December 2003 Archives
Here is small HOWTO on exposing comments to MovableType-running blogs to RSS readers.
Note: Target MT versions are 2.64 and 2.65, I'm not sure about other ones.
Intro
The goals of exposing comments are: enabling for arbitrary RSS reader application to see comments made to blog items and to post new comments. There are several facilities developed by RSS commutity, which allow to achieve these goals:
- <slash:comments> RSS 2.0 extension element, which merely contains number of comments made to the specified blog item.
- RSS 2.0 <comments> element, which provides URI of the page where comments can be viewed and added (it's usually something like http://yourblog/cgi-bin/mt-comments.cgi?entry_id=blog-item-id in MT blogs).
- <wfw:commentRss> RSS 2.0 extension element, which provides URI of comment feeds per blog item (to put it another way - returns comments made to specified blog item as RSS feed).
- <wfw:comment> RSS 2.0 extension element, which provides URI for posting comments via CommentAPI.
Step 1. Exposing number of comments made to a blog item
The simplest one. Number of comments made to the current item is available via <$MTEntryCommentCount$> MT template tag. Obviously it must be used within <MTEntries> tag, which iterates over blog items:
<MTEntries lastn="15">
<item>
...
<slash:comments><$MTEntryCommentCount$></slash:comments>
...
</item>
</MTEntries>
Don't forget also to bind "slash" prefix to "http://purl.org/rss/1.0/modules/slash/" namespace URI.
Step 2. Linking to "comments to this item" page
Again simple one. MT provides enough template tags to construct URI of the Web page, where one can view and add comments. These are <$MTCGIPath$>, <$MTCommentScript$> and <$MTEntryID$>:
<MTEntries lastn="15">
<item>
...
<comments>
<$MTCGIPath$><$MTCommentScript$>?entry_id=<$MTEntryID$>
</comments>
...
</item>
</MTEntries>
Step 3. Exposing comments as RSS feeds
The idea is to generate separate RSS document for each blog item, which contains comments made to this item. This can be done in the same way as MT generates HTML file for each item and rebuilds it whenever a comment is made. One need to provide a template for such file and register it properly in MT admin. Here is a template:
To install in into MT blog: click on "Templates" in main blog admin menu, click on "Create new archive template" link, type "Individual Comment RSS archive" in "Template Name" field, paste above template into "Template Body" text area and click Save. Next click on "Weblog config" in the main menu, click on "Archiving" link, then push "ADD NEW..." button. In the dialog select "Individual" in "Archive Type" and "Individual Comment RSS archive" in "Template" select box. Push "ADD" button. Now you've got two templates for "Individual" archive type, one for regular HTML page ("Individual Entry Archive" and make sure its radiobox is selected) and second for comments ("Individual Comment RSS archive"). Now paste "commentrss/<MTEntryID pad="1">.xml" into "Archive File Template" field for "Individual Comment RSS archive". That means MT will generate {entryid}.xml file in commentrss directory for each blog entry using provided template.
Also you need to fix "Individual Entry Archive" template a bit to generate id attribute for each comment (this allows linking to a partiluar comment by its ID). Go to "Templates", click on "Individual Entry Archive", locate "<div class="comments-body">" tag and change it to "<div class="comments-body" id="c<$MTCommentID pad="1"$>">".
Now you are ready to link generated comment RSS archives in main RSS 2.0 feed:
<MTEntries lastn="15">
<item>
...
<wfw:commentRss>
<$MTBlogArchiveURL encode_xml="1">commentrss/<$MTEntryID pad="1"$>.xml
</wfw:commentRss>
...
</item>
</MTEntries>
Rebuild the site and check if it works and your favorite RSS reader is able to see comments now.
Step 4. Enabling posting comments from RSS reader via CommentAPI
Well, this is the hardest part. Unfortunately I didn't found any implementation of CommentAPI for MT. MT is written in perl, so perl hackers are invited to fill the gap. As a quick workaround I decided to write a simple ASP.NET page to operate as a proxy for MT comment posting API. This aspx page merely receives a comment posted via CommentAPI, pulls out the data and posts it to MT via MT API. Really no big deal. Here it is (code behind part):
Having this aspx page allows me to add <wfw:comment> element to my RSS feed enabling posting of comments from RSS readers supporting CommentAPI (such as RSS Bandit). Here is a relevant RSS 2.0 template part:
<MTEntries lastn="15">
<item>
...
