Recently in Office Category
 I was cleaning up my backyard and found this control I never finished. So I did. Here is Word 2003 XML Viewer Control v1.0 just in case somebody needs it. It's is ASP.NET 2.0 Web server control, which allows to display arbitrary Microsoft Word 2003 XML documents (aka WordML aka WordprocessingML) on the Web so people not having Microsoft Office 2003 installed can browse documents using only a browser. I was cleaning up my backyard and found this control I never finished. So I did. Here is Word 2003 XML Viewer Control v1.0 just in case somebody needs it. It's is ASP.NET 2.0 Web server control, which allows to display arbitrary Microsoft Word 2003 XML documents (aka WordML aka WordprocessingML) on the Web so people not having Microsoft Office 2003 installed can browse documents using only a browser.
The control renders Word 2003 XML documents by transforming content to HTML preserving styling and extracting images. Both Internet Explorer and Firefox are supported. Word 2003 XML Viewer Control is Web version of the Microsoft Word 2003 XML Viewer tool and uses the same WordML to HTML transformation stylesheet thus providing the same rendering quality. The control is free open-source, download it here, find documentation here. I'm doing interesting trick with images in this control. The problem is that in WordML images are embedded into the document, so they need to be extracted when transforming to HTML. And I wanted to avoid writing images to file system. So the trick is to extract image when generating HTML (via XSLT), assign it guid, put it into session and generate <img> src attribute requesting image by guid. Then when browser renders HTML it requests images by guid and custom HTTP handler gets them from the session. Having HTTP handler in ASP.NET control posed another problem - how do you register HTTP handler in Web.config automatically? AFAIK there is no out of box solution for the problem, but happily I found a solution that covers major use case. Here is piece of documentation: When you are adding the first Word 2003 XML Viewer Control in your Web project, you should see the following confirmation dialog: "Do you want to automatically register the HttpHandler needed by this control in the web.config?". You must answer Yes to allow the control to register image handler in the Web.config. If don't answer Yes or if you add the control not in Design mode, you have to add the following definition to the Web.config in the <system.web> section:
<httpHandlers>
<add path="image.ashx" verb="*" type="XMLLab.WordXMLViewer.ImageHandler, XMLLab.WordXMLViewer" />
</httpHandlers> Yep. the hint is the Design mode. I'll post about this trick tomorrow. The usage is simple - just drop control and assign "DocumentSource" property (Word 2003 XML file you want to show). I deliberately named this control "Word 2003 XML Viewer Control" to avoid confusion. But I'll update it to support Word 2007 as soon as there is Word 2007 to HTML transformation problem solution. Any comments are welcome. Enjoy.
openxml.biz announced the availability of the OpenXML Writer - open source text editor for creating OpenXML WordprocessingML files (.docx). Supported features include "text formatting options like bold, italic, underline, font color, font name , font size, paragraph justification and text indentation. Basic editing functions like cutting, copying, pasting and spell check are also provided".
Today's news from Adobe: SAN JOSE, Calif. — Jan. 29, 2007 — Adobe Systems Incorporated (Nasdaq:ADBE) today announced that it intends to release the full Portable Document Format (PDF) 1.7 specification to AIIM, the Enterprise Content Management Association, for the purpose of publication by the International Organization for Standardization (ISO). Looks like everybody nowadays wants to be open and ISO standardized. ODF is already ISO standard, OOXML on the way and now PDF joins the club. Btw, Wikipedia article on PDF is definitely wrong (or written by Adobe) - how on earth this fully proprietary document format is called "an open file format created and controlled by Adobe Systems"? Provided the fact that Adobe forced Microsoft to remove "Save as PDF" feature from Office 2007 - because they wanted to charge a fee for it, PDF format clearly cannot be called "open format" - it's proprietary format controlled by Adobe and they wanted a fee from at least one vendor trying to implement it. I don't think that is open format. I'm going to try to change Wikipedia article on PDF to see how it works. I'll report my progress. And at the end one more curious comparison showing how heavily biased Wikipedia is: PDF vs RTF. Both proprietary document formats, published and widely implemented by both commercial and open tools. But guess what: Portable Document Format (PDF) is an open file format created and controlled by Adobe Systems, for representing two-dimensional documents in a device independent and resolution independent fixed-layout document format. and The Rich Text Format (often abbreviated to RTF) is a proprietary document file format developed by Microsoft since 1987 for cross-platform document interchange. Most word processors are able to read and write RTF documents.
With a piece of PDF conversion
software, whether it's an individual license or a larger
PDF server package, you may find that various PDF conversion
options are more useful than you realized and that a PDF
converter can help speed things up around the office.
