it only includes pull XML parser (native analog of the .NET's XmlReader), XML writer (native analog of the .NET's XmlWriter) and XML resolver (similar to the .NET's XmlResolver). XmlLite's meant to be small, simple, secure, standards-compliant but damn fast library to read and write XML. It's claimed to be able to parse XML even faster than MSXML. What I found especially compelling is XmlLite API similarity with .NET - no need to learn yet another way to read and write XML, it's a lite version of the .NET's XmlReader/XmlWriter, but for native programming. It's a "lite", so: no validation, very limited DTD processing (entity expansion and defaults for attributes only), no ActiveX, no scripting languages, not thread-safe etc.
Bruce Eckel doesn't like XML. But alas - it's everywhere and he has to deal with it. So as you can expect, he goes and creates "general purpose XML manipulation library called xmlnode." for Python. That should be easy, right? Just one class, no need for more. Alas, it doesn't support namespaces, mixed content, CDATA sections, comments, processing instructions, DTD, Doctype, doesn't check well-formedness rules such as element and attribute names or allowed in XML characters etc. Well, that must be version 0.0...
W3C has released fresh versions of the Candidate Recommendations of XML Query 1.0, XSLT 2.0, XPath 2.0 and supporting documents. No big deal changes - xdt:* types has been moved to xs:* namespace (damn XML Schema). See new XQuery1/XPath2 type system below. Looks like XSLT2/XPath2/XQuery1 are moving fast toward Proposed Recommendation. What's weird is that new documents all say
"This specification will remain a Candidate Recommendation until at least 28 February 2006." Must be a mistake. Anyway, what are now chances for XSLT 2.0 in the .NET? Next major .NET release (Orcas) is expected October 2007 or so (forget newly announced .NET 3.0, which is actually .NET 2.0 + Avalon + Indigo). Plenty of time for XSLT2 to reach Recommendation status, even provided that Microsoft actually freezes codebase 6 months before shipping.
This is second part of the post. Find first part here.
So what is a better way of creating custom XmlReader/XmlWriter in .NET 2.0? Here is the idea - have an utility wrapper class, which wraps XmlReader/XmlWriter and does nothing else. Then derive from this class and override methods you are interested in. These utility wrappers are called XmlWrapingReader and XmlWrapingWriter. They are part of System.Xml namespace, but unfortunately they are internal ones - Microsoft XML team has considered making them public, but in the Whidbey release rush decided to postpone this issue. Ok, happily these classes being pure wrappers have no logic whatsoever so anybody who needs them can indeed create them in a 10 minutes. But to save you that 10 minutes I post these wrappers here. I will include XmlWrapingReader and XmlWrapingWriter into the next Mvp.Xml library release.
From .NET 1.X experience Microsoft seems finally figured out that providing a set of concrete poorly composable XmlReader and XmlWriter implementations (XmlTextReader, XmlTextWriter, XmlValidatingReader, XmlNodeReader) and emphasizing on programming with concrete classes instead of anstract XmlReader/Xmlwriter was really bad idea. One notorious horrible sample was XmlValidatingReader accepting abstract XmlReader instance and downcasting it silently to XmlTextReader inside. In .NET 2.0 Microsoft (with a huge diffidence) is trying to bring some order to that mess:
XmlReader and XmlWriter now follow factory method design pattern by providing static Create() method which is now recommended way of creating XmlReader and XmlWriter instances.
While not being marked as obsolete or deprecated or not recommended, concrete implementations like XmlTextReader and XmlTextWriter are now just wrappers for internal classes used to implement Create() factory method.
I've uploaded HTML versions of the XLinq Overview, XLinq Overview Diff (Sep 2005/May 2006) and XLinq SDK Reference to the XLinq.net portal. I don't fee it's right that I have to install heavy preview-quality package into my system just to be able to read these stuff. Or may be I just used to MSDN online. Diff is also cool for lazy/busy devs like me. Anyway. Btw, XLinq Overview link at the LINQ Project homepage points to the old September 2005 version.
The draft is available in PDF, which was created by Word 2007
The draft also available in Open XML format itself, which one will be use once Office 2007 Beta 2 is out
The document is huge and specifies everything down to the "Maple Muffins" border style kinda details
These guys help MIcrosoft in creating Ecma Office Open XML format: Apple, Barclays Capital, BP, The British Library, Essilor, Intel, Microsoft, NextPage, Novell, Statoil, and Toshiba
Drop eXml control onto a Web form, assign DocumentSource property (WordML document you want to render), TransformSource property(wordml2html-.NET-script.xslt):
<xmllab:eXml ID="EXml1" runat="server"
DocumentSource="~/TestDocument.xml"
TransformSource="~/wordml2html-.NET-script.xslt"/>
Create new folder to store external images
In code behind allow XSLT scripting and pass couple XSLT parameters - real path to above image directory and its virtual name:
I had to add these two parameters so the WordML2HTML stylesheet could export images there and then refer to exported images in HTML. If you don't pass these parameters images will be exported into current directory - while that's ok when running WordML2HTML transformation in a command line, that's bad idea for ASP.NET environment.
Well, "XSLT 2.0 in .NET" survey at the XML Lab site has ended back in January and I forgot to select a winner. Ooops. Let's finish this now.
I obviously made a mistake requiring user registration for voting, but then I needed some way to identify a winner... Anyway, 40 people registered and voted (thanks guys), which is not bad for such a small unknown site. 72% need XSLT 2.0, 25% think it would be nice to have, 2% happy with XSLT 1.0. Quite predictable given my audience.
And the winner (choosen truly randomly using EXSLT random:random-sequence() function) is Yoeri Van de Moortel from Belgium. Congratulations, Yoeri! Get in touch with me, I need your address to send the "XSLT 2.0 Programmer's Reference" book by Mike Kay (or some other XSLT book if you happens to own this one already).
Ok, I'm back. I have updated eXml Web Server Control, which uses XslCompiledTransform, supports 70+ EXSLT functions, XInclude, friendly XML rendering, <?xml-stylesheet?>, embedded stylesheets etc.
Martin Szugat found some bugs and kindly provided patches, thanks Martin! Additionally I implemented one small but useful feature users kept asking for - cache dependencies for imported/included stylesheets. That's when you have included or imported stylesheet and modify it - now eXml control notices it and recompiles XSLT on the next request. Go get eXml Web server control v1.1.
Now I think about eXmlDataSource control... Free asp:XmlDataSource analog running XslCompiledTransform, supporting EXSLT, XInclude, <?xml-stylesheet?> and embedded stylesheets - it sounds useful, isn't it?
Vote now and get a chance to win the "XSLT 2.0" book by Mike Kay!
When the survey ends one lucky survey taker from whatever part of the world choosen randomly will get the book.
Note: you have to be registered on the Xml Lab site to vote. Sorry, but I need some simple way to identify the winner. Registration is simple and public - no email verification or something like, just fill in your name, password and email and then vote.
Now that XslCompiledTransform in .NET 2.0 supports exsl:object-type() extension function I think a little intro is needed as this is really new function for Microsoft-oriented XSLT developers.
Creators of the XQDoc, a free tool for documenting XQuery modules have released XQuery Style Conventions. They claim the document to be to be based on experience and feedback from the
XQuery development community. It does seem ok to me. In a perfect world every programmer would follow style conventions of course. But we live in another kind of world...
As many other Microsoft MVPs I've been given 3 "Visual Studio 2005 Team Suite with MSDN Premium Subscriptions" redemption cards to share. So now I'm having hard time looking for smart ideas how to do so. One card I would give to Kevin Downs, the guy who runs NDoc if he still has no MSDN subscription, but for the rest two I probably would go the way my fellow MVPs went and arrange some sort of contest. XML contest, of course, hmmm. Ummm, any ideas, anyone?
Sometimes it's useful to detect which XSLT engine your XSLT stylersheet is being executed by, e.g. to shortcut processing using an engine-specific extension function or to workaround a bug in particlular engine. Now that Microsoft alone ships 3 different XSLT engines - MSXML3/MSXML4/MSXML5/MSXML6, XslTransform and XslCompiledTransform, detecting XSLT engine from within XSLT stylesheet may be vital requirement. Here is how it can be done.
There are two new killer but undocumented features in Microsoft .NET 2.0 pertaining to EXSLT. Anybody like me regularly digging in System.Xml assembly probably knows it, but general audience is still unaware. So I want to share these secrets.
Almost 2 years ago I published a post "Transforming WordML to HTML: Support for Images" showing how to hack Microsoft WordML2HTML stylesheet to support images. People kept telling me it doesn't support some weird image formats or header images. Moreover I realized it has a bug and didn't work with .NET 2.0. So finally I updated that damn stylesheet. Now I took another Microsoft WordML2HTML stylesheet as a base - that one that comes with Word 2003 XML Viewer tool. I think it's a better one. Anyway, I added to it a couple of templates so images now get decoded and saved externally and headers and footers are processed too (only header/footer for odd pages per section to be precise).
Note: this stylesheet uses embedded C# script to decode images and so only works with .NET XSLT processors, such as XslTransform (.NET 1.1) or XslCompiledTransform (.NET 2.0). You can also run it with nxslt/nxslt2 command line tool. Here is a small demo.
Ok, this is gonna be the firrst podcast I want to subscribe to. It's "A Weekly XML Industry Podcast Hosted by Kurt Cagle and M. David Peterson". First real pilot segment can be found here. It's about OASIS Open Document and Microsoft's Open XML formats.
MSXML6 SDK documentation is online now. In fact it's "multi-version" documentation, which covers MSXML3 through MSXML6.
So, what's new in MSXML6? Looks like it's security tightening, XML Schema support improvements and removals:
What's New in MSXML 6.0
MSXML 6.0 shipped with SQL Server 2005. It also shipped as a Web release. The following is a high-level summary of features that were introduced with MSXML 6.0.
Security
A number of enhancements have been made to MSXML 6.0 to eliminate security threats. Additionally, some features that are insecure, such as DTDs and inline schemas, have been turned off by default. For more information, see MSXML Security Overview.
MSXML 6.0 has changed the behavior of the XSD schema cache. The new version is less ambiguous when there are name collisions. For more information, see Improvements in Schema Cache Behavior.
XML Digital Signature Removed
MSXML 6.0 removed support for XML digital signatures. For more information, see XML Digital Signatures.
Other Changes in MSXML 6.0
There are a number of other changes in MSXML 6.0. A few of the changes may require modifications to applications. For more information, see Changes in MSXML 6.0.
It's a pity support for the XML Digital Signature was removed. It was implemented for Office and most likely Microsoft doesn't want a burden of supporting it for all MSXML users. Another sad fact is an obvious fork of MSXML - MSXML5 is actually "MSXML 5.0 for Microsoft Office Applications", not available as a separate download. That was probably not a good idea.
Slowly, gradually and with not much loud buzz both modern managed platforms - Java and .NET have switched to compiling XSLT implementations by default. First Java 5.0 made compiling Apache XSLTC processor a default transformer in JAXP 1.3 (instead of interpreting Apache XALAN). Then Microsoft released .NET 2.0 with new XSLT implementation - XslCompiledTransform replacing now obsolete XslTransform (guess what - interpreting one). XSLTC compiles XSLT into Java bytecode just like Java compiler, while XslCompiledTransform compiles XSLT into Microsoft Intermediate Language (MSIL) just like C# or VB compiler. The similarity is striking. Does it mean the era of interpreting XSLT processors is over and XSLT compilation is the future?
This is the first Microsoft product using XInclude via Mvp.Xml library. Hope not the last one, way to go guys. I truly hope to see one day Microsoft Biztalk release including our EXSLT implementation.
As a matter of interest - Mvp.Xml project is an open-source project hosted at SourceForge, led by Microsoft MVPs and supplementing XML processing functionality in .NET. We currently provide .NET implementations of EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes and tools making XML programming in .NET platform easier, more productive and effective. Microsoft has licensed the Mvp.Xml project and has rights to use and distribute our code base.
Miloslav Nic has announced the first snapshot of XSLT 2.0 tutorial at Zvon. Good stuff. I remember 5 year ago I was learning XSLT 1.0 using Zvon's tutorial...
Dare thinks I'm making fruitless noise asking people if they need XSLT 2.0:
I'm not sure how an informal survey in a blog would convince Microsoft one way or the other about implementing a technology. A business case to convince a product team to do something usually involves showing them that they will lose or gain significant marketshare or revenue by making a technology choice. A handful of XML geeks who want to see the latest and greatest XML specs implemented by Microsoft does not a business case make.
Well Dare you underestimate the power of geeks and blogs :) Of course I'm not making a busines case. I'm looking for real world XSLT2 business cases (and not without results btw) trying to help Microsoft XML Team. I can't disclose more, but believe me guys we really can help now with such obviousboring stuff like real world scenarios for XSLT2.
Then he comes with some good advice:
My advice to Oleg, if you want to see XSLT 2.0 in the .NET Framework then gather some like minded souls and build it yourself. Efforts like the MVP.XML library for the .NET Framework shows that there are a bunch of talented developers building cool enhancements to the basic XML story Microsoft provides in the .NET Framework.
First of all as one of developers who runs Mvp.Xml project I should say that "a bunch" is a big overstatement here. Unfortunately only a really handful people are willing/have a chance to contribute to the project. Actually now, 3 years after I switched to .NET I'm pretty much pessimistic about open-source .NET projects altogether. There is something with people's attitude, it's different from that one in Java or linux world. And so I'm also kinda pessimistic about community developed .NET XSLT2 as I know the field. But that's of course my backup plan in any case.
Also I found interesting some comments made to Dare's post. Take a look.
And my personal take is similar to the one expressed by Mike Champion: Microsoft will implement XSLT2 anyway. The question is only when.
I run into this article "Harnessing the BackPack API" by Michael K. Campbell in the new and very cool "XML 4 Fun" column at MSDN. The article is otherwise brilliant and really fun, but XML processing code samples are not so good. It's actually a great collection of XML processing antipatterns. Let's see.
Moving along business cases Microsoft seeks to implement XSLT 2.0 I'm trying to gather some opinion statistics amongs developers working with XML and XSLT. So I'm holding this survey at the XML Lab site:
Would you like to have XSLT 2.0 implementation in the .NET Framework?
The possible answers are:
Yes, I need XSLT 2.0
Yes, that would be nice to have
No, continue improving XSLT 1.0 impl instead
No, XSLT 1.0 is enough for me
Vote now and get a chance to win the "XSLT 2.0" book by Mike Kay!
When the survey ends (probably in a month or so) one lucky survey taker from whatever part of the world choosen randomly will get the book.
Note: you have to be registered on the Xml Lab site to vote. Sorry, but I need some simple way to identify the winner. Registration is simple and public - no email verification or something like, just fill in your name, password and email, get registered and then vote.