<wfw:comment>
<$MTBlogURL$>CommentAPI2MT.aspx?entry_id=<$MTEntryID$>
</wfw:comment>
...
</item>
</MTEntries>
That's it. Pheeew. Above recipe implemented at this blog so you can test it right now. Here is my RSS 2.0 feed MT template just if you want to see the whole puzzle done. If you site doesn't support ASP.NET, the same comment proxy logic can be easily implemented in JSP or PHP or whatever server scripting.
As usual any comments, bug reports, questions and amendments are appreciated.
I've been attending Microsoft conference on Biztalk 2004 in Tel-Aviv today. Well, probably the only worth doing outcome is a mug with Biztalk logo. Beside that only one presentation by Cobby Cohen was at least substantially interesting to some degree, all other talks were pure blah-blah-copy-n-paste-from-biztalk-overview. By the way we've been shown Biztalk 2004 not-beta version, which is what I'm looking for now. Does anybody have a clue where fresh Biztalk 2004 builds are available to download?
Apparently there is no CommentAPI implementation or plugin for MovableType blogging engine. At leats I'm unable to find any. And the last thing I want to do is to code in Perl today. Well, proxy ASPX page should be just fine then.
Moving the blog I relaized it's kinda layered by dust from architectural point of view. So I upgraded MovableType engine up to the latest version (2.65), added RSS 2.0 and Atom 0.3 feeds and implemented wfw:commentRss in RSS 2.0 feed. Also I abandoned RSS 0.91 and 1.0 feeds.
Implementing wfw:commentRss in MovableType engine turned out to be a piece of cake (should I provide detailed guide for those interested?) and now I can read this blog's comments directly in RSSBandit (and I hope you can in your blogreader too). So cewl! It's a shame for Six Apart that MovableType templates don't support such feature out-of-box. Btw, Dare has complained about this inconvenience recently, I really hope he'll be satisfied now.
Unfortunately I cannot still posting comments from RSSBandit to this blog. Hmmm... Something is missed apparently. Need to read some more.
Done. I moved from Linux-based Java-featured hosting to Windows-based .NET-featured one. No problem at all, even with MovableType database. It just works, all I needed to do is to add DB_File perl module as described in MT install guide.
Finally I'm moving to the new hosting. I'm going to make it during x-mas holidays, probably the site and email won't work couple of days. If you need me, reach me via IM (I'm oleg@tkachenko.com there).
Just for your fun - I've found the song in usenet archives. Here it is:
From: jenglish@crl.com (Joe English)
Newsgroups: comp.text.sgml
Subject: A Song
Date: 24 Oct 1994 19:05:27 -0700
Organization: Helpless people on subway trains
Lines: 51
Message-ID: <38hp57$1r6@crl.crl.com>
NNTP-Posting-Host: crl.com
[ Allegro, with vigor ]
Well, if you can't do it with <!LINKTYPE ...>,
And features of SGML,
And if you can't hack it in HyTime,
No sweat! It's in DSSSL!
DSSSL!
DSSSL!
It's really cool!
A useful tool!
It's DSSSL!
"So tell me then, what does it look like?"
Afraid I can't -- nobody knows!
I guarantee you're gonna love it,
Just wait and see, that's how it goes.
DSSSL!
DSSSL!
It's like a dream!
It's based on Scheme!
It's DSSSL!
The World-Wide-Web's gotta have stylesheets,
Or HTML's going to burst.
Will DSSSL come and save us
(Unless Netscape gets to it first)?
DSSSL!
DSSSL!
Never fear,
It's almost here!
It's DSSSL!
So -- if -- FOSI's are driving you batty,
And PDF isn't enough,
This standard will solve all your problems
(But it isn't finished yet. Tough.)
DSSSL!
DSSSL!
It's amazingly great
But you'll just have to wait
For Dee-ess-ess-ess-ellllllll!