While OOXML/ODF war starts to heat up, Microsoft published new version of their another document format "Word 2007: Rich Text Format (RTF) Specification, version 1.9": The Rich Text Format (RTF) Specification provides a format for text and graphics interchange that can be used with different output devices, operating environments, and operating systems. Version 1.9 of the specification contains the latest updates introduced by Microsoft Office Word 2007. If somebody forgot, RTF is proprietary but widely supported non-XML document markup format, which looks like this: {\rtf1\ansi{\fonttbl\f0\fswiss Helvetica;}\f0
Hello!\par
This is some {\b bold} text.\par
}
And going on with Word as XSL-FO editor theme - take a look at a brand new tool called foActive <X>Styler:
foActive <X>Styler is a plug-in for Microsoft Word 2003 Professional which allows a user to design and test dynamic document templates right from within the Word authoring environment.
<X>Styler is used to create XSL templates for server-based transformation for high-volume dynamic document print applications such as direct mail, correspondence, invoicing, statements, contracts, and legal forms.
And more:
Writing XSL templates that generate XSL FO output can be a difficult task, one suited for an engineer and not a marketing person. What the industry needed was an easy-to-use tool for designing templates to convert XML to XSL FO using XSL. There are applications that have recently emerged to do just this, however these are standalone applications designed from the ground-up for just this purpose. As such, they can be unnecessarily complex and require specific custom training to master. They expose all the functionality and complexities of XSL to the end-user.
And so foActive designed <X>Styler, merging the most common desktop application in use -- Microsoft Word -- with the difficult to master XSL design. We coupled the whole system to the industry's best XSL FO engine -- RenderX -- to deliver a complete solution for a wide variety of XSL design tasks.
That's what I was talking about all the way.
The price is set at $199, beta program is open. Sounds really cool.
Via Brian Jones we learn that the Ecma International Technical Committee (TC45) has published draft version 1.3 of the Ecma Office Open XML File Formats Standard. This is 4000 pages document specifying new (alternative to Oasis OpenOffice/OpenDocument XML format) Office XML format to be used by Microsoft starting with Office 2007.
As a matter of interest:
- The draft is available in PDF, which was created by Word 2007
- The draft also available in Open XML format itself, which one will be use once Office 2007 Beta 2 is out
- The document is huge and specifies everything down to the "Maple Muffins" border style kinda details
- These guys help MIcrosoft in creating Ecma Office Open XML format: Apple, Barclays Capital, BP, The British Library, Essilor, Intel, Microsoft, NextPage, Novell, Statoil, and Toshiba
Here is one easy way:
- Go to xmllab.net, get free eXml Web server control and modified Microsoft's WordML2HTML XSLT stylesheet, version 1.3.
- Drop eXml control onto a Web form, assign DocumentSource property (WordML document you want to render), TransformSource property(wordml2html-.NET-script.xslt):
<xmllab:eXml ID="EXml1" runat="server"
DocumentSource="~/TestDocument.xml"
TransformSource="~/wordml2html-.NET-script.xslt"/>
- Create new folder to store external images
- In code behind allow XSLT scripting and pass couple XSLT parameters - real path to above image directory and its virtual name:
protected void Page_Load(object sender, EventArgs e)
{
EXml1.XsltSettings = System.Xml.Xsl.XsltSettings.TrustedXslt;
EXml1.TransformArgumentList =
new System.Xml.Xsl.XsltArgumentList();
EXml1.TransformArgumentList.AddParam(
"base-dir-for-images", "", MapPathSecure("~/images"));
EXml1.TransformArgumentList.AddParam(
"base-virtual-dir-for-images", "", "images");
}
Done.
I had to add these two parameters so the WordML2HTML stylesheet could export images there and then refer to exported images in HTML. If you don't pass these parameters images will be exported into current directory - while that's ok when running WordML2HTML transformation in a command line, that's bad idea for ASP.NET environment.
Enjoy!
Almost 2 years ago I published a post "Transforming WordML to HTML: Support for Images" showing how to hack Microsoft WordML2HTML stylesheet to support images. People kept telling me it doesn't support some weird image formats or header images. Moreover I realized it has a bug and didn't work with .NET 2.0. So finally I updated that damn stylesheet. Now I took another Microsoft WordML2HTML stylesheet as a base - that one that comes with Word 2003 XML Viewer tool. I think it's a better one. Anyway, I added to it a couple of templates so images now get decoded and saved externally and headers and footers are processed too (only header/footer for odd pages per section to be precise).
Note: this stylesheet uses embedded C# script to decode images and so only works with .NET XSLT processors, such as XslTransform (.NET 1.1) or XslCompiledTransform (.NET 2.0). You can also run it with nxslt/nxslt2 command line tool. Here is a small demo.
The big news today is of course announced next Office's full deep XML-ization. I've read a dozen of enthusiastic postings already and decided not to bother my readers with another whoohoo-like post from another XML nerd. But what amazed me more than the announce itself (which was predictable) is the overall excitement about the news. Ranging from Scoble to Tim Bray - everybody seems to value ultimate XMLization of the next Office as "big cool news". Not a single critical post - what's the matter with you people? And even more:
I think another version or two after the upcoming Office, binary files will become completely obsolete and forgotten and won't be able to round-trip the latest features.
says Wesner Moise (former Excel developer at Microsoft and overall smart guy).