Take your chance to influence Microsoft's decision on XSLT 2.0 and win XSLT 2.0 book!
I'm glad to announce first release of the eXml - extended ASP.NET Xml Web Server Control.
eXml is a free open-source ASP.NET 2.0 Web server control extending and improving standard ASP.NET XML Web server control. eXml Web server control uses new .NET 2.0 XSLT processor - XslCompiledTransform class to perform XSL transformations thus providing in average 400% performance boost and improved standard compliance. Additionally eXml Web server control provides built-in support for 70+ EXSLT extension functions, XML Inclusions (XInclude) 1.0, friendly XML rendering, <?xml-stylesheet?> XML processng instruction, embedded stylesheets and conditional whitespace stripping.
If you are using XSLT and you think that XSLT 2.0 would provide you some real benefits, please drop a line of comment with a short explanation pleeeease. I'm collecting some arguments for XSLT 2.0, some real world scenarios that are hard with XSLT 1.0, some business cases when XSLT 2.0 would provide an additional value. That's really important if we want to have more than a single XSLT 2.0 implementation...
Update: I failed to stress it enough that it's not me who needs such kind of arguments. We have sort of unique chance to persuade one of software giants (guess which one) to support XSLT 2.0 now.
When it comes to
business email many growing companies need to keep in mind that their business email
services are a huge part of the communication in the business, and the right business email
can help to run a tight ship.
nxslt v2.0 (aka nxslt2) is available for download. This is first nxslt release for .NET 2.0.
nxslt is a free feature-rich command line utility that allows to perform XSL Transformations (XSLT) using .NET Framework 2.0 XSLT implementation - System.Xml.Xsl.XslCompiledTransform class. nxslt is compatible with Microsoft's MSXSL.EXE tool and additionally supports XInclude 1.0, 70+ EXSLT and EXSLT.NET extension functions, multioutput, embedded stylesheets, custom XmlResolvers and custom extension functions, pretty printing etc etc etc.
Michael Rys asks "What do you want to see regarding XML support in the next version of SQL Server?" Don't miss a chance to suggest your favorite feature.
I'm glad to announce release 2.0 of the Mvp.Xml library. This is first Mvp.Xml release for .NET 2.0. Download it here.
Mvp.Xml project is developed by Microsoft MVPs in XML technologies and XML Web Services worldwide. It is aimed at supplementing .NET framework XML processing functionality available through the System.Xml namespace and related namespaces such as System.Web.Services. Mvp.Xml project currently provides .NET implementations of EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes such as XmlSerializerCache, IndexingXPathNavigator, SubtreeXPathNavigator, XPathNavigatorIterator, XslReader, MpXslTransform and tools making XML programming in .NET platform easier, more productive and effective.
The FXSL functional programming library for XSLT provides XSLT programmers with a powerful reusable set of functions and a way to implement higher-order functions and use functions as first class objects in XSLT.
I do think functional programming matters, that's where we are going and that FXSL rocks. I'm not sure what will be my role in the project, but I hope to be helpful. But first I have to refresh my functional programming skills with wonderful "Haskell: The Craft of Functional Programming" book by Simon Thompson.
Just released Microsoft Core XML Services (MSXML) 6.0 introduces some security-related breaking changes in XML and XSLT processing, but MSXML6 SDK documentation isn't released yet (expected next week) and can be found nowhere on the net, so you might have a hard time wondering why basic things stop working after upgrading to MSXML6. Here is a bit of information that might be helpful.
After initial announcement XLinq hubbub seems to be more and more quiet - users are busy moving to .NET 2.0 and Microsoft is working on the next preview version. Anyway, there are some news:
This is an updated version of the LINQ Technical Preview unveiled at PDC 2005. It includes samples, whitepapers, hands-on labs and compiler support to create LINQ-enabled applications using the RTM release of Visual Studio 2005 or Visual C# 2005 Express Edition.
Similar update for VB is available too. Note that LINQ homepage is obsolete at this point
That's a big milestone in a 6-years-going-so-far design-by-committee experiment: XSLT 2.0, XQuery 1.0 and XPath 2.0 are finally W3C Candidate Recommendations. That means that W3C now officially calls for implementations (which shows another weirdness of the design-by-committee process as XQuery alone has about 40 implementations already as per Ken North). CR phase will last at least till 28 February 2006, that means late 2006 is probably the timeframe for the XSLT 2.0, XQuery 1.0 and XPath 2.0 Recommendations.
There is a knownproblem with new XSLT processor in just released Microsoft .NET 2.0 - XslCompiledTransform class doesn't support pull mode XSLT - outputting XSLT result in XmlReader form as obsolete XslTransform class did. I'm happy to announce that the problem is solved now. Sergey Dubinets from the Microsoft XML Team has developed XslReader implementation which allows to read XSLT output via XmlReader in a very efficient way - i.e. without full output buffering. It's concurrent writer-reader bridge, which runs XSLT in another thread and lets it to produce another output portion whenever reader wants to read more.
And Sergey kindly donated his code to the Mvp.Xml project, so it will be part of the Common module of Mvp.Xml library v2.0, which is going to be released really really really really soon. Kudos to Sergey! Stay tuned.
In any event, after much procedural wrangling, the W3C has finally chartered a new Working Group in the XML Activity to address the problem of a standard XML pipeline language, the XML Processing Model Working Group. And they persuaded me to chair it, for better or worse. :-) The charter lays out the scope, goals, and deliverables pretty well, so I won't bother recapitulating them here.
Another minor nxslt release is available - v1.6.4. This version adds support for the "extension-element-prefixes" attribute and fixes a glitch in transformation timings reporting.
What's the problem with "extension-element-prefixes" attribute? When using <exsl:document> extension element to produce multiple outputs some EXSLT-aware XSLT tools (like 4XSLT) rightly require "exsl" prefix to be registered in the "extension-element-prefixes" attribute. The problem was that .NET's XslTransform class while not supporting extension elements at all, throws an exception once encountering "extension-element-prefixes" attribute. So for running the same stylesheet with nxslt one had to remove "extension-element-prefixes" attribute, and with other tools - add it. Bad bad bad. So in nxslt 1.6.4 I fixed the issue by hiding "extension-element-prefixes" attribute from XslTransform class, so now you can use it in you stylesheets and enjoy better portability.
As a matter of interest, new .NET 2.0 XSLT processor - XslCompiledTransform class, while still not supporting extension elements, at least ignores "extension-element-prefixes" attribute. Good.
Microsoft put hundreds of hours PDC 2005 videos online at http://microsoft.sitestream.com/PDC05. Here is a list of XML-related and others interesting presentations worthwhile watching IMHO.
Opera 9.0 Preview 1 released October 20 finally adds support for XSLT and XPath to the Opera browser. Finally they are awake. Good move, but it might be too late for the Opera.
Interesting - during last month both leading XML hardware makers - DataPower and Sarvega were acquired - former by IBM and latter by Intel. Both sites have almost similar "We are acquired!" announcements.
I'm also happy to report that my implementation of XML Catalog support, currently part of the xml-commons project at Apache, will ship as a standard part of the next Java™ release.
You've got a standard. You've got an implementation. What are you waiting for? I've been using catalogs for at least ten years, and XML Catalogs for at least five, so really, you can start deploying them today.
If you have tried to create or use code snippets in any of XML languages in Visual Studio 2005 you probably stumbled across the issue of using shortcuts. In C# or VB you just type code snippet's shortcut name and press Tab, it just works. In XML it doesn't :(. I've spent couple of hours reflecting into XML editor to see why it doesn't work (that was an interesting waste of time anyway) and when I just found out how it works I also found out (via Aaron Skonnard) it's documented at MSDN. RTFM, RTFM, RTFM.
Unfortunately inserting code snippets by shortcut name in XML editor of Visual Studio 2005 isn't as smooth as in C# or VB. Two more keystrokes: < and Esc. So press <, Esc, then shortcut and then Tab. That sucks, but I can live with it.
In .NET 2.0 ValidationType.Auto value is made obsolete. What's worse - it doesn't work for XmlReaders created via XmlReader.Create() factory method. But how do you validate against either DTD and/or schema, i.e. against DTD if document has a DOCTYPE and/or schema if any is applicable? The answer is: you can chain two XmlReaders, one set up for performing DTD validation and second - schema validation.
Microsoft XML Team has published an article "Migrating to XslCompiledTransform" by my pals Sergey Dubinets and Anton Lapunov. It explains how to migrate to the new XSLT 1.0 processor in .NET 2.0 - XslCompiledTransform class. XslCompiledTransform is a revolutionary XSLT processor - it's gonna be the first truly compiled mainstream XSLT processor. It's fast and conformant just as MSXML4.
The article covers: how XslCompiledTransform works, differences in API, in behaviour, new functionality, faq, howto.
The article is meant to be updated on a regular basis. Once a new migration issue is discovered the article will be updated with a solution. So bookmark it. And the article is not complete yet, some parts are still to be done. Keep up your great work, guys.
nxslt 1.6.1 is available for download at the xmllab.net. This is bug fix only release. Marc Stober reported that when running into XInclude error he got MissingManifestResourceException. Apparently XInclude string resources weren't compiled into the nxslt.exe. This release fixes this bug. Thanks for reporting, Marc!
nxslt is free feature-rich command line .NET XSLT utility, supporting EXSLT.NET, XInclude, multiple output etc etc etc.
No new features in this release. Instead I'm working on nxslt2 - nxslt for .NET 2.0.
I've been looking for a blog search service and been naturally inclined to use Google blog search, but I was quite disappointed to find out that feeds produced by Google are malformed. Trivial lame mess with encoding, hence no use by XML tools. Apparently XML is too hard for Google. Oh well, at least Technorati sucks less.
I finally got some time (18 hours in a plane to Seattle :) to settle down my mind about XLinq. Erik Meijer's excellent article, which explains XLinq from functional programming point of view made me changing my mind on some issues I wrote earlier, some hands on experience and some comments from smart readers helped me to see a bigger picture.
XLinq is at early stages, but what else would I like to see in XLinq? Here are my crazy wishes.
Shortcuts. In C# I need book["title"] instead of book.Element("title").
last() and position()
Literal XML just like in C-omega, not "kinda pseudo XML literals" like in VB9.
Fine control over serialization just like in XQuery
XPath support. I know it anyway and many do, so why to learn any new way to select nodes in XML tree? XPath is small, concise and intuitive. I want to write less code, so XPath is the way to go.
Nodes in XLinq overload ToString() method to provide pretty-printed outer XML representation. At the same time nodes contain (familiar for MSXML users and new for .NET users) readonly Xml property, which returns raw (not pretty-printed) outer XML representation. At also at the same time casting element to a string returns element's value (string value with no angle brackets). There are also WriteTo() methods and Save() methods to complete the picture. I believe that's unnecessary confusing. Not only cast to string and ToString() do completely different things, but also there are many different ways of serializing nodes.
In XLinq XML Tree is exposed in a heterogenos way, that is nodes in a tree don't belong to a common type. Traditionally XML tree models are homogeneous, e.g. in DOM every node belongs to a specific kind of XmlNode class. But in XLinq attributes and text nodes aren't actually nodes. Instead attributes are just name-value properties of element nodes and text nodes while being internally normal nodes, never get exposed as such, but only as values they contain, so in effect what you can get out of XLinq tree is XNode (XElement etc), XAttribute and String values (which you can cast to appropriate CLR types). Apparently the goal was to simplify API and data model comprehension for users.
XLinq is new and hot technology everybody seems to be happy with. I'm going to post a different review series - not what I like, but what I dislike and want to be fixed in XLinq. Sorry in advance for bitter words, but it's better when your friend says them.
Being excited about XLinq I couldn't stop myself from grabbing XLinq.NET domain name. I'm going to try to build a community portal for the XLinq technology. The goal is basically to push XLinq by growing a community around it. There is definitely a need for Microsoft-independent easily accessible place where developers can find XLinq resources or share their experience.
Well, that's my vision at the moment. There is not much content at the site currently, just basic info and links. If you've got any ideas/suggestions about what would like to find at XLinq.Net, please drop me a line.
1. Schemas Property on your XML document
2. Inline inside your XML document
3. xsi:schemaLocation or xsi:noNamespaceSchemaLocation attributes in your XML document
4. Open Document Window.
5. Anywhere in your current Project
6. In the Schema Cache Directory or from a Schema Catalog file.
Is it actually sane? Now I can easily imagine a situation when I cannot be sure against which XML Schema file I'm validating my documents. Lots of flexibility, too much or just right? What is your take?
Little xml:id spec finally got W3C Recommendation status. I believe XML programming would be better be xml:id done in 1998, not in 2005. Anyway. xml:id provides a mechanism for annotating elements with unique identifiers. You just set xml:id attribute for an element and you done, no need for DTD, XML Schema or anything else:
Having elements annotated with IDs you can query them (usually very fast and efficiently) by ID values using various XML API specific means - GetELementById() in DOM, id() function in XPath/XSLT/XQuery, XPathNavigator.MoveToId() etc.
We've heard about XML penetration into C#, Java and SQL. Now it seems like 45-years old programming language, 75% of worlds's business apps is written in is ready to adopt XML. I'm talking about Cobol, yeah baby! In the "XML and the New COBOL" article at webservicessummit.com Barry Tauber explains proposed forthcoming standard that will add native XML support to the Cobol language. IBM, HP and MicroFocus are behind this move, so chances are good.
And btw I'm currently working with Fujitsu NetCobol, which is .NET based Cobol and as such has full access to the .NET XML processing facilities. Not bad approach too!
C# 3.0 Language Enhancements
Description: Can't attend PDC but still want to talk to the C# team? This chat is your chance! Join the C# team to discuss the newly announced C# 3.0 features like extension methods, lambda expressions, type inference, anonymous types and the .NET Language Integrated Query Framework. You've been hearing rumblings about this for a while, now we finally talk in depth about the future of the C# language.
I've seen some people talking and some leaving comments that newly introduced XPathNavigator.SelectSingleNode() method is actually a wrapper around XPathNavigator.Select and so it provides no performance benefits. This is both true and false. It's true that you won't get any performance boost from moving to XPathNavigator.SelectSingleNode() method, because it's really just a wrapper around XPathNavigator.Select() returning first selected node. But that's also false that there is something wrong with it. No performance boost because XPathNavigator.Select() is efficient itself and never selects all nodes, returning instead XPathNodeIterator, which actually selects nodes once its MoveNext() method is called. So there is no perf difference, both are very fast and XPathNavigator.SelectSingleNode() method is mostly just about code elegance and convenience for a coder.