--Joe English
jenglish@crl.com
Reading last Aaron Skonnard's installment in MSDN Mag I cannot resist to note that his explanation of whitespace handling in XSLT is not actually true. Or to put it this way - it's true only for Microsoft's XSLT implementations in default mode.
Here is what Aaron says:
Before an XSLT processor executes a transformation against a given source document, it first strips all white space-only text nodes from both documents.
Well, looks like a)Aaron's only working with Microsoft XSLT processors in default mode and b)forgot what W3C XSLT Recommendation says about whitespace stripping.
It might be new for some Microsoft-oriented XSLT users, but XSLT spec explicitly says that whitespace should be preserved in source XML tree by default. Yes, even insignificant one aka whitespace-only text nodes. This is how all conforming XSLT processors should actually behave. MSXML and XslTransform are only notable exceptions. The explanation of this spec violation is that the process of whitespace stripping is done at tree-building stage and both XSLT engines have no control over it. Indeed, by default both XmlDocument and XPathDocument do strip all insignificant whitespace. And some of us seems to be so get used to it that even claim this is how XSLT should work. That's not true.
XSLT processors don't strip insignificant whitespace from source XML, that's input tree builders (MSXML's DOMDocument, XmlDocument and XPathDocument) by default do that. And if you happens to transform XmlDocument, which has been loaded with PreserveWhitespace property set to true or XPathDocument, which has been loaded with XmlSpace.Preserve argument in the costructor call you might be badly surprised. XSLT stylesheet disregarding insignificant whitespace is not a robust one, because it depends in a very fragile way on XSLT processor's environment. Not to mention using other XSLT processors such as Saxon or Xalan.
A loud example of such bad XSLT programming style is usually becomes apparent when using <xsl:apply-templates/> and position() function together. Consider the following XML document:
<root>
<item>Screwdriver</item>
<item>Hammer</item>
</root>
Then the following stylesheet:
<stylesheet version="1.0"
xmlns="http://www.w3.org/1999/XSL/Transform" >
<template match="item">
<value-of select="position()"/>:<value-of select="."/>
</template>
</stylesheet>
will output
1:Screwdriver2:Hammer
in MSXML and .NET in default (whitespace stripping) mode and
2:Screwdriver
4:Hammer
in all non-Microsoft processors and in Microsoft processors in whitespace-preserving mode.
Beware of that.
The length of a spec is directly proportional to the size of the
committee that produced it, multiplied by the number of years spent on
the effort (which also increases with the size of the committee).
Michael Kay
First working draft of XSL 1.1 has been published. Version 1.1 updates the XSL 1.0 Recommendation for change marks, indexes, multiple flows, and bookmarks, and extends support for graphics scaling, markers, and page numbers.
For those unfamiliar, that's XSL-FO spec, XML vocabulary for expression formatting semantics for high-quality paginated presentation. I've been XSL-FO zealot back in 2001-2002, working with it very closely implementing XSL-FO output channel (pdf, tiff, fax, printer) for the system I was working on that time, contemplating on this IMO the biggest W3C Recommendation ever (400+ pages), evangelizing XSL-FO by helping people on many mail lists and working on Apache FOP project (hey, I'm still olegt@apache.org). That was great experience. XSL-FO is a successor of DSSSL and has plenty of extremely interesting people from document-centric publishing world around it, yeah that was great. Nowadays that's even impossible to dig out Joe English's DSSSL song out of the NET, anyway here is another dsssl song by Tony Graham (just to make you feel that spirit):
I Use DSSSL
By Tony Graham (to the tune of "Don't Cry for Me, Argentina" by Andrew Lloyd-Webber)
This won't be easy,
you'll think it's strange.
When I try to explain how I print -
that I use an ISO standard
after all that I've done.
You won't believe me.
All you will see is the good output,
although it's dressed up to the nines -
it started with S-G-M-L
I had to let it happen.
I had to change.
Couldn't stay being proprietary.
Stuck with one vendor,
No choice of software.
So I choose freedom.
Running around, trying everything new.
But nothing impressed me at all.
I never expected it too.
Don't cry for me, I use DSSSL.
The truth is it is quite good:
Style sheet language,
Flow object tree,
A choice of backends. You should try it.
