January 2004 Archives
MVP list was updated this night to reflect recent awards. Now it's 13 XML MVPs. It's nice to see the number (IMHO rough analogue of importance and appreciation within MSFT and the community) is growing. Meanwhile I've started to enjoy MVP benefits :) I didn't explored all yet, being lost in private universe of MVP newsgroups, wow! Other details are probably NDAed, but in simple words - it's worth to be MVP.
MSDN starts new Data Access & Storage Developer Center, msdn.microsoft.com/data, "the home for developer information on Microsoft data technologies from MSDN" (via Chris Sells). Great, worth to subscribe. List of related bloggers (indispensable attribute of any portal nowadays) - http://msdn.microsoft.com/data/community/blogs. Stars like Dino Esposito, Mike Gunderloy, Andrew Conrad, Michael Rys, Dare Obasanjo and Christa Carpentiere (the editor of this Dev Center) are amongst them. I bet Data Access & Storage Developer Center's gonna rock. Smart people plus great technology, a perfect match.
I wonder whether XML Developer Center is next on the MSDN launch pad and who will be on the editor chair?
Looks like everyone but I knows it. I stumbled at Mike Gunderloy's "Working with Microsoft Office 2003 Documents and Web Services" article at OfficeZealot.com illustrating how to use INCLUDETEXT field in Word 2003. Very nice feature! Here is how it looks like for XML nerd, newbie in Word.
INCLUDETEXT field allows to have updatable field in Word 2003 document, which content is included from another document. It's actually implementation of Insert/File feature. Word 2003 Pro edition even allows partial inclusion (via XPath selection) and XSL transformation before the inclusion. Cool. It's a pity looks like it works only in Pro edition.
Here is how it looks line in WordML:
<w:p>
<w:fldSimple w:instr="INCLUDETEXT
"D:\\Temp\\books.xml" \c XML
\x /catalog/book[1]/title \* MERGEFORMAT">
<w:r>
<w:t>Included content</w:t>
</w:r>
</w:fldSimple>
</w:p>
Well, not really XMLish, but anyway. w:instr contains field's instruction text. Above instruction means "include value of /catalog/book[1]/title element from D:\\Temp\\books.xml document". Nested w:r (or other run-level elements) holds included content. Word doesn't update fields authomatically, even during document loading. Updating should be done by user from the context menu (or it can be done in code).
w:fldLock attribute can be used to prevent updating of the field.
It's text inclusion, not transclusion (when context info such as style is preserved). Inclusion of WordML elements actually works, but looks like styles and other metainformation isn't preserved, so basically you can for instance include first paragraph from another WordML doc, but without the style etc. Anyway, that's good idea to include code samples into a Word document this way, then you can modify code and onlly update fields in Word. Here is how XML samples could be included:
<w:fldSimple w:instr="INCLUDETEXT
"D:\\Temp\\books.xml" \c PCText">
Without \c PCText XML will be included as XML and shown with graphical tags.
Well, it's Sunday. Calm and peace around newsgroups, forums and blogs. But in Israel it's workday, really. And I like it btw. RSS waves brought me today really enjoyable reading - MSDN Mag February 2004 issue. Nice. Here are couple of cynical comments though:
"Console Appplications in .NET" by Michael Brook.
I'm console-oriented guy too and my first .NET application was nxslt.exe command line utility for running XSLT (in fact I rarely run it in real command prompt, using as external transformer in XML Spy instead). But I'm not so wacky as Michael is! What he is showing in the article is "the world's first command-line RSS reader". Well, it's really hard to think up good samples for an article...
"Comparing the Timer Classes in the .NET Framework Class Library" by Alex Calvo.
I didn't realized there are three different timer classes in .NET FCL - System.Windows.Forms.Timer, System.Timers.Timer and System.Threading.Timer. Good to know. Here is a summary comparison table.
"WEB Q&A", Nancy Michell is still not aware of XInclude way for combining XML documents. Too bad, DTD sucks on combining loosely coupled documents. XSLT doesn't, but hurts perf. XInclude is the way to go.
"XML in Yukon. New Version Showcases Native XML Type and Advanced Data Handling" by Bob Beauchemin.
It's excerpt from upcoming "A First Look at Microsoft SQL Server "Yukon" Beta for Developers" book. Good intro. Here are some perls:
The introduction of this native XML data type, coupled with the emerging industry standard XQuery language, should spark a revolution in database application development.
I'm pessimistic on that. I hope for some changes, but not a revolution. And do we really need another revolution?
Having XML data inside a relational database may offend some relational purists, but it means that your data lives in a single repository for reasons having to do with administration, reliability, and control.