It's surprisingly tricky to get BinHex encoded data out of XmlDocument tree in .NET 1.X. XmlConvert class, which apparently has to support such conversions has a method FromBinHexString(), but weird - it only public for .NET Compact Framework. It's internal for regular .NET Framework. It's obvious that lots of .NET functionality isn't supported in .NET Compact Framework, but this is first time I see anything that .NET CF implements and .NET doesn't. Hmm, and in the forthcoming .NET 2.0 it's the same, do I miss something? Anyway, here is a workaround.
Jeni Tennison has announced an utility for unit-testing XSLT stylesheets:
I've just developed a set of stylesheets that are designed to support
unit testing of XSLT stylesheets. You embed tests in the stylesheet
and can run a script (or configure your editing environment) to
extract and run them and create an HTML report on the result. Further
details and the download is available from:
Direct language support for XML has been a debate for some time. All these things at an abstract level kind of sound like the thing to do.
When it comes down to the details, one of the problems ends up being that using Java today you actually get pretty good access to XML.
And really what it would end up being is sort of syntactic sugar that makes certain constructions simpler, but can you come up with something that actually makes people's life better by enough that it's worth adding that baggage?
It's one of these things that these days is a community debate.
That's pretty surprising. And even disappointing to some. I personally consider my Java XML programming experience as a horror. Well, then I was mostly writing XML processing apps in Java when DOM and SAX were the only ways and so whenever possible I escaped to XPath and XSLT. Now reading these James Gosling's words I'm happy I switched to .NET.
Michael Kay has released Saxon XSLT and XQuery processor v8.5. This new release implements some very interesting optimizations (available only in commercial version though) and new abilities, one of which is probably worth to implement in EXSLT.NET module.
Colin Paul Adams has announced Gobo Eiffel XSLT - free XSLT 2.0 processor written in Eiffel. Gexslt is intended to conform to a Basic-level XSLT 2.0 Processor and currently is still under development. Win32 compiled version can be downloaded at http://www.gobosoft.com/download/gobo34.zip.
If you thought it's only Microsoft who's working on integrating XML into the core of programming languages, look at what IBM does for Java. This is a manstream trend now. XML Enhancements for Java are an emerging technology from IBM, which provides a set of language extensions that facilitate XML processing in Java.
This is a real hidden gem in .NET 2.0 everybody (including me) have pretty much overlooked. XmlSchemaValidator class from the System.Xml.Schema namespace is a push-based W3C XML Schema validatation engine. Push-based means different processing model - an opposite for pull-based one. Think about how you work with XmlWriter (push) and XmlReader (pull). With (obsolete now) .NET 1.X's XmlValidatingReader and .NET 2.0's XmlReader with validation enabled you read XML to make sure it's valid. With XmlSchemaValidator you do the opposite - you ask it to validate XML bits using ValidateElement, ValidateAttribute, ValidateText etc methods.
Erik Saltwell explains what this XslCompiledTransform.OutputSettings property is and why it exists. That's really fresh, clean and powerful design once you get it. I didn't first.
If you thought that some smell of XML in C-omega was amazing, believe me that's nothing. Major XML and .NET integration stories are still ahead of us. Something big is cooking inside the house. Look at these news.
XPathReader is originally developed inside Microsoft and then dropped out as open-source implementation of a pull-based XML parser that supports XPath queries while parsing the XML document. It's basically XmlReader that supports streaming subset of XPath 1.0. Read "The Best of Both Worlds: Combining XPath with the XmlReader" article for more info about XPathReader.
New in this release:
Support for look-ahead in predicates such as "foo[bar='baz']". This is done via internal caching using XmlBookmarkReader. This behaviour can be turned off using XPathReader.LookAheadInPredicates property.
XPathReader.dll is now has a strong name, so it can be called from strongly named assemblies
AllowPartiallyTrustedCallers attribute is applied, so XPathReader.dll can be called by partially trusted callers (e.g. in ASP.NET)
In .NET 2.0 XPathNavigator finally has SelectSingleNode() method! MSXML and XmlDocument (XmlNode actually) have it forever and it's so widely used because it's soooo handy. Obviously despite its name, XPathNavigator.SelectSingleNode() returns not a node, but node equivalent in XPathNavigator's data model - XPathNavigator. And this method is even better than XmlNode's one, because it has overloads accepting compiled XPathExpression, so when running within a loop you don't have to pay XPath compilation price on each iteration. That's another reason to switch completely to XPathNavigator API when processing XML in .NET 2.0.
nxslt 1.6 and nxslt2 Beta1 are available for download. For those not familiar with nxslt: nxslt is free feature-rich .NET XSLT Command Line Utility.
nxslt 1.6 is the next version for the .NET 1.X Frameworks. New features include optionality for source XML or stylesheet, pretty printing, ASCII only escaped output and support for "omit-xml-declaration" attribute of the exsl:document extension element.
nxslt2 Beta1 is the first beta version of the next major nxslt release. nxslt2 uses new XSLT 1.0 processor in the .NET 2.0 Framework - System.Xml.Xsl.XslCompiledTransform class. Hence it requires .NET 2.0 Beta2 (which you can download here) or higher. As a first beta version, nxslt2 Beta1 is quite limited - no support for XInclude, EXSLT, multiple output and embedded stylesheets. As far as I port EXSLT.NET and XInclude.NET to .NET 2.0 I'll update nxslt2.
New Microsoft XSLT Processor (XslCompiledTransform) is a great stuff. Compiles XSLT to MSIL and runs as fast as MSXML4. I'll be writing about it a lot soon. With nxslt2 you can give it a whirl.
WebServicesSummit.com has released two podcasts of a panel discussion with Ron
Bourret, Dana Florescu, Michael Kay, Jonathan Robie and Michael Rys. The
discussion topics include XQuery, native XML databases, SQL/XML databases, XSLT
and related topics.
The part 1 podcast (MP3 audio) focuses primarily on XQuery (running time:
34:03). The part 2 podcast covers native XML databases and XML-enabled SQL
databases. Running time is 22:46. http://www.webservicessummit.com/People/XQueryGuruPanel.htm
I was wrong in my last post. Here is how one can output HTML with XslCompiledTransform when XmlResolver needs to be passed to Transform() method.
using (XmlReader src = XmlReader.Create("../../source.xml"))
{
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("../../style.xslt");
XmlWriter result = XmlWriter.Create(Console.Out, xslt.OutputSettings);
xslt.Transform(src, null, result, new XmlUrlResolver());
}
The key line is emphasized. One just needs to pass XslCompiledTransform's OutputSettings (after XSLT stylesheet is loaded) to XmlWriter.Create() method and then resulting XmlWriter will output transformation results according to <xsl:output> settings in the XSLT stylesheet. Really nice once I get it.
I'm porting nxslt utility to .NET 2.0 with XslCompiledTransform as XSLT processor and I just found out XslCompiledTransform API is really severe broken. I was writing before that the only Transform() method overload that accepts XmlResolver outputs to XmlWriter. So if you want to create HTML and to have some control over document() function resolving (or just provide user credentials), you are out of luck with XslCompiledTransform. Quite common scenario, isn't it? Too bad, XML Team should hire better testers.
What I dislike in System.Xml v2.0 (and v1.X for that matter) is a poor support for push-based XML processing. Somehow it's all about pull - XmlReader, while push - XmlWriter seems to be a second class citizen. For instance one can't populate XML into XPathDocument or XSLT stylesheet into XslCompiledTransform with XmlWriter. One can't deserialize an object from XML if XML is represented as XmlWriter etc. In a nutshell: XML producers in .NET write XML into XmlWriter, while XML consumers read XML from XmlReader. The problem with this mix of pull and push arises when one tries to pipeline a XML producer and a XML consumer, i.e. a component that writes to XmlWriter and another one which reads from XmlReader. Ooops! Think about feeding XML created with XSLT into SqlXml or deserializing an object from an XML modified by XSLT or chaining two XSLT transformations when output from the first one goes as input to the second one or generating XSLT stylesheet on the fly. Most of these problems can't be solved in .NET 2.0 in a streaming fashion and require interim buffering of the whole XML effectively killing scalability and performance. Look here and here. I'm really sorry to see interim buffering with serializing/reparsing involved as an XML pipelining solution in a modern technology like .NET 2.0.
I know I'm late, but anyway here is the latest Dimitre's puzzle. Don't post your anwers here, just send them him to dnovatchev AT gmail DOT com. Dimitre will be collecting answers only for another week, so hurry up.
I just started reading the book "The Da Vinci code" and this resulted
in having some fun with XSLT 2.0, Saxon 8.4 and Saxon.NET.
Here's the problem:
Find the first 10-digit prime in consecutive digits of F-3000
Where F-N is the Nth Fibonacci number.
Here are the elements of the sequence of Fibonacci numbers from 0 to 11:
It is *very important* to note that the first "1" in the sequence has
index "0", so that everyone will mean the same thing by F-3000
When you have the answer, please, let me know:
1. The 10 digit prime number
2. The xslt code
3. The stylesheet execution time.
4. Your computer -- CPU speed and RAM
5. Whether or not you used any specific extension functions.
I'm working (again) on the XML Chapter to our upcoming book. The book is all about ASP.NET 2.0, but XML is such an important part of ASP.NET that this chapter gets bigger and bigger. I've been updating it from the original Beta 1 version this last few months and noticed that the namespace qualification for the XmlDataSource is still broken/incomplete as it was last year in September. I talked to a bunch of people at TechEd including a number of very helpful devs and PMs who were very much interested in resolving this issue. However, unfortunately it looks like this'll be one of those features that won't make it into the final, which means one of us will have to write our own.
That's a bummer. I feel a smell of degradation here. When a brand new XML-specific ASP.NET control doesn't support XML namespaces, uses obsoleted XslTransform class and they can't get it fixed during a year - that's really lame. I'm really sorry seeing such stuff coming from Microsoft.
Definitely we need to provide a fixed version.
AJAXSLT is an implementation of XSL-T in JavaScript, intended for use in fat web pages, which are nowadays referred to as AJAX applications. Because XSL-T uses XPath, it is also an implementation of XPath that can be used independently of XSL-T.
That's weird. Wait, all modern browsers (ok, except Opera) support XSLT natvely, don't they? Well, here is how they explain the goals:
Both XPath and XSL-T are built into some of the modern browsers,
however not in all. This library runs on many browsers, including
those that don't support XSLT adaequately or at all, which is why the
library was written in the first place. (See BROWSER COMPATIBILITY,
below.)
And more:
Safari/2.0 has XSL-T built in, but it is not exposed to JavaScript,
but is only applied to XML documents that have a stylesheet
declaration when they are loaded.
Internet Explorer exposes XSLT via the transformNode() method on the
XML DOM. However, this is not avaiable if ActiveX is disabled.
Firefox exploses XSLT via the XSLTProcessor() object, however XPath
is not exposed in the DOM.
Hmmmm, still weird. But still cool. Any efforts to bring XSLT client side are always cool. I'm glad to see Google supporting the idea.
Excellent articles. Part 3 is expected too according to Alex's site. Yeah, I just found out Alex Homer has a site and even very interesting blog (with no RSS feed and not so frequently updated though). It's http://www.daveandal.net/alshed.asp. Alex, you really need RSS feed on your site!
It's official now - we (XML MVPs) agreed and Dare (as EXSLT.NET project owner) has approved an integration of the EXSLT.NET project into the Mvp.Xml library. All EXSLT.NET project contributors may ask to be added as developers to the Mvp.Xml project. I will be moving code soon, as well as doing some EXSLT.NET development. Current plans are: .NET 2.0 version and support for XSLT 2.0 stylesheet functions. Stay tuned.
XSLT 2.0 -
1. Do we need to support XSLT 2.0 ?
2. What are the most useful features of XSLT 2.0 that you would like to see implemented? (like grouping , support for datetime etc)
3. Do you believe support for the entire 2.0 spec is useful? If yes , why?
kzu says he has broken the mark of 100 bugs filed to the MSDN Feedback Center. That's impressive. My numbers are humble - only 15 bugs and suggestions. Gotta be more active here. I spent a day working on an adapter to my homegrown XSLT test suite for the XslCompiledTransform class and the very first run brought a bunch of issues. Now I have to analyze the log and file bugs. I'm happy I found already a quite significant one - XslCompiledTransform thinks NaN equals to NaN. To put it another way - "number('foo')=number('bar')" evaluates to true! That's really bad, because that property of NaN (non equality to anything) is the base for a quite widespread technique in XSLT 1.0 on determining whether a value is a number - "number($val) = number($val)" is true if and only if $val is a number.
The big news today is of course announced next Office's full deep XML-ization. I've read a dozen of enthusiastic postings already and decided not to bother my readers with another whoohoo-like post from another XML nerd. But what amazed me more than the announce itself (which was predictable) is the overall excitement about the news. Ranging from Scoble to Tim Bray - everybody seems to value ultimate XMLization of the next Office as "big cool news". Not a single critical post - what's the matter with you people? And even more:
I think another version or two after the upcoming Office, binary files will become completely obsolete and forgotten and won't be able to round-trip the latest features.
says Wesner Moise (former Excel developer at Microsoft and overall smart guy).
Another improvement System.Xml 2.0 brings, from the how-come-I-didn't-make-it--before department is that XPathNavigator class now implements IXPathNavigable. Sounds obvious, huh? In both common and OOP sense of course XPathNavigator should be IXPathNavigable, but somehow in .NET 1.0 and 1.1 it is not. (And by the way I still wonder how come XmlNodeReader doesn't implement IHasXmlNode interface. Too bad I made this suggestion too late and now we must wait another year or two for this). Anyway, these 2 lines of code:
public virtual XPathNavigator CreateNavigator()
{
return this.Clone();
}
made a magic to the XslCompiledTransform API. 4 redundant Transform() overloads down! Now input to XSLT is either string (URL), XmlReader or IXPathNavigable.
And if you aren't familiar with IXPathNavigable - don't bother. Just remember that you can pass XmlDocument, XPathDocument, XmlDataDocument or XPathNavigator objects as is to the Transform() method as all these classes implement IXPathNavigable. API simplicity is invaluable and I'm glad version 2.0 of the System.Xml looks simpler than previous ones.
A fellow MVP asked if there is a way to dump XML content while reading it from a stream without buffering the whole XML document. Here is a scenario - an XML document being read from a HttpWebResponse stream and needs to be passed as an XmlReader to an XmlSerializer to deserialize it into objects. This works fine in a streaming way - just create an XmlReder over the stream and pass it to an XmlSerializer. But what if incoming XML needs to be logged? Of course then one could go buffer-log-process architecture, effectively killing performance and scalability. Fortunately there is a better way - by extending XmlReader one can make it dumping current node it's positioned at. Here is how.