Now that's amazing...
Altsoft N.V. has announced a relase of the Xml2PDF formatting engine version 2.3, now supporting WordML. Altsoft Xml2PDF is a .NET based formatting engine for converting
various XML-based formats to PDF. It supports XSL-FO, SVG, XHTML,
WordML and
XML+XSLT as an input and generates PDF as an output. The prices are from $49 for the Workstation version to $1599 for the API version. Free evaluation versions are available.
Dino Chiesa of Microsoft shows how to generate dynamically WordML documents using Java and XSLT. Yep, that's not a typo, Microsoft, WordML and Java. XML serves as peacemaker again. And he even provides a working JSP demo. Cool.
As Evan Lenz pointed out, O'Reilly put Chapter 2 ("The WordprocessingML Vocabulary") of the "Office 2003 XML" book online. Here it is (88 pages pdf). Excellent introduction to WordML. Those who want to learn WordML - go read it (or buy the book).
Well, I'm probably the last one on this, but anyway: Microsoft released new pack of Office XML schemas and related documentation. What's included? WordprocessingML (Word), SpreadsheetML (Excel), FormTemplate XML (InfoPath) and (new!) DataDiagramingML (Visio) XSD schemas, overviews and other reference docs. Good one. Installed.
Hey, look at this cool stuff:
On to something more pleasant: Microsoft is continuing to advance on the
openness front. There are all those weblogs that I've mentioned a time
or six, there's the open-source release of the WiX installer tools
(http://sourceforge.net/projects/wix/) and now (as of today, in fact)
there's another addition to the Microsoft Open and Royalty-Free Office
2003 XML reference schema program (say THAT fast three times!), because
Microsoft just announced the release of DataDiagramML.
DataDiagramML, as you might guess from the name, is the XML schema
that's used when you save a Visio document as XML. Having this
documented has the same great interoperability benefits as
WordProcessingML offers for Word or SpreadsheetML offers for Excel.
Knowing the complete structure of the document, it's easy to modify it -
for example, you can grab information from a database and use it to
modify an existing Visio document, all through standard XML tools. The
other half of the equation is that you don't even need Visio to build a
DataDiagramML document; you can use whatever XML tool you like to output
a document that conforms to the schema, and it should open fine in
Visio.
For many years, we complained that Microsoft insisted on using
all-proprietary formats for its Office documents. Now that Word, Excel,
InfoPath, and Visio all have the capability of saving into open,
documented formats, this criticism is losing some of its sting. (Though
not all of it...*cough* Access *cough*). The next step, I think, would
be a world where the XML formats are the default, and Microsoft commits
to open up every file format they create, from Outlook Express to
Project. Then we'd have a world where your data was yours, and you could
move it to any tool you liked. I'll bet Microsoft would compete pretty
hard to keep our business on a features and benefits basis in that
world, instead of depending on format lock-in.
Anyhow, today's release is a big step forward. More details at
http://www.microsoft.com/office/xml/default.mspx and
http://www.microsoft.com/presspass/press/2004/apr04/04-15XMLSchemaPR.asp
Mike Gunderloy, ADT Mag's Developer Central Newsletter.
Well, nothing to add, Mike said enough.
I've been told privately this book is going to be totally a killer:

"Office 2003 XML: Integrating Office with the Rest of the World"
by Evan Lenz, Mary McRae, and Simon St. Laurent
This book explores the relationship between XML and Office 2003, examining how the various products in the Office suite both produce and consume XML. Beginning with an overview of the XML features included in the various Office 2003 components, Office XML 2003 provides quick and clear guidance to anyone who needs to import or export information from Office documents into other systems.
Authors are real XML and Office experts. The book is not published yet (expected in June), but worth to preorder. AFAIK should be some links to my blog in this book, must to buy it only to see it :)
Microsoft has released another WordML to HTML transfromer - Word 2003 XML Viewer (thanks to Sal for pointing that). As I expected due to images issue it won't be single XSLT stylesheet such one as was released for Word 2003 Beta 2. This time it's complete viewer application, not just XSLT stylesheet you can use in your stuff. How it's implemented? It's kinda plugin for Internet Explorer, which transforms WordML to HTML using word2html.xsl stylesheet and handles images (wordml:// URL schema) somehow. It also substitutes standard context menu in Internet Explorer when vieweing WordML docs. Basically I like it, good stuff.
So whenever you want to browse a WordML document without Word 2003 installed you can just open it in Internet Explorer (provided Word 2003 XML Viewer is installed) an let it do the job. You can also include Word 2003 XML Viewer along with your document to let users install it. Sounds not bad, but not without some deficiencies. First of all your users must have viewer installed. Second - they must use IE, third - be on Windows platform. So the question is should I proceed with my WordML to HTML stylesheet or should it be abandoned? Basically my stylesheet produces pure HTML, thus placing no prerequisites on client side. But it's XSLT processor-dependent due to image processing (.NET version is only available yet, MSXML and Saxon versions were expected). Basically I believe it's still highly useful in custom WordML processing scenarios(e.g. for Word-based blog editors). I'd like to hear your comments though.