Hehe, poor relational purists, it's time to think XMLish.
In addition to the query capabilities of XPath, XQuery allows element and attribute construction via XSLT.
WTF? I'm sure it should be "like XSLT".
"The XQuery Designer in Action" - cool. Now I'm dying to give it a shot.
Breaking news: Aaron Skonnard is blogging! (Via Carnage4Life). A must feed for every XML geek.
Well, another wave of MVP awards spreads these days. Now I got it too. In XML area of course. Thanks to all who supported me. Thanks to MVPs who nominated me.
I see two more XMLers - DonXML and Daniel Cazzulino have been awarded too. Congrats, guys!
Update: another XmlInsider, Jeff Julian has been MVPed too. Congrats Jeff!
One more update: one more XmlInsider, Dimitre Novatchev is on board too!
Mike Gunderloy:
Coder to Developer - One of the books that is almost done, though you'll have to wait a few months to get a copy.
Amazon:
Coder to Developer: Tools and Strategies for Delivering Your Software
by Mike Gunderloy, Sybex (Publisher)
Book Description
Are you ready to take the leap from programmer to proficient developer? Based on the assumption that programmers need to grasp a broad set of core skills in order to develop high-quality software, "From Coder to Developer" teaches you these critical ground rules. Topics covered include project planning, source code control, error handling strategies, working with and managing teams, documenting the application, developing a build process, and delivering the product.
Hmmmm... Mike Gunderloy, "proficient developer", "high-quality software"... Yeah, I need this book.
Priscilla Walmsley, author of great "Definitive XML Schema" announced a new book, now about XML in Office 2003:
I'm pleased to announce the release of XML in Office 2003: Information
Sharing with Desktop XML, a book that I co-authored with Charles Goldfarb.
It can be found on Amazon at:
http://www.amazon.com/exec/obidos/ASIN/013142193X/priscillawalm-20
The book was designed to help the "power user" take advantage of the new
XML-related features of the Office suite (including InfoPath). It does this
by breaking down the functionality into tasks, like "Rendering and
presenting XML documents" and "Using Web services with spreadsheets", etc.
It also has a section of tutorials that cover XML-related technologies like
XSLT, XML Schema and Web services.
I'd be very interested in feedback.
Looks really tempting...
Somehow many believe it's impossible to get OuterXml/InnerXml out of XPathNavigator, but in fact it's merely one-screen-of-code class. And by the way, in System.Xml v2 XPathDocument2 class does have such properties already.
So I've written a small class, which exposes this omitted functionality. It's lightweight wrapper around XPathNavigator, which adds two more properties - OuterXml and InnerXml along with two more methods - WriteTo(XmlWriter) and WriteContentTo(XmlWriter).
Now the question is how to name such class. All names I came up - WritableXPathNavigator, SerializableXPathNavigator or even XPathNavigatorWriter sound too confusing. I'm asking for community help here, any ideas, please guys.
MovableType version 2.661 has been released. The release aimed completely to fix spam comments problem. New anti-spam weapon includes:
We've included a throttling measure so that comments from the same IP address can only be posted every N seconds, where N is configurable (documentation on the setting that controls N).
Gooooood!
We've also added a measure to automatically ban an IP address based on an abnormal number of comments from the same address in a short period of time.
Sweet!
Of course, there are no perfect defenses, and if you're truly concerned about the comments on your weblog, the best defense is prevention by closing old comment threads.
Actually I was thinking about closing comments on old postings, but I'm still not sure I want it. I like (real, not troll/spam) comments too much, that's the feedback I really need.
Also in 2.66, we've changed the behavior of <$MTCommentAuthorLink$> to use redirects when linking to URLs given in comments. The goal of this is to defeat the PageRank boost given to spammers by posting in the comments on a weblog.
Also interesting one. Hope it'll help. Well done, Six Apart! Upgraded my blog as usual smoothly in just one minute. Unfortunately this pack of anti-spam fixes didn't include my favorite one - "Delete this post" link in notification mail. This small (3 lines of Perl) patch includes "Delete this post" link into new comment notification mail. So whenever MT notifies me on new comment posted and I see it's viagra ad I can delete it in just one click. Ok, patched new release again, no big deal.
Now I only wait for the next spam attack to see what happens...
In the beginning Microsoft created the Microsoft.XMLDOM, known today as Msxml2.DOMDocument. And people like(d) it much. Then .NET happened and people were given XmlReader, XmlWriter, XmlDocument, XPathDocument, XPathNavigator and XmlDataDocument. Surprisingly most of us stuck to XmlDocument for no-matter-which scenario. Now we've been notified the Gods decided to kill XmlDocument and glorify XPathDocument instead. Be prepared...