Altsoft N.V. has announced a relase of the Xml2PDF formatting engine version 2.3, now supporting WordML. Altsoft Xml2PDF is a .NET based formatting engine for converting
various XML-based formats to PDF. It supports XSL-FO, SVG, XHTML,
WordML and
XML+XSLT as an input and generates PDF as an output. The prices are from $49 for the Workstation version to $1599 for the API version. Free evaluation versions are available.
SourceForge has fixed the stat system and now we can analyze Mvp.Xml project statistics. The numbers are good - 8-15K hits/mo and 700-800 downloads/mo, not bad for a 1.0 release.
Some users report that after installing Netscape 8 Internet Explorer and other IE-based browsers usch as Avant browser stop applying XSLT stylesheets, even the default stylesheet used to render XML documents. That probably has something to do with "Firefox or IE6 rendering" feature in Netscape. Beware.
Jonathan Marsh, who is one of Microsoft's representatives at the W3C, an editor of XML Base, XPointer, XInclude, xml:id, some XQuery 1.0 and XPath 2.0 specs and is by the way the original author of the defaultss.xsl which is used in Internet Explorer to display XML documents, is blogging. His blog called Design By Committee. Subscribed.
Another handy feature implemented in .NET 2.0 Beta2 is that XmlReader class now implements IDisposable interface and so can be closed automatically when using with "using" statement in C#:
using (XmlReader r = XmlReader.Create("../../source.xml"))
{
while (r.Read())
Console.WriteLine(r.NodeType);
}
Really handy. And implemented in literally couple of lines. It's a pity we don't have such simple but useful stuff in .NET 1.1.
.NET XSLT API is traditionally ugly. XslTransform class (obsoleted in .NET 2.0) had 8 Load() methods and 9 Transform() ones in .NET 1.0. In .NET 1.1 - 11 Load() methods (5 of them obsoleted) and 18 Transform() (9 obsoleted). Huge mess. Brand new XslCompiledTransform in .NET 2.0 Beta2 has just 6 Load() methods and 14 Transform() ones, none obsoleted so far. Sounds good, but does this pile of method overloads cover all usage cases? Unfortunately not.
Norm Walsh writes about a very nasty problem waiting to happen when anybody naive enough is trying to validate an XML document after XInclude processing against XML Schema. Ooops, XInclude processor appends xml:base attributes at top-level included elements, which you gotta allow in the schema, most likely on every element! And XML Schema of course doesn't support declaring of such globally allowed attributes, so you have to add its definition to every single element declaration. And that's not all! Norm forgot about xml:lang attribute, which XInclude processor can and should append too. I mentioned that issue in the "Combining XML Documents with XInclude" article.
This session explores advanced concepts and techniques for working with XML data types using Microsoft SQL Server 2005 and Visual Studio 2005. Topics covered include casting to and from CLR types, working with XML on the provider level, and integrating with SQLXML 4.0. Learn how to pass XML into CLR stored procedures and functions and how to use that to extend the XML functionality on the server (using validation and XSLT).
Presenter: Michael Rys, Program Manager, Microsoft Corporation
This document describes the requirements for the XQuery Update Facility. [XQuery 1.0] provides queries, but has no support for adding new values or changing existing values. The XML Query Working Group intends to add support for updates in a future version of XQuery.
So instead of polishing existing XQuery/XPath2/XSLT2 drafts to deliver finally something stable, they have started thinking about XQuery Update. Great. Now chances are 2006 as XQuery Recommendation publishing year is a way too optimistic.
As a matter of interest here are how XQuery and XSLT2 are positioned now:
XML Query is an XML-aware programming language that can be optimized to run database-style searches, queries and joins over collections of documents, databases and XML or object repositories.
XSLT 2 allows transformation of XML documents and non-XML data into other documents.
It's XML's birthday today - the very first XML 1.0 Recommendation has been published 10 February 1998 - 7 years ago. That's a mature technology which you can find everywhere, because XML just works. And it's still extremely hot!
IBM is giving away 2000 free vouchers, applicable to selected WebSphere and XML certification tests.
To qualify for a voucher, a candidate is required to be one of the first people to pass the aligning Pre-assessment/Sample Test between January 1, 2005 (12:00 a.m. Eastern Time) and April 30, 2005 (11:59 p.m. Eastern Time).
Each Pre-assessment/Sample Test costs $10 USD, so one can get IBM certification for just $10.
So I did this week. The pre-assessment test is done online, boring. Then in a couple of days I received a voucher for a real certification test. I've got a certification center just 500 meters from my work, so next day I went to take a test. It's Test 141, "IBM Certified Solution Developer - XML and Related Technologies". 57 multiple-choice questions, 90 minutes, 58% to pass. XML fundamentals, XSLT, XPath, XML Schema, DTD, DOM, SAX, Web Services, I even got one question on XSL-FO, nice. Well, despite no preparation and quite rusty Java XML skills I passed with 94%.
So it works and they're still sending free vouchers. Go for it you want to be IBM Certified Solution Developer or just looking for some entertainment.
Hey, what a surprise from the W3C! XInclude 1.0 has been published as W3C Recommendation today. That was fast! Less than 3 months in Proposed Rec status - and here it is, XInclude 1.0 - another standard XML Core technology.
This document describes the properties we desire of the Web and the design choices that have been made to achieve them. It promotes the reuse of existing standards when suitable, and gives guidance on how to innovate in a manner consistent with Web architecture.
That's a must reading for all developers working with Web, XML and URIs. We can make the Web a better place by following principles, constraints and practices defined in that document.
I arrived at work and found 200+ new posts in xml-dev list. Lovely. XML is still extra hot topic. Here are some nice quotes:
For my money, XQuery is a heroic effort by a bunch of incredibly smart people which is crippled - we don't know how seriously - by its insistence on cohabiting with XSD.
XSLT has an <xsl:copy> construct that does a shallow copy of an element node
together with all its namespaces (yes, you're right, I wouldn't expect
anyone to guess its specification by looking at the element name, any more
than I would expect anyone to guess what a left outer join operator does).
XQuery has no equivalent. My XQuery example used a computed element
constructor, which is the equivalent of <xsl:element> in XSLT: this isn't
copying any namespaces from the source document.
As another parallel thread notes, namespaces are responsible for a
ridiculous amount of the complexity in both these languages and the people
who invented them should be .... Any suggestions for a suitable punishment?
I see someone flaming someone else for not being XHTML compliant. Tim Bray - if you're reading this, I want to know something. Why is XML case-sensitive? No human-being ever thinks in case-sensitive terms. A is a. End of story. So now, I have a situation where writing <html> </HTML> wouldn't be XHTML compliant. And what do I get out of XHTML apart from geek-bragging rights and this strange idea of 'standards-compliance'? Does it give me more freedom? Does it help my viewers? My customers?
Well, this guy is definitely heavily sloppy-HTML-contaminated. What? <html> </HTML> isn't XHTML complaint? Thanks GOD! Anyway, Tim Bray does answer his question:
XML markup is case-sensitive because the cost of monocasing in Unicode is horrible, horrible, horrible. Go look at the source code in your local java or .Net library.
Also, not only is it expensive, it's just weird. The upper-case of e' is different in France and Quebec, and the lower-case of 'I' is different here and in Turkey.
XML was monocase until quite late in its design, when we ran across this ugliness. I had a Java-language processor called Lark - the world's first - and when XML went case-sensitive, I got a factor of three performance improvement, it was all being spent in toLowerCase(). -Tim
BTW, as nicely pointed out by Michael Kay, XML document with no XML declaration, in encoding other than UTF-8 or UTF-16 is not necessarily malformed! In fact XML spec allows encoding information to be provided externally (e.g. via Content-type HTTP header).
TopXML launched XML News Reblogger service. It's basically XML blogs and news aggregator, similar to the Planet XMLhack. They aggregate selected XML-related news feeds and blogs (127 currently, including mine :) twice a day and provide a way to read all that jazz on their web site. They don't provide aggregated RSS feed currently, but as Sonu Kapoor (the guy who wrote the Reblogger) informed me, that's definitely just a matter of time.
Amazing new essay by Norman Walsh on XML 2.0. Worth reading and contemplating. The crux is "simplification". XML is too complex, who knew it six years ago :)
http://www.w3.org/ -- 16 November 1999 -- The World Wide Web Consortium (W3C) today releases two specifications, XSL Transformations (XSLT) and XML Path Language (XPath), as W3C Recommendations. These new specifications represent cross-industry and expert community agreement on technologies that will enable the transformation and styled presentation of XML documents. A W3C Recommendation indicates that a specification is stable, contributes to Web interoperability, and has been reviewed by the W3C membership, who favor its adoption by the industry.
"Anyone using XML can now take advantage of XSLT, a powerful new tool for manipulating, converting or styling documents," declared Tim Berners-Lee, W3C Director. "XPath adds a simple way of referring to parts of an XML document. Together, they strike a fine balance between simplicity of use and underlying power."
Happy birthday to XSLT and XPath and congratulations to James Clark and Steve DeRose, editors of these the best so far XML applications.
XSLT and XQuery ones are the new and the most interesting. Altova XSLT 1.0 engine is well-known XSLT engine used when debugging XSLT within XML Spy, now they just release it as a free (but not open-source of course) standalone utility (Windows 2000/XP/2003 command line executable), "suitable for use in both client- and server-side application development". Altova XSLT 2.0 engine is a similar utility, which claims to implement November 2003 XSLT 2.0 working draft. It's schema-unaware processor and doesn't support user defined types and validation. Some functions and elements aren't supported either (yet?).
Altova XQuery Engine is also available as free command line Windows 2000/XP/2003 exe, which implements July 2004 XQuery 1.0 working draft. The same here - no support for schema importing, validation and user-defined types. No support for static type checking, external functions, character normalization either. XQuery library modules are supported though. More info about limitations here.
The tools are available "for you to use both for your own purposes and to integrate into your solutions without paying any royalties or license fees." The license: Altova XSLT/XQuery Engine developer license agreement.
Sounds awesome. I just downloaded the tools, but didn't give them a whirl yet. I wonder why there is no support for schema, actually XML Spy has a very decent schema processor for years now. Hmmm, very cool tools anyway.
This working draft includes a number of changes made in response to comments received during the Last Call period that ended on Feb. 15, 2004. The working group is continuing to process these comments, and additional changes are expected. This document reflects decisions taken up to and including the face-to-face meeting in Redmond, WA during the week of August 23, 2004. These decisions are recorded in the Last Call issues list (http://www.w3.org/2004/10/xquery-issues.html). Some of these decisions may not yet have been made in this document. A list of changes introduced by this draft can be found in I Revision Log. The
Note:
A proposal that is currently under discussion would introduce a new form of type promotion, similar to numeric type promotion. Under this proposal, values of type xs:anyURI would be promotable to the type xs:string and could therefore be passed to functions such as fn:substring. One problem with this proposal is that values of type xs:anyURI are compared on a code-point basis, whereas values of type xs:string are compared using a collation. For this reason, promotion of xs:anyURI to xs:string might cause value comparison operators such as eq and gt to lose their transitive property. This proposal is pending further discussion and is not reflected in this document. However, the signatures of certain functions in [XQuery 1.0 and XPath 2.0 Functions and Operators], such as fn:doc and fn:QName, were written with the expectation that xs:anyURI would be promotable to xs:string. The signatures of these functions may change when this issue is resolved.
MSDN has published "The XML Litmus Test - Understanding When and Why to Use XML" article by Dare Obasanjo. Cool and useful stuff. But an example of inappropriate XML usage I believe is chosen quite poorly - in such kind of articles samples must be clear and clean, while sample of using XML as a syntax for programming languages is rather debatable and dubious. Sure, o:XML syntax is terrible, but there is another highly succesful for years now programming language, whose syntax is pure XML and which was created in just one year and which just rocks. After all choosing non-XML syntax for XML-processing language is not a trivial decision too and in a recent wave of the "Why *is* XQuery taking so long?" permathread in the xml-dev it was clearly stated that one of the reasons XQuery is being developed so many years was the complexity brought by the choice of a non-XML syntax:
2. Syntax issues. The mix of an XML syntax for construction with a
keyword syntax for operations is intuitive for users, but has required a
lot of work on the grammar side.
Jonathan Robie, http://lists.xml.org/archives/xml-dev/200410/msg00129.html
Oh boy, I just realized my blog is aggregated by the Planet XMLhack. Wow. Thanks for that. Must stop writing narrow-minded rubbish and start focusing on XML hacking.
Edd Dumbill has announced planet.xmlhack.com - aggregating weblogs of the XML developer community.
The weblogs are chosen to have a reasonable technical content, but
because this is as much about the community as it is about the tech,
expect the usual personal ramblings and digressions as well. In short,
Planet XMLhack's for you if you enjoy being around people from the XML
community.
That's what I call "just in time"! I just finished integrating XInclude.NET into the Mvp-Xml codebase, cleaning up the code and optimizing it using great goodies of Mvp-Xml such as XPathCache, XPathNavigatorReader etc and planned to align the code with recent XInclude CR - and here goes another spec refresh. As far as I can see, there is no new stuff or syntax changes, just editorials (such as mentioning XML 1.1 along with XML 1.0) and clarifications based on previous feedback. Comments are due to 29 October 2004. I expect to release renowned XInclude.NET next week.
Michael Kay has released Saxon 8.1, an implementation of XSLT 2.0, XPath 2.0, and XQuery in Java. Saxon 8.1 is published in two versions for both of which Java 1.4 is required. Saxon 8.1B is an open source product published under the Mozilla Public License 1.0 that "implements the 'basic' conformance level for XSLT 2.0 and XQuery." Saxon 8.1SA is a £250.00 payware version that "allows stylesheets and queries to import an XML Schema, to validate input and output trees against a schema, and to select elements and attributes based on their schema-defined type. Saxon-SA also incorporates a free-standard XML Schema validator. In addition Saxon-SA incorporates some advanced extensions not available in the Saxon-B product. These include a try/catch capability for catching dynamic errors, improved error diagnostics, support for higher-order functions, and additional facilities in XQuery including support for grouping, advanced regular expression analysis, and formatting of dates and numbers."
Hmmm, grouping for XQuery... Here is how it looks like in Saxon-SA:
declare namespace f="f.uri";
(: Test saxon:for-each-group extension function :)
declare function f:get-country ($c) { $c/@country };
declare function f:put-country ($group) {
<country name="{$group[1]/@country}"
leading="{$group[1]/@name}" size="{count($group)}">
{for $g in $group
order by $g/@name
return <city>{ $g/@name }</city>
}
</country>
};
<out>
{saxon:for-each-group(/*/city,
saxon:function('f:get-country', 1),
saxon:function('f:put-country', 1))}
</out>
Author Elliotte Rusty Harold talks about the significance of JDK 1.5 and whether
Java should be open source an/or an international standard. He also discusses
the state of XML, and we coaxed him into describing his recent books about XML
(Effective XML, XML Bible 1.1).