This site was down yesterday for who-knows-how-much hours because some troubles with Apache httpd of my hoster. What's the most annoying I didn't managed to get in touch any customer service. Plain silence. I'm keep getting randomly scary and mysterious "Quota exceeded while writing "/var/spool/mail/oleg"" messages, mysterious because I've got plenty free space, again no any help from support. Well, I'm preparing to move. Probably to webhost4life.com as your guys recommended. I only wonder if it's feasible to install dasBlog engine on webhost4life.com hosted site?
Chris Lovett's internal Microsoft presentation of X# language project (Oct 2002) has leaked - download it here (via jayson knight). Well, the project is dead. Probably that's good, because it really sounds like monstrous deadly mix of XSD/XSLT/XQuery/SQL and C#. But still really interesting and I strongly believe it's based on not only interesting, but fruitful ideas and we'll hear something about such thing again. As a matter of interest, BizTalk 2004 Beta includes xsharpp.exe utility, which seems to be X# to C# translator (I'm not sure actually that's the same X# though).
And here is another beast for XML bestiary I've created a year ago, but forgot to publish. I'm not sure may be someone did that already, the idea and implementation are really trivial. It's XmlNodeNavigator, which is XPathNavigator over XmlNode (as a subtree) in XmlDocument. It allows to navigate over a subtree in DOM as if it's independent XML document. The main goal of the XmlNodeNavigator is to enable XSL transformation of a portion of XmlDocument without creating temporary XmlDocument containing that portion of data.
Every XSLTers moving from MSXML to .NET usually get stuck with that. In MSXML one usually applies transformation to a node, defining by this the context XSLT operates on. Whenever you want to process only a piece of XML, just run tranformNode() on the node, which encapsulates that piece of data and all XSLT will see then is just that piece of XML, not the whole tree. In .NET though that won't work as XslTransform class applies transformation to the document as a whole, no matter which node you have passed as input. MSDN suggests using temporary XmlDocument, which contains fragment of data you want to transform. That solution is really not satisfactory, pure wasting of memory and performance penalty just for the glory of programmer's laziness. Here is where XmlNodeNavigator idea comes into play. It implements XPathNavigator over the subtree and doesn't allow to navigate outside the subtree boundaries thus enabling effective subtree transformations.
Couple of words about the implementation. XmlNodeNavigator leverages XmlDocument's native XPathNavigator internally, but in MoveTo, MoveToFirst, MoveToNext, MoveToPrevious, MoveToRoot and MoveToParent methods it additionally ensures the navigation doesn't go beyound permissible boundaries - out of the given XmlNode and its descendants. Download XmlNodeNavigator from GotDotNet and see sources for more info.
Finally a sample of transforming XML fragment using XmlNodeNavigator. Source XML:
<library>
<book genre='novel' ISBN='1-861001-57-5'>
<title>Pride And Prejudice</title>
</book>
<book genre='novel' ISBN='1-81920-21-2'>
<title>Hook</title>
</book>
</library>
And the stylesheet is just copies all available input to output:
<stylesheet version="1.0"
xmlns="http://www.w3.org/1999/XSL/Transform" >
<output indent="yes"/>
<template match="/">
<copy-of select="/"/>
</template>
</stylesheet>
The code:
XslTransform xslt = new XslTransform();
xslt.Load("test.xsl");
XmlDocument doc = new XmlDocument();
doc.Load("foo.xml");
//Navigator over first child of document element
XPathNavigator nav =
new XmlNodeNavigator(doc.DocumentElement.FirstChild);
xslt.Transform(nav, null, Console.Out, null);
The result:
<book genre="novel" ISBN="1-861001-57-5">
<title>Pride And Prejudice</title>
</book>
So, the navigator over first book element has been provided to the transformation and all the XslTransform sees at input is only this subtree - book element and its descendants. And that's done with no any interim tree. It would be really nice to see such class in v2 of System.Xml API.
Well, here is a small basic example how to generate WordprocessingML documents basing on templates. Saying "template" I don't mean regular *.dot Word templates, but just WordprocessingML XML document with predefined document/paragraph/run level properties and styles. Having such template document basically all needs to be done is to fill it with real content.