Seriously, why XmlDocument is so overused? I think there are several reasons, from psychological to usability-related ones.
- For anybody with MSXML experience DOM is the obvious choice. DOM was the only data store in MSXML and the API. It's my understanding that MSXML SAX is almost only used by memory-anxious nerds. No surprise anybody with MSXML background coming to .NET takes XmlDocument with no any doubts. Such situation just cannot be changed quickly.
- XmlDocument is editable, XPathDocument is readonly. Unbeatable now, but System.Xml v2.0 gonna change it.
- XmlDocument API is simpler and more natural WRT MSXML background than XPathDocument's one in many common usage scenarios such as selecting a string value, especially it strikes the eyes when namespaces involved:
XmlNamespaceManager nsmgr = new XmlNamespaceManager(doc.NameTable);
nsmgr.AddNamespace("foo", "http://foo.com");
string val = doc.SelectSingleNode("/foo:bar/text()", nsmgr).Value; vs
XPathNavigator nav = doc.CreateNavigator();
XPathExpression expr = nav.Compile("/foo:bar/text()");
XmlNamespaceManager nsmgr = new XmlNamespaceManager(nav.NameTable);
nsmgr.AddNamespace("foo", "http://foo.com");
expr.SetContext(nsmgr);
XPathNodeIterator ni = nav.Select(expr);
ni.MoveNext();
string val = ni.Current.Value;
- XmlDocument exposes nodes, XPathDocument - cursor based API (but uses XPathNode's internally). Developers somehow like being able to select a node from document, dunno, may be it gives some secure non-virtual feelings to them?
- XmlDocument is closer to XML syntax level than XPathDocument. Developers like to work with XML declarations, entities, CDATA and OuterXml. They feel good when data store reflects XML syntax they see in Notepad. Don't ask me why.
- Developers don't care about perf. Sometimes they complain instead.
Well, we can do nothing with first and the last issues. System.Xml v2 will fix 2nd issue. Additionally XPathDocument will be improved with XSD types support, changes tracking, ability to validate, to reflect relational data via XmlAdapter etc. I'm sure they will make API more simple for ordinar developer too. In fact, System.Xml v2 gonna rock! So the only issue to cope with is community-wide DOM habit. How to kill it? I believe only with improving alternative APIs, leaving it out of XQuery-related future mainstream and evangelizing-evangelizing-evangelizing... Last task should be taken by XmlInsiders.
Btw, did you know that "dom" word means "home" in Russian?
Mark Pilgrim started a new wave of permathreding by "There are no exceptions to Postel's Law" rant arguing even malformed RSS feeds should be accepted.
I'm strongly on opposite side. Accepting malformed XML - what a heresy! My understanding of Postel's Law a bit differs. "Liberal" in "be liberal in what you accept from others" means different formats/versions/encodings, possibly obsolete and rarely used, but by no means malformed/broken/compromised.
Don Box talks about his weekend hobby - getting XHTML+CSS from WordML. Using XSLT of course. And it works - Don bloggs in Word, publishing in XHTML. Resulting HTML is not optimal yet (see page source), but perfectly proves the concept.
Well, as per Don WordML and XHTML are twins separated at birth:
Our chat confirmed for me that WordML and XHTML+CSS are more alike than they are different.
Both use a fairly small number of structural markup elements and use annotations on those elements to influence formatting.
But there are reasons WordML to XHTML+CSS transformation isn't trivial enough. These are non-semantic WordML nature (no semantic markup at all or wacky lists as another example), different whitespace handling, styles inheritance and tabs. I'm sure there is much more differences over there we still don't see.
Anyway I fully agree with Don in his conclusion - WordML is just another XML vocabulary and its processing, such as generation, aggregation, querying or transformation is as easy as processing any other XML. With one small attached string - "Provided we know and understand WordML well enough."
Talking about lists. I really didn't realize lists in WordML are designed to be easily rendered. For Word rendering engine it doesn't matter a paragraph is a list item - it can just process w:listPr and rendering done. My semantically-oriented mind resist to swallow it, but it's naked truth. WordML isn't designed to be semantic document markup language like Docbook or XHTML are, it's completely different, anti-semantic, fully presentational vocabulary, designed to be easlily rendered by Word rendering engine. But XML is XML and processing of WordML is not actually different from processing Docbook. Everything is possible in XML.
Chris Lovett has released SgmlReader version 1.2. It's mostly bug fixes release.
Via Dare Obasanjo aka Carnage4Life
SgmlReader is an XmlReader, which is able to parse SGML documents (e.g. HTML).