Docbook XSL stylesheets v1.66.0 has been released yesterday. It's a huge (9Mb) collection of XSLT stylesheets for transforming Docbook documents into HTML, XHTML, XSL-FO (PDF), HTML Help and Java Help. They are well designed by XSLT experts such as Norman Walsh and extremely well tested by huge and diverse Docbook community. You know what I mean? I hope Microsoft testers responsible for the System.Xml will finally try to test .NET XSLT implementation against Docbook stylesheets before they ship - it's a shame that only after .NET 1.1 SP1 XslTransform stopped to barf on Docbook HTML stylesheets (and it's still unable to compile Docbook XSL-FO stylesheets... ouch, is it 2004 or 1999?).
Dave Pawson identified this fallacy. He noted that the Atom specification
cannot be validated using a single technology:
> From [Atom, version] 0.3 onwards it's not been possible
> to validate an instance against a single schema, not
> even Relax NG. They need a mix of Schema and 'other'
> processing before being given a clean bill of health.
This pretty much says it all. In the beginning, my column focused almost exclusively on core XML topics such as XML namespaces, XPath, XSLT, MSXML, System.Xml, etc. Over the past few years, my focus has naturally shifted away from these topics towards emerging SO and Web services concepts. It's been a natural evolution, indicative of my work and interests. Hence, the new name is appropriate. Dare's XML Developer Center is where you should look for continued coverage on core XML topics and System.Xml.
Although I'm sad to let go of The XML Files, I'm excited about manning the Service Station.
Recent Online Chat with Microsoft XML Team was tremendously interesting, but too short (45 min?). Being MVP I wonder what if we arrange some chats on actual XML topics, like XQuery, new stuff in System.Xml v2.0, new XML editor in VS 2005, XPath/XSLT for newbies/advanced, using EXSLT.NET, you name it (tell me what you'd like to discuss online). What about the idea?
432 page book covers XML 1.0 and Namespaces, DTD, XPath 1.0, XPointer, XInclude, XML Base, XSLT 1.0, SAX 2.0, DOM level 2, XML Schema 1.0 and SOAP 1.1. Very valuable reference.
2004-07-19: The XML Schema Working Group has released the First Public Working Draft of XML Schema 1.1 in two parts: Part 1: Structures and Part 2: Datatypes. The drafts include change logs from the XML Schema 1.0 language and are based on version 1.1 requirements. XML schemas define shared markup vocabularies, the structure of XML documents which use those vocabularies, and provide hooks to associate semantics with them.
On my team we have a bunch of guidelines for writing XML Schema documents. For a while we've been checking schema against the guidelines. Unfortunately the implementation of the checker was in wetware, rather than software. Recently, I found an hour or two to put together a software implementation of a SchemaCOP which, given a schema will dump out a report telling you where you've stepped outside the guidelines.
That would be very useful tool, really. I'm looking forward to see it.
And this is even more cool:
One of the satisfying pieces of writing the code was that I was able to do it all in XSLT. I love this language, it makes hard things easy ( and easy things hard :-) )
I tend to agree with the last assertion. I think knowing XSLT well means first of all having a gut feeling of these easy2hard spots and avoiding them at the design stage. As in any other language after all.
The XML Schema Working Group has released a revised Working Draft of XML Schema: Component Designators. The document defines a scheme for identifying the XML Schema components specified by the XML Schema Recommendation Part 1 and Part 2.
The idea is to be able to address components of an XML Schema, just as we can address parts of an XML document by XPath or XPointer. An absolute schema component designator syntactically is an URI, whose main part is an URI of a schema document and fragment identifier is XPointer pointer conforming to the new proposed xscd() XPointer scheme. The syntax is obviously XPath-like.
Potential addressable XML Schema components are:
{type definitions}
{attribute declarations}
{element declarations}
{attribute group definitions}
{model group definitions}
{notation declarations}
{identity constraint definitions}
{facets}
{fundamental facets}
{member type definitions}
{attribute uses}
{particles} {annotations}
etc.
Examples:
schema-URI#xscd(/type(purchaseOrderType))
schema-URI#xscd(/type(Items)/item/productName)
or even schema-URI#xscd(/type(Items)/item/quantity/type()/facet(maxExclusive)).
Good idea, isn't it? Obviously the core question is - why not just use XPath, the schema is just XML document after all? Actually looks like they are uncomparable things. AFAIK it's also one of first (after XInclude of course) real applications of XPointer.
Cool news from the XML Editor Team (announced by Chris Lovett):
Announcing: New XML Editor in Visual Studio 2005 Beta 1
Visual Studio 2005 Beta 1 contains a completely new XML Editor, built on top of the core text editor provided by Visual Studio. It is entirely written in C# and leverages all the cool stuff provided by the System.Xml .NET assembly. The new XML editor provides support for editing XML and DTD content, including special support for XSD and XSL. It contains the following handy features:
* Full syntax coloring for all XML and DTD syntax.
* Well formedness checking while you type, with red squiggles and error list.
* Intellisense based on any DTD, XDR and XSD schemas.
* Validation-while-you-type with blue squiggles and error list.
* Auto-completion of namespace declarations, end tags and attribute value quotes.
* Support for xsi:schemaLocation and xsi:noNamespaceSchemaLocation attributes.
* Schema picker dialog for overriding schemas used for validation, which is then remembered as a document property in your solution.
* Schema cache for commonly used schemas with standard set provided out of the box. You can easily add your own schemas here or edit the existing ones to constantly improve your XML editing experience.
* Smart Formatter that is more than a pretty printer. It honors and formatting of attributes that you may have done by hand and it fixes up the most common mistakes people make in XML, like unquoted attribute values.
* Smart indenting based on XML element depth.
* Inline expand/collapse support.
* Easy navigation between start and end tags using brace matching command (Ctrl+]) .
* Brace highlighting so you see which tags are being closed as you type.
* Goto Definition command for navigating between elements and their associated DTD, XDR or XSD schema definitions. This command can also navigate from an entity reference to the entity definition in the DTD.
* Tool tips that popup showing xsd:annotations for the element or attribute under the mouse.
* XSL and XSD compilation errors while you type, providing even more error checking that can be represented in the schemas alone.
* Show XSLT Output command available on any XML or XSLT file.
XSD Schema Inference
The editor provides a handy command named "Create Schema" which does one of three things:
1. Convert associated DTD to XSD
2. Convert associated XDR schema to XSD
3. Infer a schema from the XML
This is by far the easiest way to get started with designing an XSD schema.
XSLT Debugging
In non-Express SKU's only, this feature gives you a powerful XSLT debugger, fully integrated into the overall Visual Studio debugging experience so you can step from C# code directly into the XSLT transform itself and back out, or from XSLT out to extension objects and back. It also provides a "Debug XSL" command on XML editor toolbar to start debugging directly from XML or XSL file.
Once debugging has started the standard Visual Studio debugging menu is available including special support for the following:
Setting and clearing breakpoints, at the node level (as opposed to line level).
Locals window that shows XSLT variables and parameters that are in scope.
Call Stack window that shows XSLT template stack.
Deep VS Integration & Extensibility
All the advanced core text editor commands and configurability is available, for example:
o Fully configurable colors using standard Tools/Options/Environment/Fonts and Colors property page.
o Fully integrated text editor settings (Tools/Options/Text Editor/XML) for general, tabs and miscellaneous settings.
o Support for the new Visual Studio 2005 "Import/Export Settings" feature.
Support for multiple-views over the same buffer. In Visual Studio 2003, the XSD designer and grid views were only available from a tab at the bottom of the document window, which means you could not view both ways at the same time. This limitation has been removed, and each different view is now a full fledged document window.
Custom XML designers can also be registered per file extension and/or XML namespace URI, which is how the Visual Studio XSD designer, DataSet designer, and the Grid View are associated with the XML editor. Anyone can now register an XML designer for a given namespace and the XML editor will automatically provide a View Designer menu item for invoking that designer. In fact if you are planning a custom XML designer, I'd love to chat about integration with this new XML text editor.
All I can say is "finally!"
Well, I'm working on decreasing the size of the "Items for Read" folder in RSS Bandit. Still many to catch up, but anyway.
XML.com has published "Non-Extractive Parsing for XML" article by Jimmy Zhang. In the article Jimmy proposes another approach to XML parsing - using "non-extractive" style of tokenization. In simple words his idea is to treat XML document as a static sequence of characters, where each XML token can be identified by the offset:length pair of integers. That would give lots of new possibilities such as updating a part of XML document without serializing of unchanged content (by copying only leading and trailing buffers of text instead), fast addressing by offset instead of ids or XPath, creating binary index for a document ("parse once, use many times" approach).
While sounding interesting (and not really new as being sort of remake of the idea of parsing XML by regexp) there is lots of problems with "non-extractive" parsing. XML in general doesn't really fit well into that paradigm. Entities and inclusions, encoding issues, comments, CDATA and default values in DTD all screw up the idea. Unfortunately that happens with optimization techniques quite often - they tend to simplify the problem. It probably will work only with a very limited subset of XML, but it's fruitfullness still needs to be proven.
Another shortcoming of "non-extractive" parsing is the necessity to have entire source XML document accessible (obviously offsets are meaningless with no source buffer at hands). That would mean the buffering the whole (possibly huge) XML document in a streaming scenario (e.g. when you read XML from a network stream).
Still that was interesting reading. Indexing of an XML document, how does it sound? Using IndexingXPathNavigator it's possible to index in-memory IXPathNavigable XML store and to select nodes directlty by key values instead of traversing the tree. That works, but there is still lots of room for developement here. What about persistent indexes? What if XslTransform would be able to leverage existing indexes instead of building its own (for xsl:key) on each transformation?
XInclude reminds me a little poor ant, which climbs up a wall, falls, climbs, falls again and climbs anyway. Today XInclude became Candidate Recommendation for the third time!
W3C is pleased to announce the advancement of XML Inclusions (XInclude) Version 1.0 to Candidate Recommendation. XInclude introduces a generic mechanism for merging XML documents (information sets) using existing XML constructs-elements, attributes and URI references. Comments and implementation reports are welcome through 28 May.
Let's see what's new. Oh no! They are changing the namespace back. It was "http://www.w3.org/2001/XInclude" untill latest Wordking Draft, which made it deprecated and introduced "http://www.w3.org/2003/XInclude". Today's Candidate Rec reverts previous "http://www.w3.org/2001/XInclude" namespace back. No fun at all. Happily XInclude.NET already supports both namespaces. Other changes are minor ones - accept-charset attribute removing, clarifications, editorial improvements, and minor bug fixes. No big deal so I'm going to update XInclude.NET and nxslt.exe next week.
The specification introduces a predefined attribute name that can always be treated as an ID and hence can always be recognized.
What can be said? At last! Finally!
xml:id Version 1.0 defines core predefined attribute xml:id you can use anywhere in XML documents (with or without DTD or schemas attached) to annotate elements with unique identifiers. Great stuff. I'm going to investigate possibilities of creating experimental implementation of xml:id for .NET. Mark wrote about it recently.
This specification contains requirements on an XML Processing Model and Language for the description of XML process interactions in order to address these issues. This specification is concerned with the conceptual model of XML process interactions and the language for the decription of these interactions.
So in simple words it's a new XML language to describe XML processing. Say you want to get XML document out of Web Service, validate it, resolve XIncludes, XQuery some data and accordingly to the results apply some XSL transformation. Of course you can write custom application to do so (and keep doing so for each new XML processing scenario), but having XPL (or may be XPML) processor available you can just define the processing flow in XML document an run it. Cool. Similar to Apache Cocoon's XSP and BizTalk orchestrations.
Some teasing use cases:
Style an XML document in a browser with one of several different stylesheets without having multiple copies of the document containing different xml-stylesheet directives.
Apply a sequence of operations such XInclude, validation, and transformation to a document, aborting if the result or an intermediate stage is not valid.
Allow an application on a handheld device to construct a pipeline, send the pipeline and some data to the server, allow the server to process the pipeline and send the result back.
Norm Walsh is in editors, so I'm sure it's gonna be great new XML family member.
Dimitri has posted a JavaScript implementation of W3C DOM Level 3 XPath for Microsoft Internet Explorer. It allows to use XPath with a plain-vanilla HTML. Looks interesting. I don't work with HTML DOM for a long time, but thinking about it now I realize I can do just nothing without XPath!
This tool is undeservedly forgotten, but frequently asked and usually hard to find (somehow it's constantly moving around MSDN breaking the links). I'm talking about "Internet Explorer Tools for Validating XML and Viewing XSLT Output". IE out of box doesn't allow you to validate XML, the only way is to write some script. Also
when you open an XML document with attached XSLT stylesheet in IE you cannot view the result of an XSL Transformation, instead View Source shows source XML. These regrettable omissions make it hard to work with schemas and XSLT with bare IE.
Enter "IE Tools for Validating XML and Viewing XSLT Output" - Microsoft add-in for IE, which adds two commands into the browser's context menu - "Validate XML" and "View XSL Output". Very useful, a must to have for any XML developer. And implementation is soooo simple, just few lines of javascript. I wonder - can Microsoft make it into the core Internet Explorer code so it's available in each IE without additional add-in installation?
Well, of course the breaking news today are all about recently launched MSDN XML Developer Center. Should admit I've been checking http://msdn.com/xml several times a day last weeks :) At last it's up and it looks just great! Somebody said it's like blessing for XML. Kinda true. Of course the Dev Center has dedicated RSS feed - http://msdn.microsoft.com/xml/rss.xml - subscribe now. It's overwhelming to see a link to my blog in the front page too! WOW, now I should write only smart stuff.
Chartered for a year, the group will analyze and develop use cases and measurements for alternate encodings of XML. Its goal is to determine if serialized binary XML transmission and formats are feasible.
The XML Binary Characterization Working Group is tasked with gathering information about uses cases where the overhead of generating, parsing, transmitting, storing, or accessing XML-based data may be deemed too great for a particular application, characterizing the properties that XML provides as well as those that are required by the use cases, and establishing objective, shared measurements to help judge whether XML 1.x and alternate (binary) encodings provide the required properties.
Too bad. I was hoping that won't happen and now I only hope they will decide that's bad idea and interoperability costs more than "overhead of parsing". Dare well argued Binary XML is evil here and I only subscribe to the views he quotes.
Dare is looking for suggestions on what the tagline of the MSDN XML Dev Center (which is about two weeks from being launched) should be. I stink on naming and have almost nothing to suggest. Anyway, here are my document-centric-minded slogans:
Marking up the world
The universal data format
The language information speaks
Lingua franca of the information world
Personally I'd vote for Dare's "The language of information interchange".