Here is such a template, it's empty Word 2003 document where I defined new style called MyFancyStyle and saved document as XML.
Here is the source of the content - a hypothetical report:
<?xml version="1.0">
<report><link
url="http://www.internettrafficreport.com/main.htm">Internet Traffic Report</link>
reports on the current performance of major Internet routes around the world.</report>
And here goes XSLT stylesheet:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:wx="http://schemas.microsoft.com/office/word/2003/auxHint"
xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml">
<xsl:variable name="root" select="/*"/>
<xsl:template match="/">
<xsl:apply-templates
select="document('d:\temp\WordTemplate.xml')/node()"
mode="template"/>
</xsl:template>
<xsl:template match="@*|node()" mode="template">
<xsl:copy>
<xsl:apply-templates select="@*|node()"
mode="template"/>
</xsl:copy>
</xsl:template>
<xsl:template match="w:body/wx:sect" mode="template">
<xsl:copy>
<xsl:apply-templates select="$root"/>
<xsl:copy-of select="wx:sectPr"/>
</xsl:copy>
</xsl:template>
<xsl:template match="report">
<w:p>
<w:pPr>
<w:pStyle w:val="MyFancyStyle"/>
</w:pPr>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="text()">
<w:r>
<w:t><xsl:value-of select="."/></w:t>
</w:r>
</xsl:template>
<xsl:template match="link">
<w:hlink w:dest="{@url}">
<w:r>
<w:rPr>
<w:rStyle w:val="Hyperlink"/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</w:hlink>
</xsl:template>
</xsl:stylesheet>
Basically what the stylesheet does? It opens template document, recursively copies all its content till it reaches w:body/wx:sect element. That's considered to be entry point for the content. Then stylesheet runs usual processing of the actual content in the source document, applying MyFancyStyle to the paragraph and after that copies wx:sectPr. Not rocket engineering indeed.
And finally here is how the result looks like. Note, real content is styled by MyFancyStyle style defined in the template.
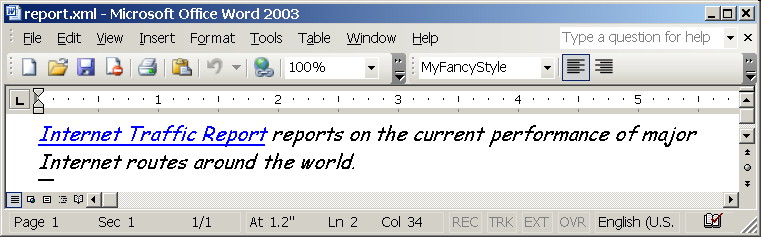
First they have closed blogs. Now Dare's moved RSS Bandit project to SourceForge. Hmmm...

Well, I'm getting tired of my current hosting. I'm ready for change, can anybody recommend unexpensive ASP.NET hosting, 100Mb/2Gb?
Today I felt the Uroboros snake breathing just in my cubicle when I realized XSLT is able to write output to the input tree. Funny, huh?
XmlDocument doc = new XmlDocument();
doc.Load("input.xml");
XslTransform xslt = new XslTransform();
xslt.Load("test.xsl");
XmlNodeWriter nw = new XmlNodeWriter(doc.DocumentElement, false);
xslt.Transform(doc, null, nw);
nw.Close();
This transformation outputs result tree directly to the document element of the input tree! Moreover, during the transformation process the input tree is being dynamically changed and XSLT processor even is able to see the output tree in input and to process it again!
Of course you'd better then not to cycle transformation forever using plain <xsl:copy-of select="/"/>.
Practical usage? Highly-efficient update of in-memory DOM using XSLT with no any interim buffers. Kinda dangerous though, because output can destroy input prior it's processed or to loop forever, but nice one anyway.
Here is another beast for XML bestiary I've created yesterday just for fun to encapsulate commonly used functionality in an efficient way. It's XmlTransformingReader class. The idea is extremelly simple: XmlTransformingReader is XmlReader implementation, which encapsulates arbitrary XSL Transformation of input XML stream. Or to put it in another way - XmlTransformingReader reads input XML stream, transforms it internally using provided XSLT stylesheet and allows the resulting XML stream to be read from itself. For code-minded geeks here is the implementation:
public class XmlTransformingReader : XmlReader {
private XmlReader _outReader;
#region Constructors
public XmlTransformingReader(string source, string transformSource) {
XPathDocument doc = new XPathDocument(source);
XslTransform xslt = new XslTransform();
xslt.Load(transformSource);
_outReader = xslt.Transform(doc, null, new XmlUrlResolver());
}
//...Dozen other constructors ...