Update: this post is outdated, see "WordML2HTML with support for images stylesheet updated" for updates.
Here is a new version of WordML2HTML XSLT stylesheet, developed by Microsoft for Word 2003 Beta2 and adapted by me to Word 2003 RTM. I called this version "1.1-.NET-script". Here is why. Along with some bug fixes (typo with w:rStyle, empty <title> in generated HTML etc) I implemented basic support for images. That required XSLT extension function, which I implemented with .NET and <msxsl:script>. MHT and MSXML/Jscript versions are coming soon.
One of consequences of the revolutionary XML support in Microsoft Office 2003 is a possibility to
unlock information in the Microsoft Office System using XML. Most likely that was deliberate decision to open Office doors for XML technology and I'm sure that's winning strategy.
Talking about transforming WordprocessingML (WordML) to HTML, what's the state of the art nowadays?
There are two related activities I'm aware of, both Microsoft rooted. First, it's "WordML to HTML XSL Transformation" XSLT stylesheet available for download at Microsoft Download Center. It's huge while well documented while unsupported beta XSLT stylesheet, which transforms Word 2003 Beta 2 XML documents to HTML. Its final release, which will also support images is expected, but who knows when?
Second, Don Box is experimenting with Wordml2XHTML+CSS transformation, mostly for the sake of his blogging workflow. He said his stylesheet is better (less global variables etc.). Apparently Don didn't finish it yet, so the stylesheet isn't available.
So one stylesheet is only for Word 2003 Beta 2 documents, second isn't ready yet, sounds bad, huh? Here is my temporary solution - original "WordML Beta 2 to HTML XSL Transformation" stylesheet fixed by me to support Word 2003 RTM XML documents. As usually with Microsoft stuff, "beta" most likely is 99% RTM version. So I fixed Beta 2 stylesheet a bit and it just works. In fact that's only namespaces that I fixed yet. I'm currently testing the stylesheet with big real documents, so chances are I'll need to modify it further.
Download version 1.0 of the stylesheet here - Word2HTML-1.0.zip. Credits due to Microsoft and personally to whoever developed the stylesheet. Any bug reports or comments are appreciated. Just post comment to this text.
Another idea is to implement support for images. Basically the idea is to decode images and save them as external files in XSLT external function and I don't see how to make it in portable way, so most likely I'll end up soon with two stylesheet versions - for MSXML and .NET. Stay tuned.
Looks like everyone but I knows it. I stumbled at Mike Gunderloy's "Working with Microsoft Office 2003 Documents and Web Services" article at OfficeZealot.com illustrating how to use INCLUDETEXT field in Word 2003. Very nice feature! Here is how it looks like for XML nerd, newbie in Word.
INCLUDETEXT field allows to have updatable field in Word 2003 document, which content is included from another document. It's actually implementation of Insert/File feature. Word 2003 Pro edition even allows partial inclusion (via XPath selection) and XSL transformation before the inclusion. Cool. It's a pity looks like it works only in Pro edition.
Here is how it looks line in WordML:
<w:p>
<w:fldSimple w:instr="INCLUDETEXT
"D:\\Temp\\books.xml" \c XML
\x /catalog/book[1]/title \* MERGEFORMAT">
<w:r>
<w:t>Included content</w:t>
</w:r>
</w:fldSimple>
</w:p>
Well, not really XMLish, but anyway. w:instr contains field's instruction text. Above instruction means "include value of /catalog/book[1]/title element from D:\\Temp\\books.xml document". Nested w:r (or other run-level elements) holds included content. Word doesn't update fields authomatically, even during document loading. Updating should be done by user from the context menu (or it can be done in code).
w:fldLock attribute can be used to prevent updating of the field.
It's text inclusion, not transclusion (when context info such as style is preserved). Inclusion of WordML elements actually works, but looks like styles and other metainformation isn't preserved, so basically you can for instance include first paragraph from another WordML doc, but without the style etc. Anyway, that's good idea to include code samples into a Word document this way, then you can modify code and onlly update fields in Word. Here is how XML samples could be included:
<w:fldSimple w:instr="INCLUDETEXT
"D:\\Temp\\books.xml" \c PCText">
Without \c PCText XML will be included as XML and shown with graphical tags.
Priscilla Walmsley, author of great "Definitive XML Schema" announced a new book, now about XML in Office 2003:
I'm pleased to announce the release of XML in Office 2003: Information
Sharing with Desktop XML, a book that I co-authored with Charles Goldfarb.