Speaking of talking about unreleased technologies. Here is MHO: basically I would prefer to see more "early bird" articles and may be even releases, orienting and leading us devs on what's cooking inside the house and how it'll smell. That's important to know to build personal learning curve and usually very interesting. With usual disclaimers about volatile nature of a subject of course. The timespan till release shouldn't be too big of course. And material sould be more theory-oriented, not implementation-oriented. But still I agree that released stuff is a way more important to cover than "glimpses".
And to get us to speed up 8 BizTalk 2004 MSDN webcasts are arranged between March 2 and March 5!
Here is the first developer treat: As part of the launch there will be an MSDN BizTalk Server Developer Blitz with no less than eight web casts packed with information from 3/2 to 3/5. These sessions are developer orientated, full of demos and guarranteed to get you up to speed. Get your own mini-Teched on BizTalk Server for the attractive price of $0 and delivered to you in the comfort of your office/home on the same week we launch the product. Don't forget to register now - these sessions will likely full up fast.
Well, I'm not. Patenting software ideas is stupid thing, but that's a matter of unperfect reality we live in. Everything is patented nowadays, right up to the wheel. So if Office XML is gonna be patented I prefer it's being patented by Microsoft. After all they are not interested to close it (aka make it die), instead they made Office schemas Royalty-Free. And one more reason - I'm sure all we don't want to find ourself one day rewriting all Office-based solutions just because of another Eolas scrooge case or even to pay for out-of-blue-license to some other litigious bastards.
That's all sounds reasonable if that's really defensive patenting though, otherwise - be prepared.
I'm strongly on opposite side. Accepting malformed XML - what a heresy! My understanding of Postel's Law a bit differs. "Liberal" in "be liberal in what you accept from others" means different formats/versions/encodings, possibly obsolete and rarely used, but by no means malformed/broken/compromised.
Just for your fun - I've found the song in usenet archives. Here it is:
From: jenglish@crl.com (Joe English)
Newsgroups: comp.text.sgml
Subject: A Song
Date: 24 Oct 1994 19:05:27 -0700
Organization: Helpless people on subway trains
Lines: 51
Message-ID: <38hp57$1r6@crl.crl.com>
NNTP-Posting-Host: crl.com
[ Allegro, with vigor ]
Well, if you can't do it with <!LINKTYPE ...>,
And features of SGML,
And if you can't hack it in HyTime,
No sweat! It's in DSSSL!
DSSSL!
DSSSL!
It's really cool!
A useful tool!
It's DSSSL!
"So tell me then, what does it look like?"
Afraid I can't -- nobody knows!
I guarantee you're gonna love it,
Just wait and see, that's how it goes.
DSSSL!
DSSSL!
It's like a dream!
It's based on Scheme!
It's DSSSL!
The World-Wide-Web's gotta have stylesheets,
Or HTML's going to burst.
Will DSSSL come and save us
(Unless Netscape gets to it first)?
DSSSL!
DSSSL!
Never fear,
It's almost here!
It's DSSSL!
So -- if -- FOSI's are driving you batty,
And PDF isn't enough,
This standard will solve all your problems
(But it isn't finished yet. Tough.)
DSSSL!
DSSSL!
It's amazingly great
But you'll just have to wait
For Dee-ess-ess-ess-ellllllll!
--Joe English
jenglish@crl.com
Reading last Aaron Skonnard's installment in MSDN Mag I cannot resist to note that his explanation of whitespace handling in XSLT is not actually true. Or to put it this way - it's true only for Microsoft's XSLT implementations in default mode.
Here is what Aaron says:
Before an XSLT processor executes a transformation against a given source document, it first strips all white space-only text nodes from both documents.
It might be new for some Microsoft-oriented XSLT users, but XSLT spec explicitly says that whitespace should be preserved in source XML tree by default. Yes, even insignificant one aka whitespace-only text nodes. This is how all conforming XSLT processors should actually behave. MSXML and XslTransform are only notable exceptions. The explanation of this spec violation is that the process of whitespace stripping is done at tree-building stage and both XSLT engines have no control over it. Indeed, by default both XmlDocument and XPathDocument do strip all insignificant whitespace. And some of us seems to be so get used to it that even claim this is how XSLT should work. That's not true.
XSLT processors don't strip insignificant whitespace from source XML, that's input tree builders (MSXML's DOMDocument, XmlDocument and XPathDocument) by default do that. And if you happens to transform XmlDocument, which has been loaded with PreserveWhitespace property set to true or XPathDocument, which has been loaded with XmlSpace.Preserve argument in the costructor call you might be badly surprised. XSLT stylesheet disregarding insignificant whitespace is not a robust one, because it depends in a very fragile way on XSLT processor's environment. Not to mention using other XSLT processors such as Saxon or Xalan.
A loud example of such bad XSLT programming style is usually becomes apparent when using <xsl:apply-templates/> and position() function together. Consider the following XML document:
And here is another beast for XML bestiary I've created a year ago, but forgot to publish. I'm not sure may be someone did that already, the idea and implementation are really trivial. It's XmlNodeNavigator, which is XPathNavigator over XmlNode (as a subtree) in XmlDocument. It allows to navigate over a subtree in DOM as if it's independent XML document. The main goal of the XmlNodeNavigator is to enable XSL transformation of a portion of XmlDocument without creating temporary XmlDocument containing that portion of data.
Every XSLTers moving from MSXML to .NET usually get stuck with that. In MSXML one usually applies transformation to a node, defining by this the context XSLT operates on. Whenever you want to process only a piece of XML, just run tranformNode() on the node, which encapsulates that piece of data and all XSLT will see then is just that piece of XML, not the whole tree. In .NET though that won't work as XslTransform class applies transformation to the document as a whole, no matter which node you have passed as input. MSDN suggests using temporary XmlDocument, which contains fragment of data you want to transform. That solution is really not satisfactory, pure wasting of memory and performance penalty just for the glory of programmer's laziness. Here is where XmlNodeNavigator idea comes into play. It implements XPathNavigator over the subtree and doesn't allow to navigate outside the subtree boundaries thus enabling effective subtree transformations.
Couple of words about the implementation. XmlNodeNavigator leverages XmlDocument's native XPathNavigator internally, but in MoveTo, MoveToFirst, MoveToNext, MoveToPrevious, MoveToRoot and MoveToParent methods it additionally ensures the navigation doesn't go beyound permissible boundaries - out of the given XmlNode and its descendants. Download XmlNodeNavigator from GotDotNet and see sources for more info.
Finally a sample of transforming XML fragment using XmlNodeNavigator. Source XML:
XslTransform xslt = new XslTransform();
xslt.Load("test.xsl");
XmlDocument doc = new XmlDocument();
doc.Load("foo.xml");
//Navigator over first child of document element
XPathNavigator nav =
new XmlNodeNavigator(doc.DocumentElement.FirstChild);
xslt.Transform(nav, null, Console.Out, null);
The result:
<book genre="novel" ISBN="1-861001-57-5">
<title>Pride And Prejudice</title>
</book>
So, the navigator over first book element has been provided to the transformation and all the XslTransform sees at input is only this subtree - book element and its descendants. And that's done with no any interim tree. It would be really nice to see such class in v2 of System.Xml API.
Well, here is a small basic example how to generate WordprocessingML documents basing on templates. Saying "template" I don't mean regular *.dot Word templates, but just WordprocessingML XML document with predefined document/paragraph/run level properties and styles. Having such template document basically all needs to be done is to fill it with real content.
Here is such a template, it's empty Word 2003 document where I defined new style called MyFancyStyle and saved document as XML.
Here is the source of the content - a hypothetical report:
<?xml version="1.0">
<report><link
url="http://www.internettrafficreport.com/main.htm">Internet Traffic Report</link>
reports on the current performance of major Internet routes around the world.</report>
Basically what the stylesheet does? It opens template document, recursively copies all its content till it reaches w:body/wx:sect element. That's considered to be entry point for the content. Then stylesheet runs usual processing of the actual content in the source document, applying MyFancyStyle to the paragraph and after that copies wx:sectPr. Not rocket engineering indeed.
And finally here is how the result looks like. Note, real content is styled by MyFancyStyle style defined in the template.
Here is another beast for XML bestiary I've created yesterday just for fun to encapsulate commonly used functionality in an efficient way. It's XmlTransformingReader class. The idea is extremelly simple: XmlTransformingReader is XmlReader implementation, which encapsulates arbitrary XSL Transformation of input XML stream. Or to put it in another way - XmlTransformingReader reads input XML stream, transforms it internally using provided XSLT stylesheet and allows the resulting XML stream to be read from itself. For code-minded geeks here is the implementation:
public class XmlTransformingReader : XmlReader {
private XmlReader _outReader;
#region Constructors
public XmlTransformingReader(string source, string transformSource) {
XPathDocument doc = new XPathDocument(source);
XslTransform xslt = new XslTransform();
xslt.Load(transformSource);
_outReader = xslt.Transform(doc, null, new XmlUrlResolver());
}
//...Dozen other constructors ...
#endregion
#region XmlReader impl methods
public override int AttributeCount {
get { return _outReader.AttributeCount;}
}
public override string BaseURI {
get { return _outReader.BaseURI; }
}
//The rest 20+ XmlReader methods/properies implemented in the same way
}
Probably even too simple, but still quite usable.
It allows to modify XML on the fly, but of course it's not streaming plumbing as it embeds XSLT. Such reader can be useful to encapsulte complex XML transformations into a single XmlReader. Sure it allows also to implement easily simple local XML modifications, traditionally performed at SAX/XmlReader level, such as renaming/filtering nodes, converting attributes to elements etc., but I urge you to keep streaming processing. The main goal of XmlTransformingReader is to enable complex XML modifications, such as involve sorting, grouping, anyone that cannot be done in forward-only non-caching way XmlReader works. It's time for a sample. Here is how one can read three most expensive items from an inventory list :
XmlReader xtr = new XmlTransformingReader("inventory.xml", "filter.xsl");
//That's it, now let's dump out XmlTransformingReader to see what it returns
XmlTextWriter w = new XmlTextWriter(Console.Out);
w.Formatting = Formatting.Indented;
w.WriteNode(xtr, false);
xtr.Close();
w.Close();
I've uploaded XmlTransformingReader sources to GotDotNet.com user samples section and surprisingly it was downloaded already 81 times in first 10 hours. Well, honestly that's not something new, all this stuff's able to do is to save couple of lines for an experienced developer, but my hope is it will be used by average users and will help them to avoid so common and so ugly piping of transformations with interim XmlDocument. Or may be it's just an exercise in advertising during these boring days. :)
XML Information Set, second edition became Proposed Rec. Mostly the Infoset is updated to reflect the fact it's going to be not only 1.0 version of XML in the near future. So major changes look like "XML 1.0". Plus emerging Namespaces in XML 1.1 adds namespace undeclaring to the infoset.
Just discovered that WordML to XSL-FO stylesheet does exist already. Well, I was talking about it since May, so no surprise somebody more effective than me just made it done. It's Antenna House guys, developers of the best XSL-FO formatter in the market. Check out this page. Sounds reasonable, they transform elements, say w:p to fo:block, expand styles and extract images to external files (via extension function written in java for Saxon).
But wait a minute, the price is $980! No evaluation version... Gosh...
Well, seems like images are one of the WordprocessingML trickiest parts, at least for me. Here are humble results of my investigations and experiments in embedding images into XSLT-generated WordprocessingML documents.
Images in WordprocessingML are represented by w:pict element, which holds both VML and binary data (obviously Base64 encoded). VML only or VML and binary . Even if you are embedding just plain binary gif, some VML elements still needed. So VML is your friend.
The "Overview of WordprocessingML" document only gives a couple of samples, saying that "A discussion of VML is outside the scope of this document". Great. Generally speaking VML is somewhat esoteric stuff for me. Here is why. All we've seen funny import in office.xsd schema document:
Somebody at Microsoft does have vml.xsd in C:\SCHEMAS directory, but unfortunately they forgot to put it into "Microsoft Office 2003 XML Reference Schemas" archive. Then many elements in office.xsd have such annotation "For more information on this element, please refer to the VML Reference, located online in the Microsoft Developer Network (MSDN) Library." You can find VML reference at MSDN here. But it's dated November 9, 1999 so don't expect XSD schema there.
First element, v:shapetype, apparently defines some shape type (note, I'm complete VML ignoramus)
. I found it to be optional. Second one, w:binData, assigns an iternal name to the image in wordml:// URI form and holds Base64 encoded image. Third one, v:shape, is main VML building block - shape.
v:shape defines image style (e.g. size) and refers to image data via v:imagedata element.
So, to generate such structure in XSLT one obviously needs some way to get Base64 encoded image. XSLT doesn't provide any facilities for that, so one easy way to implement it is extension function. In the example below I'm using extension implemented in msxsl:script element. That's just for simplicity, if I wasn''t wrinting a sample I'd use extension object of course. Btw, I believe it's good idea to provide such extension function in EXSLT.NET lib.
Finally here is a sample implementation for .NET XSLT processor. Source XML:
Finally I got a time to fully implement support for XmlResolver in XInclude.NET (see Extending XInclude.NET). Wow, this stuff looks so powerful! A friend of mine is writing an article about using resolvers in System.Xml, so no spoilers here, all I wanted is to illustrate what can be done now using XInclude.NET and custom XmlResolver.
So, somebody wants to include a list of Northwind employees into a report XML document. Yeah, directly from SQL Server database. Here comes XInclude.NET solution: custom XmlResolver, which queries database and returns XmlReader (via SQLXML of course).
report.xml:
<report>
<p>Northwind employees:</p>
<xi:include
href="sqlxml://LOCO055/Northwind?query=
SELECT FirstName, LastName FROM Employees FOR XML AUTO"
xmlns:xi="http://www.w3.org/2001/XInclude"/>
</report>
sqlxml:// URI schema is a proprietary schema, supported by my custom XmlResolver. LOCO055 is my SQL Server machine name, Northwind is the database I want to query and query is the query. Here goes SqlXmlResolver class:
public class SqlXmlResolver : XmlUrlResolver {
static string NorthwindConnString =
"Provider=SQLOLEDB;Server={0};
database={1};Integrated Security=SSPI";
public override object GetEntity(Uri absoluteUri,
string role, Type ofObjectToReturn) {
if (absoluteUri.Scheme == "sqlxml") {
//Extract server and database names from the URI
SqlXmlCommand cmd =
new SqlXmlCommand(string.Format(NorthwindConnString,
absoluteUri.Host, absoluteUri.LocalPath.Substring(1)));
cmd.RootTag = "EmployeesList";
//Extract SQL statement from the URI
cmd.CommandText =
absoluteUri.Query.Split('=')[1].Replace("%20", " ");
return cmd.ExecuteXmlReader();
} else
return base.GetEntity(absoluteUri, role, ofObjectToReturn);
}
}
}
Not really a sophisticated one, just checks if the URI schema is sqlxml:// and then extracts the data from the URI and runs the query via SQLXML plumbing.