#endregion
#region XmlReader impl methods
public override int AttributeCount {
get { return _outReader.AttributeCount;}
}
public override string BaseURI {
get { return _outReader.BaseURI; }
}
//The rest 20+ XmlReader methods/properies implemented in the same way
}
Probably even too simple, but still quite usable.
It allows to modify XML on the fly, but of course it's not streaming plumbing as it embeds XSLT. Such reader can be useful to encapsulte complex XML transformations into a single XmlReader. Sure it allows also to implement easily simple local XML modifications, traditionally performed at SAX/XmlReader level, such as renaming/filtering nodes, converting attributes to elements etc., but I urge you to keep streaming processing. The main goal of XmlTransformingReader is to enable complex XML modifications, such as involve sorting, grouping, anyone that cannot be done in forward-only non-caching way XmlReader works. It's time for a sample. Here is how one can read three most expensive items from an inventory list :
inventory.xml
<parts>
<item SKU="1001" name="Hairdrier" price="39.99"/>
<item SKU="1001" name="Lawnmower" price="299.99"/>
<item SKU="1001" name="Spade" price="19.99"/>
<item SKU="1001" name="Electric drill" price="99.99"/>
<item SKU="1001" name="Screwdriver" price="9.99"/>
</parts>
filtering stylesheet
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="parts">
<parts>
<xsl:apply-templates select="item">
<xsl:sort data-type="number"
order="descending" select="@price"/>
</xsl:apply-templates>
</parts>
</xsl:template>
<xsl:template match="item">
<xsl:if test="position() <= 3">
<xsl:copy-of select="."/>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
And finally the code:
XmlReader xtr = new XmlTransformingReader("inventory.xml", "filter.xsl");
//That's it, now let's dump out XmlTransformingReader to see what it returns
XmlTextWriter w = new XmlTextWriter(Console.Out);
w.Formatting = Formatting.Indented;
w.WriteNode(xtr, false);
xtr.Close();
w.Close();
The result:
<parts>
<item SKU="1001" name="Lawnmower" price="299.99" />
<item SKU="1001" name="Electric drill" price="99.99" />
<item SKU="1001" name="Hairdrier" price="39.99" />
</parts>
I've uploaded XmlTransformingReader sources to GotDotNet.com user samples section and surprisingly it was downloaded already 81 times in first 10 hours. Well, honestly that's not something new, all this stuff's able to do is to save couple of lines for an experienced developer, but my hope is it will be used by average users and will help them to avoid so common and so ugly piping of transformations with interim XmlDocument. Or may be it's just an exercise in advertising during these boring days. :)
XML Information Set, second edition became Proposed Rec. Mostly the Infoset is updated to reflect the fact it's going to be not only 1.0 version of XML in the near future. So major changes look like "XML 1.0". Plus emerging Namespaces in XML 1.1 adds namespace undeclaring to the infoset.
The day brought new toys - these for me:
 
And this one for Ju-ju:

Everybody knows grouping in XSLT is kinda advanced topic. Muenchian method is just a nightmare for XSLT newbies and XSLT-related newsgroups are full of help-me-to-group-in-xsl postings. Well, and I and fellows do answer such questions day afer day. Should admit that's a way booooring. Now I wonder why we don't use EXSLT to simplify grouping technique so even newsbies can grasp it quickly? I'm talking about set:distinct function, which can replace the dreadful and mysterious generate-id()=generate-id(key('theKey', foo)[1]) step in Muenchian method.
Here is a common grouping sample along with both classical solution (pure Muenchian method) and improved one (EXSLT-based). So compare and say which is more understandable.
Source XML, list of cities.