It can be found on Amazon at:
http://www.amazon.com/exec/obidos/ASIN/013142193X/priscillawalm-20
The book was designed to help the "power user" take advantage of the new
XML-related features of the Office suite (including InfoPath). It does this
by breaking down the functionality into tasks, like "Rendering and
presenting XML documents" and "Using Web services with spreadsheets", etc.
It also has a section of tutorials that cover XML-related technologies like
XSLT, XML Schema and Web services.
I'd be very interested in feedback.
Looks really tempting...
Don Box talks about his weekend hobby - getting XHTML+CSS from WordML. Using XSLT of course. And it works - Don bloggs in Word, publishing in XHTML. Resulting HTML is not optimal yet (see page source), but perfectly proves the concept.
Well, as per Don WordML and XHTML are twins separated at birth:
Our chat confirmed for me that WordML and XHTML+CSS are more alike than they are different.
Both use a fairly small number of structural markup elements and use annotations on those elements to influence formatting.
But there are reasons WordML to XHTML+CSS transformation isn't trivial enough. These are non-semantic WordML nature (no semantic markup at all or wacky lists as another example), different whitespace handling, styles inheritance and tabs. I'm sure there is much more differences over there we still don't see.
Anyway I fully agree with Don in his conclusion - WordML is just another XML vocabulary and its processing, such as generation, aggregation, querying or transformation is as easy as processing any other XML. With one small attached string - "Provided we know and understand WordML well enough."
Talking about lists. I really didn't realize lists in WordML are designed to be easily rendered. For Word rendering engine it doesn't matter a paragraph is a list item - it can just process w:listPr and rendering done. My semantically-oriented mind resist to swallow it, but it's naked truth. WordML isn't designed to be semantic document markup language like Docbook or XHTML are, it's completely different, anti-semantic, fully presentational vocabulary, designed to be easlily rendered by Word rendering engine. But XML is XML and processing of WordML is not actually different from processing Docbook. Everything is possible in XML.
I'm writing this entry to illustrate basics of generating lists in WordprocessingML documents using XSLT. Also I want to test how my office-related rants are syndicated by the wonderful OfficeZealot.com site.
[Prerequisites: Make sure you've read what "Overview of WordprocessingML" says about lists].
Basically a list in WordprocessingML consists of list format definition (<w:listDef>), list instance definition (<w:list>) and list items. A list item is just specially attributed paragraph. More formally - any paragraph with <w:listPr> element in <w:pPr> element is considered to be a list item. It works this way - list item refers to list it belongs to, while list definition refers to list format definition. List formats and list instances are defined within <w:lists> element, which is child of <w:wordDocument> element. Thus there are no list boundaries structurally, instead list items refer to a list they belong to by list ID.
It seems reasonable once you grasp it. Ok, list definitions. Here s a sample, which defines single list format (#0) and single list (#1):
As can be seen, <w:listDef> defines formatting properties for three levels. Beware - that's important that you've got defititions for all list levels your document might contain, otherwise Word won't display list item as list item. By default Word defines 8 levels for each list format. Then <w:list> element defines list instance, binding it to list format defnition in <w:ilst> element. Done with definitions, now here is a list item:
<w:p>
<w:pPr>
<w:listPr>
<w:ilvl w:val="0"/>
<w:ilfo w:val="4"/>
</w:listPr>
</w:pPr>
<w:r>
<w:t>List item text</w:t>
</w:r>
</w:p>
It's an item, which belongs to 0 level of a list number 4.
Now how this stuff can be generated in XSLT? First of all obviously you need to generate format definitions for all types of lists you gonna have in a document - ordered, unordered etc. Then you need to generate list instance definition for each list in your document, bound to appropriate format definition. And finally generate list items, refering to the nesting level and list instance they belong to. Sounds piece of cake, huh?
Let's say I have an article in my proprietary XML format (similar to XHTML though to be realistic):
And here is my stylesheet, which transforms the article into WordprocessingML document:
Ok, what's inside? You can see definitions of two list formats - first for unordered list and second for ordered. Then I generate instances of lists for each list in source XML uniquely numbering them. And finally for each list item I generate paragraph with <w:listPr> property, where I define nesting level (count(ancestor::ul|ancestor::ol)-1) and ID of the list instance it belongs to. A bit not trivial, but only a bit. Here is the result:
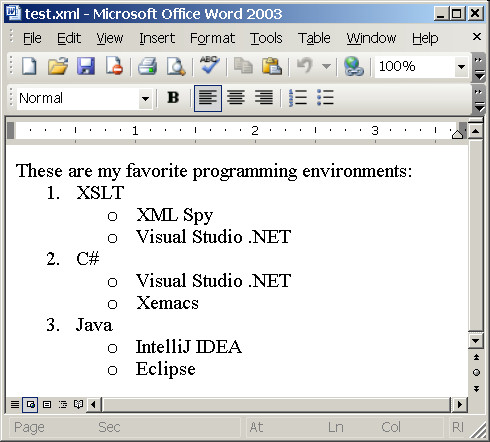
Well, lists in WordprocessingML are a bit tricky. First of all it's quite unusual to have no structural list borders. Lists are defined in document header, while list items are within document body. Hence a lot of indirection. Enables great deal of flexibility, hard to grasp though. Then naming of elements and attributes is confusing (can you say out of hand what w:ilfo or w:ilst means?). But having strong understanding of WordprocessingML you can easily generate them using XSLT. At least I hope that's the feeling you've got finishing reading this text.