Then we can read report.xml via XIncludingReader:
XIncludingReader reader = new XIncludingReader("report.xml");
reader.XmlResolver = new SqlXmlResolver();
XPathDocument doc = new XPathDocument(reader);
...
That magic is supported by XInclude.NET version 1.2, which I'm going to release right now. Well, actually I don't think including SQL into URI was a good idea, but bear in mind, that's just a dummy sample to illustrate the power of XmlResolvers. Enjoy!
It turned out people do use XInclude.NET already and even more - now they want to extend it! First one user wanted to be able to resolve URIs himself, via custom XmlResolver. I did that yesterday (download XInclude.NET v1.2beta if you're interested in such behaviour), but I didn't go beyound call to XmlResolver.ResolveUri().
New user case is about including XML documents generated on-the-fly. To avoid any interim layers like temporary files or HTTP calls this can be implemented by further unrolling of XmlResolver support - now to call XmlResolver.GetEntity() method on custom resolvers. This way custom XmlResolver may generate XML on the fly and return it say as XmlReader for best performance. Sounds interesting, will do.
In XSLT 1.0 all output is XML. A transformation creates a result tree, which can always be serialized as either an XML document or a well-formed document fragment. In XSLT 2.0 and XQuery the output is not a result tree. Rather, it is a sequence. This sequence may contain XML; but it can also contain atomic values such as ints, doubles, gYears, dates, hexBinaries, and more; and there's no obvious or unique serialization for these things. For instance, what exactly are you supposed to do with an XQuery that generates a sequence containing a date, a document node, an int, and a parentless attribute? How do you serialize this construct? That a sequence has no particular connection to an XML document was very troubling to many attendees.
Looking at it now, I'm seeing that perhaps the flaw is in thinking of XQuery as like XSLT; that is, a tool to produce an XML document. It's not. It's a tool for producing collections of XML documents, XML nodes, and other non-XML things like ints. (I probably should have said it that way last night.) However, the specification does not define any concrete serialization or API for accessing and representing these non-XML collections. That's a pretty big hole left to implementers to fill.
Hmmm, that's kinda confusing. Let's see. Formally speaking what XQuery produces is one(zero) or more instances of XPath 2.0 and XQuery 1.0 Data Model (DM), which then are subject to the serialization process, defined in XSLT 2.0 and XQuery 1.0 Serialization spec. The problem (typo?) is that XQuery spec says:
Serialization is the process of converting a set of nodes from the data model into a sequence of octets...
and thus doesn't mention what happens with items in the resulting DM, which are not nodes, but atomic values. I believe that's a mistake in XQuery spec, because XSLT 2.0 and XQuery 1.0 Serialization handles that pretty well - it defines serialzation of DM including all it can contain, particularly, atomic values are converted to their string representations.
The whole morning I'm trying to get rid of the idee fixe of writing XmlReader/XmlWriter based XML updater. The aim is to be able to update XML without loading it to DOM or even XPathDocument (which as rumored is going to be editable in .NET 1.2). Stream-oriented reading via XmlReader, some on-the-fly logic (quite limited though - filtering, values modifying) in between and then writing to XmlWriter. Cache-free, forward-only just as XmlReader is. If you're aware of SAX filters you know what I'm talking about. But I want the filtering/updating logic (hmmm, did you note I'm avoiding "transforming" term?) to be expressed declaratively.
Obviously the key task is how to express and detect nodes to be updated. If we go XPath patterns way we generally can get limited to single update per process, due to forward-only restriction. Subsetting XPath can help though. The only way to evaluate XPath expression without building tree graph is so-called ForwardOnlyXPathNavigator aka XPathNavigator over XmlReader. This beast is mentioned sometimes in articles, but I'm not aware of any implementation availble online yet. Btw, a friend of mine did that almost a year ago, may be I can get him to publish it. As per name it limits XPath to forward axes only (the subset seems to be the same as Arpan Desai's SXPath) and of course can't evaluate more than one absolute location path. But it can evaluate multiple relative location pathes though, e.g. /foo/a, then b/c in
<foo>
<a>
<b>
<c/>
</b>
</a>
</foo>
tree. Another way to express which nodes are to be updated is [NodeType][NodeName] pattern, probably plus some simple attribute-based predicates. Sounds ugly, I know, but limiting scope to a node only fits better to forward-only way I'm trying to think.
Another problem is how to express update semantics. I have no idea how to avoid inventing new syntax. Something like:
I have no idea if it's really feasible to implement though. All unmatched nodes should be passed untouched forward to the result, on the matched one the update logic should be evaluated and then go on.
Yes, I'm aware of STX, but I feel uneasy about this technology. Too coupled to SAX (CDATA nodes in data model ugh!), assignable variables etc. No, I'm talking about different thing, even more lightweight one (thought even more limited).
The day started with bad news from W3C - XInclude 1.0 has been whithdrawn back to Working Draft maturity level. Actually Last Call WD, but anyway the step backward. The main reason is most likely primarily architectural one - seems like URI syntax with XPointers in fragment identifier part has been considered too revolutionary and now they broke it up to two separate attributes - href attribute contains URI or the resource to include and xpointer attribute - XPointer identifying the target portion of the resource. So instead of
Another new feature - now it's possible to control HTTP content negotiation via new accept, accept-charset and accept-language attributes. Well, again quite dubious stuff. And possible security hole as Elliottepointed out.
Also XInclude namespace is now "http://www.w3.org/2003/XInclude", but old one should be supported somehow too.
Anyway I have to update XInclude.NET library now. No big changes fortunately, so I'm going to release it in a couple of days.
5 November 2003: W3C is pleased to announce the advancement of Extensible Markup Language (XML) 1.1 and Namespaces in XML 1.1 to Proposed Recommendations. Comments are welcome through 5 December. XML 1.1 addresses Unicode, control character, and line ending issues. Namespaces 1.1 incorporates errata corrections and provides a mechanism to undeclare prefixes.
For those from another planet, here is a summary of changes:
Namespaces can be undeclated now, using xmlns:foo="" syntax
Change in allowed--in-names-characters pholisophy - in XML 1.1 everything that is not forbidden (for a specific reason) is permitted, including those characters not yet assigned
Two more linefeed characters - NEL (#x85) and the Unicode line separator character, #x2028
Control characters from #x1 to #x1F are now allowed in XML 1.1 (provided they are escaped as character references)
One more logger with clunky text-based log file format and appropriate plumbing (object model, writer, parser and viewer) were written by me this week. Format was defined by customer and it was non disputable unfortunately. As for me it's just ugly. Why not use XML as log format? Pros: trivial writing/parsing, portability, readability, simplicity.
Constras: everybody seems to think it's unfeasible due to XML well-formedness and hence root element end tag problem - to append records you need to seek an appropriate place hence to parse the whole XML document. That's true for XML documents, but what about XML fragment?
XML fragment is actually external general parsed entity in XML 1.0 specification terms - it's freestanding fragment of XML, which can be incorporated into an XML document by entity reference, but it's still useful on its own - one can append elements to it (and because it's not XML document, root-level well-formedness rules don't apply to it, so one can just append elements to the end of file, without necessity to parse the whole log file) and then read such log file by XmlTextReader, which [thankfully to .NET developers] supports XML fragments (see "Reading XML Fragments with the XmlTextReader").
So here is small proof-of-concept example:
Writing to log:
class Test {
static void Main(string[] args) {
using (FileStream fs = File.Open("log.xml",
FileMode.Append, FileAccess.Write, FileShare.Read)) {
XmlTextWriter writer = new XmlTextWriter(fs, Encoding.ASCII);
for (int i=0; i<3; i++) {
writer.WriteElementString("item", "",
DateTime.Now.ToString());
writer.WriteWhitespace("\n");
}
writer.Close();
}
}
}
class Test {
static void Main(string[] args) {
using (FileStream fs = File.OpenRead("log.xml")) {
XmlParserContext context = new XmlParserContext(
new NameTable(), null, null, XmlSpace.Default);
XmlTextReader reader = new XmlTextReader(fs,
XmlNodeType.Element, context);
while (reader.Read()) {
if (reader.NodeType == XmlNodeType.Element) {
Console.WriteLine("Element: {0}, Value: {1}",
reader.Name, reader.ReadElementString());
}
}
}
}
}
And result is:
D:\projects\Test2\bin\Debug>Test2.exe
Element: item, Value: 7/22/2003 11:15:42 AM
Element: item, Value: 7/22/2003 11:15:42 AM
Element: item, Value: 7/22/2003 11:15:42 AM
Element: item, Value: 7/22/2003 11:16:12 AM
Element: item, Value: 7/22/2003 11:16:12 AM
Element: item, Value: 7/22/2003 11:16:12 AM
I like it. Comments?
Doing web page
design on your own can be as successful as your
web site design coming from a professional
web designer but you'll want to make sure that your
web site design is user-friendly and clean before worrying about bells and
whistles.
XSLT 2 appears to be based on user concerns and problems.
Apart from this character encoding feature (which is also useful in non
xml outout, eg outputting TeX commands in text output) It also has a lot
of help for grouping and of course user xslt defined portable extension
functions.
If only the same could be said for Xpath2....
The world is getting better. And the Word too! Word 2003 Beta2 now understands not only those *.doc files, but XML also. It's all as it should be in open XML world (what makes some people suspicious): there is WordML vocabulary, its schema (well documented one, btw) is available as part of Microsoft Word XML Content Development Kit Beta 2. Having said that it's obvious to go on and to assume that Word documents now may be queried using XPath or XQuery as well as transformed and generated using XSLT. Isn't it fantastic?
So here is "Hello Word!" XSLT stylesheet, which generates minimal, while still valid Word 2003 document:
That <?mso-application progid="Word.Document"?> processing instruction is important one - that's how Windows recognizes an XML document as Word document. Seems like they parse only XML document prolog looking for this PI. Good idea I think.
Now let's try something more interesting - transform some XML document to formatted Word document, containing heading, italic text and link. Consider the following source doc:
Finally. Gudge has posted his C# implementation of XInclude CR. It's XmlReader-based, with XPointer support, fairly elegant, simple and very interesting. Especially to compare with GotDotNet XInlcude.NET impl.
After a quick look I can say of course it's much more elegant than my implementation. More structured and well-designed, while probably less caring about details. Unfortunately to me it seems like Gudge has omitted xml:base attribute generation problem, I was hoping he'll solve in a usual magic way. That's the only problem left in XInlcude.NET project before we can ship first alpha version.
What's the problem? When an element is included from another document with different base URI, the xml:base attribute should be added/substituted to this element to preserve its (and its descendants) base URI.
Sounds simple. When top-level included element item is read through XIcludingReader, xml:base attribute should be exposed if it doesn't exist else its value should be modified. It requires probably some state fiddling in MoveToNextAttribute() and other attributes-related methods. My first idea is to check when MoveToNextAttribute() returns false and then switch the reader to some new EXPOSING_XML_BASE state to emulate xml:base attribute. Anyway I'll try to implement it tomorrow.
The article's example looks quite provocative - generating of HTML from two XML sources (RSS feeds). I bet the first thought of many devs would be "Come on, that's XSLT's job for ages!". Indeed, even 3-years old XSLT 1.0 can easily perform such transformation at a very newbie level, so it's fairly enough to ask - "Why do we need one more language?".
Perform queries on structured documents and collections of documents, such as technical manuals, to retrieve individual documents, to generate tables of contents, to search for information in structures found within a document, or to generate new documents as the result of a query.
Sounds similar, huh?
So this is really a gray area, where XSLT and XQuery do overlap. The task of generating new document based on a source document may be thought either as source2result transformation or as building new document basing on a source querying. And I don't see what's wrong with that, both languages (XSLT2.0 and XQuery1.0 to be technically correct) may greatly complement each other. Many people don't like XSLT just because its XML-based syntax, many others don't take its rule-based nature and of course there is an horde hunger to return to their habitual procedural programming style. Many of them should be happy with XQuery. Not bad?
Keeping provocative line I would ask - isn't XQuery strongly typed subset of XSLT2?
While reading the article two things caught my eye - usual negation of SAX usefulness and another API quirk, which should be remembered.
Being particlularly fan of XML pull processing I nevertheless don't understand why one may completely deny usefulness of push processing. I like both push and pull, why to limit myself to only one? Pull is good when application knows what it wants to pull out, and push is good for generic rule based processing.
"All the functions of a SAX parser can be implemented easily and more effectively by using an XML reader."
I'm still not convinced, in next version of XmlReader API may be, but not now. Consider MSDN example of attributes to elements convertor, based on XmlTextReader. Hmm, state machinery, 4 overrided members... And here is SAX version:
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class Attrs2ElementsFilter extends XMLFilterImpl {
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
AttributesImpl newAttributes = new AttributesImpl();
super.startElement(namespaceURI, localName,
qualifiedName, newAttributes);
for (int i = 0; i < atts.getLength(); i++) {
super.startElement("", atts.getLocalName(i),
atts.getQName(i), newAttributes);
super.characters(atts.getValue(i).toCharArray(), 0,
atts.getValue(i).length());
super.endElement("", atts.getLocalName(i),
atts.getQName(i));
}
}
}
Note that although the signature of one of the XmlValidatingReader constructors refers generically to an XmlReader class as the underlying reader, that reader can only be an instance of the XmlTextReader class or a class which derives from it. This means that you cannot use any class which happens to inherit from XmlReader (such as a custom XML reader). Internally, the XmlValidatingReader class assumes that the underlying reader is an XmlTextReader object and specifically casts the input reader to XmlTextReader. If you use XmlNodeReader or a custom reader class, you will not get any error at compile time but an exception will be thrown at run time.
XPointer goes to Recommendation today. Remember XPointer? It's about "pointing", i.e. identifying of XML parts or fragments. Well, after monsntrous XPath2 specs XPointer one looks like a miniature work. (It reminds me XPath1, which was about 30 pages also).
XPointer (funny enough, no version defined for the language) consists of 3 quite small documents:
XPointer Framework, which defines basic semantics and syntax of XML addressing/fragment identifying.
element() scheme, funny XPath-like syntax for pointing to elements in XML, e.g. "element(intro/3/1)" - which identifies first child of third child of the element with "intro" ID.
xmlns() scheme, for dealing with namespaces in pointers.
Editors are just living legends: Norman Walsh, Jonathan Marsh, Eve Maler and Paul Grosso. They decided to leave the most powerful and (therefore?) contradictory xpointer() schema out of this release, it's still frozen at WD stage. Implemeters feels relief today probably.