<doc>
<city name="Paris" country="France"/>
<city name="Madrid" country="Spain"/>
<city name="Vienna" country="Austria"/>
<city name="Barcelona" country="Spain"/>
<city name="Salzburg" country="Austria"/>
<city name="Bonn" country="Germany"/>
<city name="Lyon" country="France"/>
<city name="Hannover" country="Germany"/>
<city name="Calais" country="France"/>
<city name="Berlin" country="Germany"/>
</doc>
The task is to group them by countries:
<doc>
<country name="France">
<city>Paris</city>
<city>Lyon</city>
<city>Calais</city>
</country>
<country name="Spain">
<city>Madrid</city>
<city>Barcelona</city>
</country>
<country name="Austria">
<city>Vienna</city>
<city>Salzburg</city>
</country>
<country name="Germany">
<city>Bonn</city>
<city>Hannover</city>
<city>Berlin</city>
</country>
</doc>
Solution #1, classical Muenchian method:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:key name="kCountry" match="city" use="@country"/>
<xsl:template match="doc">
<doc>
<xsl:for-each
select="city[generate-id()=generate-id(key('kCountry', @country)[1])]">
<country name="{@country}">
<xsl:apply-templates select="key('kCountry', @country)"/>
</country>
</xsl:for-each>
</doc>
</xsl:template>
<xsl:template match="city">
<city><xsl:value-of select="@name"/></city>
</xsl:template>
</xsl:stylesheet>
Solution #2, EXSLT based one:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:set="http://exslt.org/sets" exclude-result-prefixes="set">
<xsl:key name="kCountry" match="city" use="@country"/>
<xsl:template match="doc">
<doc>
<xsl:for-each select="set:distinct(city/@country)">
<country name="{.}">
<xsl:apply-templates select="key('kCountry', .)"/>
</country>
</xsl:for-each>
</doc>
</xsl:template>
<xsl:template match="city">
<city><xsl:value-of select="@name"/></city>
</xsl:template>
</xsl:stylesheet>
Both stylesheets are almost the same except bolded parts. My measurements (using nxslt.exe with -t option) say it takes the same time to execute both stylesheets and frankly I don't see why it could be different. But set:distinct(city/@country) and city[generate-id()=generate-id(key('kCountry', @country)[1])] do differ, don't they?
Well, the only obvious contra is that Muenchian method is portable as pure XSLT, while EXSLT based method relies on optional EXSLT implementation.
Mike Gunderloy has been programming computers for over 25 years now, and still manages to keep up somehow. When he's not writing software or writing about software, he's living a life of near-hermitude in the hills of eastern Washington state, raising children, chickens, and garlic.
From "An Interview with author Mike Gunderloy" at the MCSE World.
The best bio I've ever read.
Just discovered that WordML to XSL-FO stylesheet does exist already. Well, I was talking about it since May, so no surprise somebody more effective than me just made it done. It's Antenna House guys, developers of the best XSL-FO formatter in the market. Check out this page. Sounds reasonable, they transform elements, say w:p to fo:block, expand styles and extract images to external files (via extension function written in java for Saxon).
But wait a minute, the price is $980! No evaluation version... Gosh...
Well, seems like images are one of the WordprocessingML trickiest parts, at least for me. Here are humble results of my investigations and experiments in embedding images into XSLT-generated WordprocessingML documents.
Images in WordprocessingML are represented by w:pict element, which holds both VML and binary data (obviously Base64 encoded). VML only or VML and binary . Even if you are embedding just plain binary gif, some VML elements still needed. So VML is your friend.
The "Overview of WordprocessingML" document only gives a couple of samples, saying that "A discussion of VML is outside the scope of this document". Great. Generally speaking VML is somewhat esoteric stuff for me. Here is why.
All we've seen funny import in office.xsd schema document:
<xsd:import namespace="urn:schemas-microsoft-com:vml"
schemaLocation="C:\SCHEMAS\vml.xsd"/>
Somebody at Microsoft does have vml.xsd in C:\SCHEMAS directory, but unfortunately they forgot to put it into "Microsoft Office 2003 XML Reference Schemas" archive. Then many elements in office.xsd have such annotation "For more information on this element, please refer to the VML Reference, located online in the Microsoft Developer Network (MSDN) Library." You can find VML reference at MSDN here. But it's dated November 9, 1999 so don't expect XSD schema there.