Well, here is a small basic example how to generate WordprocessingML documents basing on templates. Saying "template" I don't mean regular *.dot Word templates, but just WordprocessingML XML document with predefined document/paragraph/run level properties and styles. Having such template document basically all needs to be done is to fill it with real content.
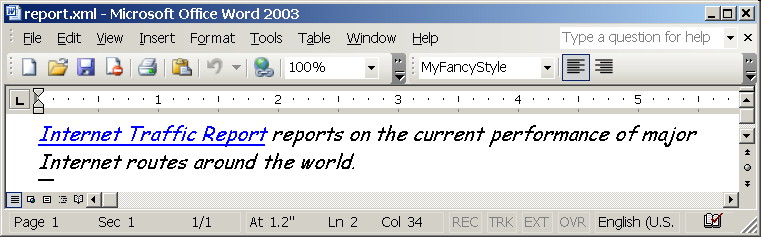
Here is such a template, it's empty Word 2003 document where I defined new style called MyFancyStyle and saved document as XML.
Here is the source of the content - a hypothetical report:
<?xml version="1.0">
<report><link
url="http://www.internettrafficreport.com/main.htm">Internet Traffic Report</link>
reports on the current performance of major Internet routes around the world.</report>
And here goes XSLT stylesheet:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:wx="http://schemas.microsoft.com/office/word/2003/auxHint"
xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml">
<xsl:variable name="root" select="/*"/>
<xsl:template match="/">
<xsl:apply-templates
select="document('d:\temp\WordTemplate.xml')/node()"
mode="template"/>
</xsl:template>
<xsl:template match="@*|node()" mode="template">
<xsl:copy>
<xsl:apply-templates select="@*|node()"
mode="template"/>
</xsl:copy>
</xsl:template>
<xsl:template match="w:body/wx:sect" mode="template">
<xsl:copy>
<xsl:apply-templates select="$root"/>
<xsl:copy-of select="wx:sectPr"/>
</xsl:copy>
</xsl:template>
<xsl:template match="report">
<w:p>
<w:pPr>
<w:pStyle w:val="MyFancyStyle"/>
</w:pPr>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="text()">
<w:r>
<w:t><xsl:value-of select="."/></w:t>
</w:r>
</xsl:template>
<xsl:template match="link">
<w:hlink w:dest="{@url}">
<w:r>
<w:rPr>
<w:rStyle w:val="Hyperlink"/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</w:hlink>
</xsl:template>
</xsl:stylesheet>
Basically what the stylesheet does? It opens template document, recursively copies all its content till it reaches w:body/wx:sect element. That's considered to be entry point for the content. Then stylesheet runs usual processing of the actual content in the source document, applying MyFancyStyle to the paragraph and after that copies wx:sectPr. Not rocket engineering indeed.
And finally here is how the result looks like. Note, real content is styled by MyFancyStyle style defined in the template.
Just discovered that WordML to XSL-FO stylesheet does exist already. Well, I was talking about it since May, so no surprise somebody more effective than me just made it done. It's Antenna House guys, developers of the best XSL-FO formatter in the market. Check out this page. Sounds reasonable, they transform elements, say w:p to fo:block, expand styles and extract images to external files (via extension function written in java for Saxon).
But wait a minute, the price is $980! No evaluation version... Gosh...
Well, seems like images are one of the WordprocessingML trickiest parts, at least for me. Here are humble results of my investigations and experiments in embedding images into XSLT-generated WordprocessingML documents.
Images in WordprocessingML are represented by w:pict element, which holds both VML and binary data (obviously Base64 encoded). VML only or VML and binary . Even if you are embedding just plain binary gif, some VML elements still needed. So VML is your friend.
The "Overview of WordprocessingML" document only gives a couple of samples, saying that "A discussion of VML is outside the scope of this document". Great. Generally speaking VML is somewhat esoteric stuff for me. Here is why.
All we've seen funny import in office.xsd schema document:
<xsd:import namespace="urn:schemas-microsoft-com:vml"
schemaLocation="C:\SCHEMAS\vml.xsd"/>
Somebody at Microsoft does have vml.xsd in C:\SCHEMAS directory, but unfortunately they forgot to put it into "Microsoft Office 2003 XML Reference Schemas" archive. Then many elements in office.xsd have such annotation "For more information on this element, please refer to the VML Reference, located online in the Microsoft Developer Network (MSDN) Library." You can find VML reference at MSDN here. But it's dated November 9, 1999 so don't expect XSD schema there.