I'm writing this entry to illustrate basics of generating lists in WordprocessingML documents using XSLT. Also I want to test how my office-related rants are syndicated by the wonderful OfficeZealot.com site.
[Prerequisites: Make sure you've read what "Overview of WordprocessingML" says about lists].
Basically a list in WordprocessingML consists of list format definition (<w:listDef>), list instance definition (<w:list>) and list items. A list item is just specially attributed paragraph. More formally - any paragraph with <w:listPr> element in <w:pPr> element is considered to be a list item. It works this way - list item refers to list it belongs to, while list definition refers to list format definition. List formats and list instances are defined within <w:lists> element, which is child of <w:wordDocument> element. Thus there are no list boundaries structurally, instead list items refer to a list they belong to by list ID.
It seems reasonable once you grasp it. Ok, list definitions. Here s a sample, which defines single list format (#0) and single list (#1):
As can be seen, <w:listDef> defines formatting properties for three levels. Beware - that's important that you've got defititions for all list levels your document might contain, otherwise Word won't display list item as list item. By default Word defines 8 levels for each list format. Then <w:list> element defines list instance, binding it to list format defnition in <w:ilst> element. Done with definitions, now here is a list item:
<w:p>
<w:pPr>
<w:listPr>
<w:ilvl w:val="0"/>
<w:ilfo w:val="4"/>
</w:listPr>
</w:pPr>
<w:r>
<w:t>List item text</w:t>
</w:r>
</w:p>
It's an item, which belongs to 0 level of a list number 4.
Now how this stuff can be generated in XSLT? First of all obviously you need to generate format definitions for all types of lists you gonna have in a document - ordered, unordered etc. Then you need to generate list instance definition for each list in your document, bound to appropriate format definition. And finally generate list items, refering to the nesting level and list instance they belong to. Sounds piece of cake, huh?
Let's say I have an article in my proprietary XML format (similar to XHTML though to be realistic):
And here is my stylesheet, which transforms the article into WordprocessingML document:
Ok, what's inside? You can see definitions of two list formats - first for unordered list and second for ordered. Then I generate instances of lists for each list in source XML uniquely numbering them. And finally for each list item I generate paragraph with <w:listPr> property, where I define nesting level (count(ancestor::ul|ancestor::ol)-1) and ID of the list instance it belongs to. A bit not trivial, but only a bit. Here is the result:
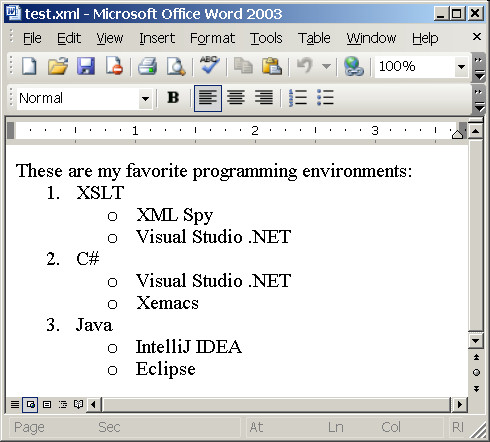
Well, lists in WordprocessingML are a bit tricky. First of all it's quite unusual to have no structural list borders. Lists are defined in document header, while list items are within document body. Hence a lot of indirection. Enables great deal of flexibility, hard to grasp though. Then naming of elements and attributes is confusing (can you say out of hand what w:ilfo or w:ilst means?). But having strong understanding of WordprocessingML you can easily generate them using XSLT. At least I hope that's the feeling you've got finishing reading this text.
Happy New Year to everybody my dear readers!
Now back to mundane things. Yesterday for the first time my blog has been seriously attacked by evil comment spammer. Last months I got used to receive 6-7 spam/troll comments a week and remove them out weekly, but this guy(application?) has sent 70 comments full of (200+) crap links during half an hour till I occasionally noted unusual activity and banned his IP.
Well, MovableType really sucks on comment spam. The only defence facility is manual IP banning. MT 3.0, whose beta is expected in Q1 2004 should make things better, they have announced it will include comment registration and improved comment management among other features. Well, I'm looking forward to see it.
Meanwhile reading discussion on comment spam in Sam's blog I realized there are really interesting ideas on detecting/blocking spam/troll comments I'd also like to try to implement myself. Unfortunately MT is perl-based engine, so the only my oprions are: learn perl or to implement frontend for MT comment subsystem in .NET. Bad ideas both. It's only now I finally see why Don Box is writing his own blog engine.
I don't dare to follow this way, but switching to .NET-based blog engine, such as dasBlog looks evem more tempting now.
|
|

Recent Comments