Some clarifications are expected, watch microsoft.public.office.xml newsgroup for details.
Anyway, when inserting raster image (GIF/JPEG/PNG/etc), Word 2003 creates the following structure: <w:pict>
<v:shapetype id="_x0000_t75" ...>
... VML shape template definition ...
</v:shapetype>
<w:binData w:name="wordml://02000001.jpg">
... Base64 encoded image goes here ...
</w:binData>
<v:shape id="_x0000_i1025" type="#_x0000_t75"
style="width:212.4pt;height:159pt">
<v:imagedata src="wordml://02000001.jpg"
o:title="Image title"/>
</v:shape>
</w:pict>
First element, v:shapetype, apparently defines some shape type (note, I'm complete VML ignoramus)
. I found it to be optional. Second one, w:binData, assigns an iternal name to the image in wordml:// URI form and holds Base64 encoded image. Third one, v:shape, is main VML building block - shape.
v:shape defines image style (e.g. size) and refers to image data via v:imagedata element.
So, to generate such structure in XSLT one obviously needs some way to get Base64 encoded image. XSLT doesn't provide any facilities for that, so one easy way to implement it is extension function. In the example below I'm using extension implemented in msxsl:script element. That's just for simplicity, if I wasn''t wrinting a sample I'd use extension object of course. Btw, I believe it's good idea to provide such extension function in EXSLT.NET lib.
Finally here is a sample implementation for .NET XSLT processor. Source XML:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<article title="Pussy cat">
<para>Here goes a picture: <image
src="d:\cat.gif" alt="Cat"/></para>
</article>
And here is XSLT stylesheet:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:ext="my extension"
xmlns:v="urn:schemas-microsoft-com:vml"
exclude-result-prefixes="msxsl ext">
<msxsl:script language="C#" implements-prefix="ext">
public static string EncodeBase64(string file) {
System.IO.FileInfo fi = new System.IO.FileInfo(file);
if (!fi.Exists)
return String.Empty;
using (System.IO.FileStream fs = System.IO.File.OpenRead(file)) {
System.IO.BinaryReader br = new System.IO.BinaryReader(fs);
return Convert.ToBase64String(br.ReadBytes((int)fi.Length));
}
}
</msxsl:script>
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument>
<xsl:apply-templates/>
</w:wordDocument>
</xsl:template>
<xsl:template match="article">
<o:DocumentProperties>
<o:Title>
<xsl:value-of select="@title"/>
</o:Title>
</o:DocumentProperties>
<w:body>
<xsl:apply-templates/>
</w:body>
</xsl:template>
<xsl:template match="para">
<w:p>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="para/text()">
<w:r>
<w:t>
<xsl:attribute name="xml:space">preserve</xsl:attribute>
<xsl:value-of select="."/>
</w:t>
</w:r>
</xsl:template>
<xsl:template match="image">
<!-- internal url of the image -->
<xsl:variable name="url">
<xsl:text>wordml://</xsl:text>
<xsl:number count="image" format="00000001"/>
<xsl:text>.gif</xsl:text>
</xsl:variable>
<w:r>
<w:pict>
<w:binData w:name="{$url}">
<xsl:value-of select="ext:EncodeBase64(@src)"/>
</w:binData>
<v:shape id="{generate-id()}" style="width:100%;height:auto">
<v:imagedata src="{$url}" o:title="{@alt}"/>
</v:shape>
</w:pict>
</w:r>
</xsl:template>
</xsl:stylesheet>
And the result looks like:
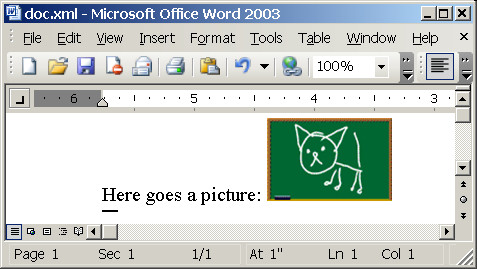
Another tricky part is image size. I found width:100%;height:auto combination to work ok for natural image size.
Still much to explore, but at least some reasonable results.
|
|

Recent Comments