Some clarifications are expected, watch microsoft.public.office.xml newsgroup for details.
Anyway, when inserting raster image (GIF/JPEG/PNG/etc), Word 2003 creates the following structure: <w:pict>
<v:shapetype id="_x0000_t75" ...>
... VML shape template definition ...
</v:shapetype>
<w:binData w:name="wordml://02000001.jpg">
... Base64 encoded image goes here ...
</w:binData>
<v:shape id="_x0000_i1025" type="#_x0000_t75"
style="width:212.4pt;height:159pt">
<v:imagedata src="wordml://02000001.jpg"
o:title="Image title"/>
</v:shape>
</w:pict>
First element, v:shapetype, apparently defines some shape type (note, I'm complete VML ignoramus)
. I found it to be optional. Second one, w:binData, assigns an iternal name to the image in wordml:// URI form and holds Base64 encoded image. Third one, v:shape, is main VML building block - shape.
v:shape defines image style (e.g. size) and refers to image data via v:imagedata element.
So, to generate such structure in XSLT one obviously needs some way to get Base64 encoded image. XSLT doesn't provide any facilities for that, so one easy way to implement it is extension function. In the example below I'm using extension implemented in msxsl:script element. That's just for simplicity, if I wasn''t wrinting a sample I'd use extension object of course. Btw, I believe it's good idea to provide such extension function in EXSLT.NET lib.
Finally here is a sample implementation for .NET XSLT processor. Source XML:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<article title="Pussy cat">
<para>Here goes a picture: <image
src="d:\cat.gif" alt="Cat"/></para>
</article>
And here is XSLT stylesheet:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:ext="my extension"
xmlns:v="urn:schemas-microsoft-com:vml"
exclude-result-prefixes="msxsl ext">
<msxsl:script language="C#" implements-prefix="ext">
public static string EncodeBase64(string file) {
System.IO.FileInfo fi = new System.IO.FileInfo(file);
if (!fi.Exists)
return String.Empty;
using (System.IO.FileStream fs = System.IO.File.OpenRead(file)) {
System.IO.BinaryReader br = new System.IO.BinaryReader(fs);
return Convert.ToBase64String(br.ReadBytes((int)fi.Length));
}
}
</msxsl:script>
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument>
<xsl:apply-templates/>
</w:wordDocument>
</xsl:template>
<xsl:template match="article">
<o:DocumentProperties>
<o:Title>
<xsl:value-of select="@title"/>
</o:Title>
</o:DocumentProperties>
<w:body>
<xsl:apply-templates/>
</w:body>
</xsl:template>
<xsl:template match="para">
<w:p>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="para/text()">
<w:r>
<w:t>
<xsl:attribute name="xml:space">preserve</xsl:attribute>
<xsl:value-of select="."/>
</w:t>
</w:r>
</xsl:template>
<xsl:template match="image">
<!-- internal url of the image -->
<xsl:variable name="url">
<xsl:text>wordml://</xsl:text>
<xsl:number count="image" format="00000001"/>
<xsl:text>.gif</xsl:text>
</xsl:variable>
<w:r>
<w:pict>
<w:binData w:name="{$url}">
<xsl:value-of select="ext:EncodeBase64(@src)"/>
</w:binData>
<v:shape id="{generate-id()}" style="width:100%;height:auto">
<v:imagedata src="{$url}" o:title="{@alt}"/>
</v:shape>
</w:pict>
</w:r>
</xsl:template>
</xsl:stylesheet>
And the result looks like:
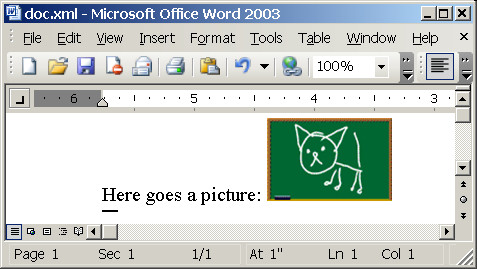
Another tricky part is image size. I found width:100%;height:auto combination to work ok for natural image size.
Still much to explore, but at least some reasonable results.
Microsoft Announces Availability of Open and Royalty-Free License For Office 2003 XML Reference Schemas : To ensure broad availability and access, Microsoft is offering the royalty-free license using XML Schema Definitions (XSDs), the cross-industry standard developed by the W3C. The license provides access to the schemas and full documentation to interested parties and is designed for ease of use and adoption. The Microsoft Office 2003 XML Reference Schemas include WordprocessingML (Microsoft Office Word 2003), SpreadsheetML (Microsoft Office Excel 2003) and FormTemplate XML schemas (Microsoft Office InfoPath 2003).
Wow, respect. I hope next step will be standardizing schemas just how it was done with CLI and C#. By the way "Generating Word documents using XSLT" approach I was talking about back in May is completely legal now and even kinda encouraged.