Anyway, happy sailing in XML ocean, XPointer. There are many against you, but you can make it.
As a matter of fact main thing I wanted to say is that this event effectively means XInclude, which greatly depends on XPointer and still stays in Candidate Rec bed apparently may be also released very soon. So it's really right time to push my (our now) GotDotNet XInclude.NET
project. In fact that involves XPointer implementation also, so there is a big pile of design and coding here. We desperately need more volunteers, I urge everybody interested in free implementation of XInclude for .NET platform to participate.
John D.: Or, you can hack it by replacing apostrophes with a read more
Anonymous: It would explain all the bugs... read more
The D00D: Oh LOL, XSLT. I wondered where the conditionals were, and read more
Sam: Does this wok with custom XSD . I have custom read more
Anonymous: Check this: http://msdn.microsoft.com/en-us/library/system.collections.sortedlist.contains.aspx Towards the middle of the page you read more
Buzzer: As for the & ampersand issue, simply call HTTPUtility.HTMLEncode in read more
Victor Conesa: Hi Oleg, I'm using the wml2xslt.exe to generate reports in read more
Ethyl Kruk: Have you read any of Cem Kaner's books? He is read more
steve oak: yes, tried and it works! you know what? I even read more
Tim: @Martin Kool Thanks for the registry-hint read more

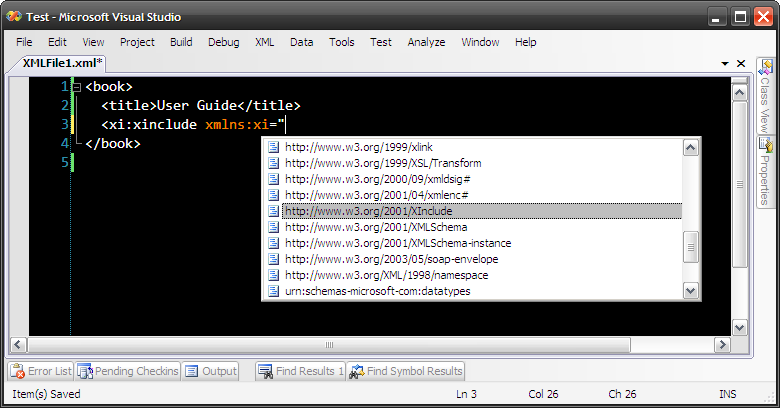
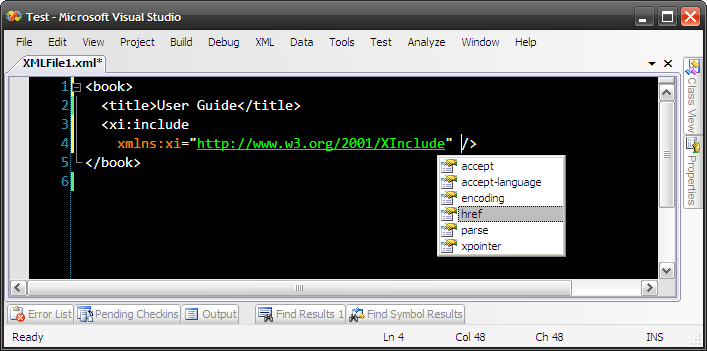
 Here is a small quick release.
Here is a small quick release. 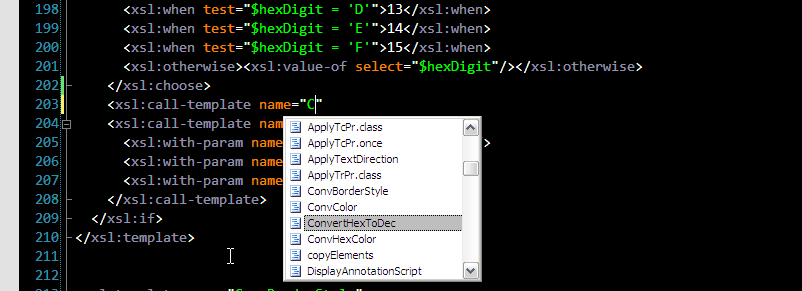
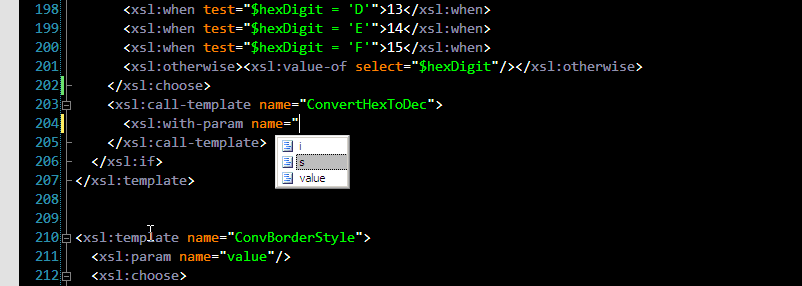
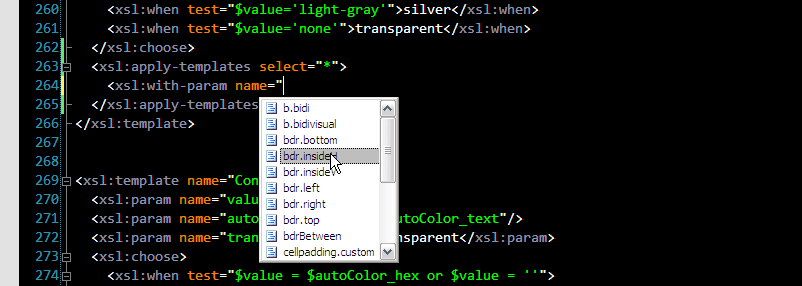
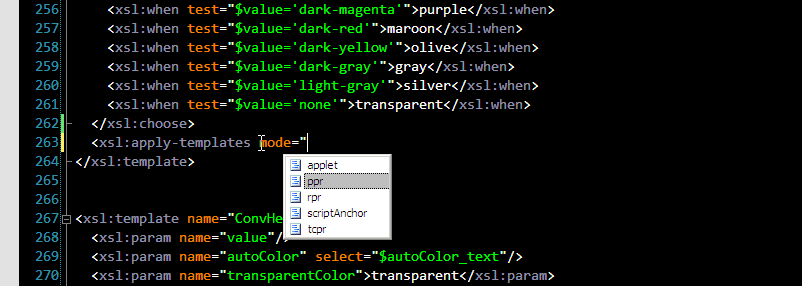
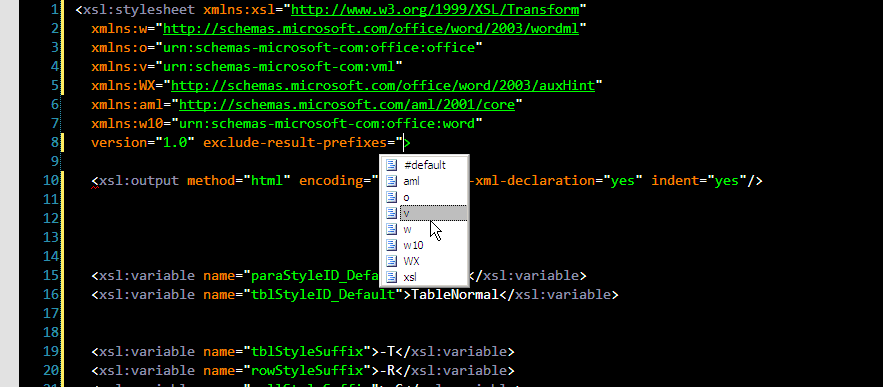
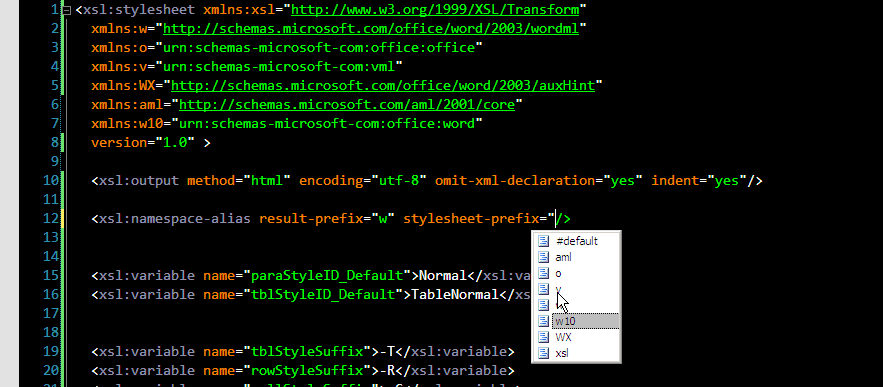
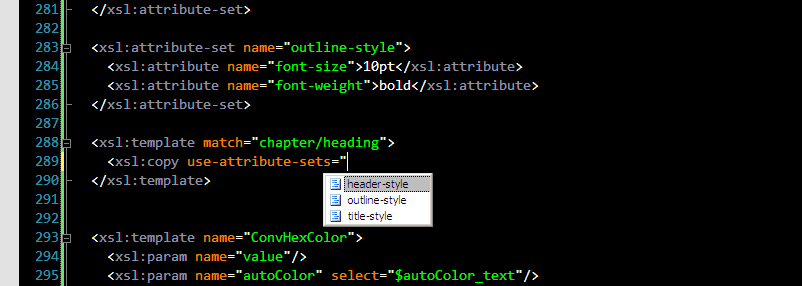

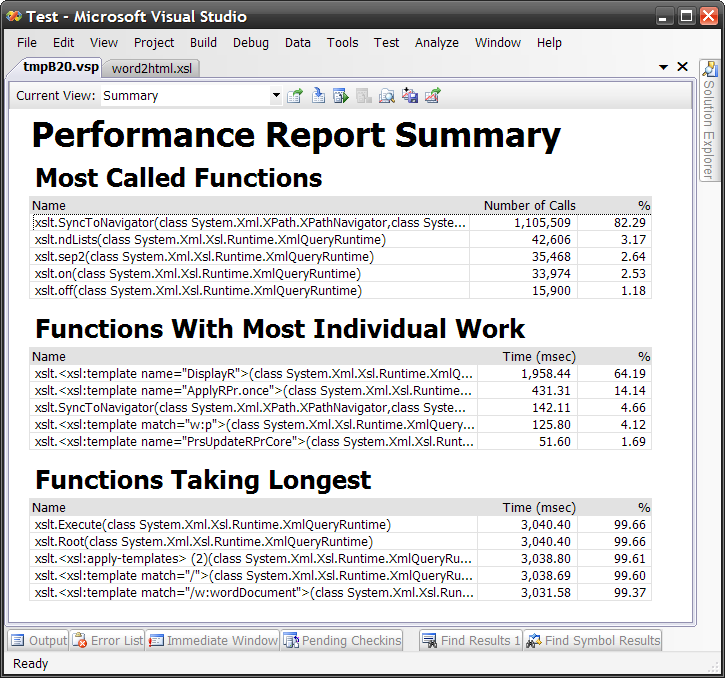
 My goal was to make F5/Ctrl+F5 working intuitively right - when you work on XSLT Library project F5 should run project with debugger and Ctrl+F5 - without. When you have more that one stylesheet it's nice time saving feature, not to mention that start debugging command finally starts debugger
My goal was to make F5/Ctrl+F5 working intuitively right - when you work on XSLT Library project F5 should run project with debugger and Ctrl+F5 - without. When you have more that one stylesheet it's nice time saving feature, not to mention that start debugging command finally starts debugger 


 Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets.
Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets. I updated
I updated 
 So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas").
So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas").  I was writing about
I was writing about  I completely forgot that I still have one Visual Studio 2005 Team Suite with MSDN Premium Subscription gift card to give away. And it expires 12/31! Oh boy, what do I do now??? So for the next 2 weeks I'll be holding the "The Coolest XML Project Contest".
I completely forgot that I still have one Visual Studio 2005 Team Suite with MSDN Premium Subscription gift card to give away. And it expires 12/31! Oh boy, what do I do now??? So for the next 2 weeks I'll be holding the "The Coolest XML Project Contest". ISO published
ISO published .gif)
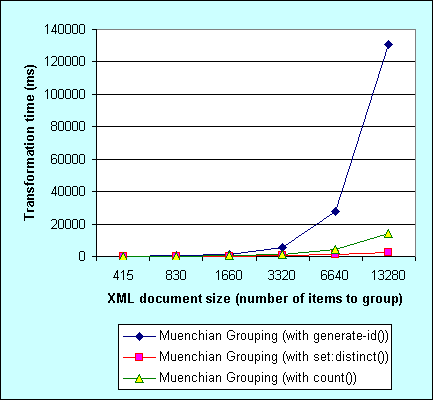
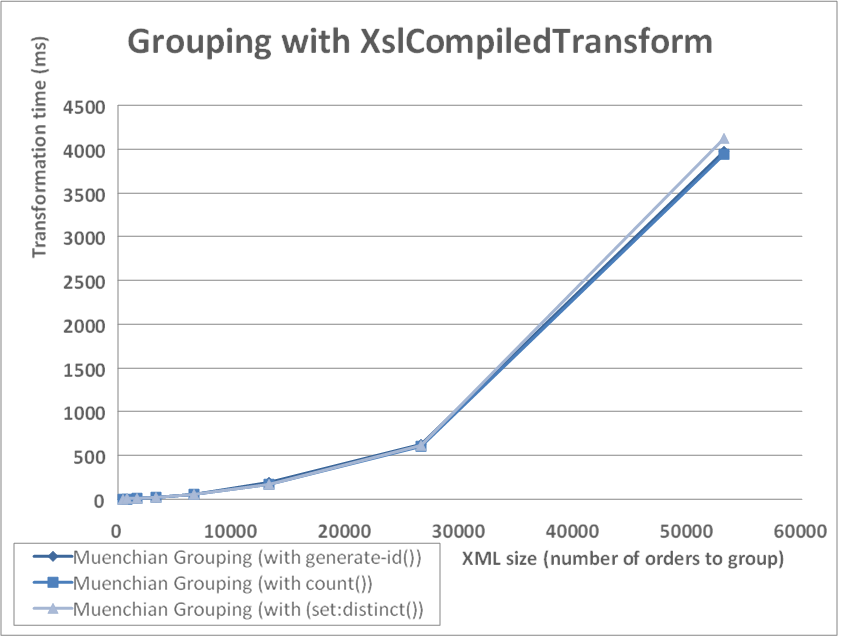

 I've uploaded HTML versions of the
I've uploaded HTML versions of the  Ok, I'm back. I have updated
Ok, I'm back. I have updated 


 It's XML's birthday today - the very
It's XML's birthday today - the very  IBM is
IBM is 


{kind=link}
{kind=link}
Recent Comments