Funny enough, WordML is now called WordprocessingML, probably the longest ML-related acronym ever. Download WordprocessingML schema and documentation now and get back to that link 12/5/2003 to grab SpreadsheetML (Microsoft Office Excel 2003) and FormTemplate XML schemas (Microsoft Office InfoPath 2003).
The world is getting better. And the Word too! Word 2003 Beta2 now understands not only those *.doc files, but XML also. It's all as it should be in open XML world (what makes some people suspicious): there is WordML vocabulary, its schema (well documented one, btw) is available as part of Microsoft Word XML Content Development Kit Beta 2. Having said that it's obvious to go on and to assume that Word documents now may be queried using XPath or XQuery as well as transformed and generated using XSLT. Isn't it fantastic?
So here is "Hello Word!" XSLT stylesheet, which generates minimal, while still valid Word 2003 document:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument
xmlns:w="http://schemas.microsoft.com/office/word/2003/2/wordml">
<w:body>
<w:p>
<w:r>
<w:t>Hello Word!</w:t>
</w:r>
</w:p>
</w:body>
</w:wordDocument>
</xsl:template>
</xsl:stylesheet>
That <?mso-application progid="Word.Document"?> processing instruction is important one - that's how Windows recognizes an XML document as Word document. Seems like they parse only XML document prolog looking for this PI. Good idea I think.
Now let's try something more interesting - transform some XML document to formatted Word document, containing heading, italic text and link. Consider the following source doc:
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<chapter title="XSLT Programming">
<para>It's <i>very</i> simple. Just ask <link
url="http://google.com">Google</link>.</para>
</chapter>
Then XSLT stylesheet (quite big one due to verbose element-based WordML syntax):
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:w="http://schemas.microsoft.com/office/word/2003/2/wordml">
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument>
<xsl:apply-templates/>
</w:wordDocument>
</xsl:template>
<xsl:template match="chapter">
<o:DocumentProperties>
<o:Title>
<xsl:value-of select="@title"/>
</o:Title>
</o:DocumentProperties>
<w:styles>
<w:style w:type="paragraph" w:styleId="Heading3">
<w:name w:val="heading 3"/>
<w:pPr>
<w:pStyle w:val="Heading3"/>
<w:keepNext/>
<w:spacing w:before="240" w:after="60"/>
<w:outlineLvl w:val="2"/>
</w:pPr>
<w:rPr>
<w:rFonts w:ascii="Arial" w:h-ansi="Arial"/>
<w:b/>
<w:sz w:val="26"/>
</w:rPr>
</w:style>
<w:style w:type="character" w:styleId="Hyperlink">
<w:rPr>
<w:color w:val="0000FF"/>
<w:u w:val="single"/>
</w:rPr>
</w:style>
</w:styles>
<w:body>
<w:p>
<w:pPr>
<w:pStyle w:val="Heading3"/>
</w:pPr>
<w:r>
<w:t>
<xsl:value-of select="@title"/>
</w:t>
</w:r>
</w:p>
<xsl:apply-templates/>
</w:body>
</xsl:template>
<xsl:template match="para">
<w:p>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="i">
<w:r>
<w:rPr>
<w:i/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</xsl:template>
<xsl:template match="text()">
<w:r>
<w:t xml:space="preserve"><xsl:value-of
select="."/></w:t>
</w:r>
</xsl:template>
<xsl:template match="link">
<w:hlink w:dest="{@url}">
<w:r>
<w:rPr>
<w:rStyle w:val="Hyperlink"/>
<w:i/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</w:hlink>
</xsl:template>
</xsl:stylesheet>
And the resulting WordML document, opened in Word 2003:
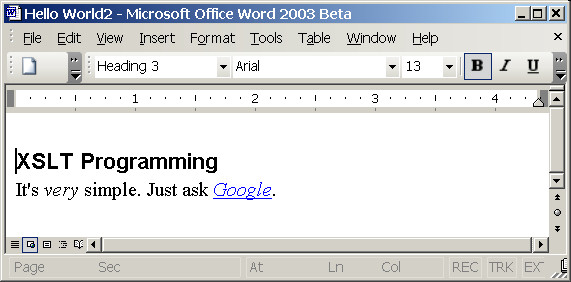
Not bad.
Everyone seems to be talking about WordML these days and it sounds really intriguing. Dare has posted a link to the Microsoft Word XML Content Development Kit Beta 2, which contains WordML XML schema.
Don Box is transforming WordML to RSS20+XHTML and says it's easier than transfroming HTML+CSS due to nonXML CSS format.
My interest though is quite opposite - to see if it's possible to transform another XML data to WordML or to put it into another way - how to implement XSLT users' ancient dream - to transform to a Word document.
WordML schema is well documented one - that's great news, well done guys. And as far as I can see it's not more complicated that XSL-FO format is, so it should be pretty doable.
So I'll give it a shot some time next week, after XInclude.NET 1.0alpha release.
|
|

Recent Comments