May 2003 Archives
Here is another easy-to-solve-when-you-know-what-is-wrong problem. It took me couple of hours to find the solution, so I wanna share it. Hope it'll be useful to anybody.
The problem. When adding custom XPath extension functions as described in "HOW TO: Implement and Use Custom Extension Functions When You Execute XPath Queries in Visual C# .NET" KB article and "Adding Custom Functions to XPath" article at MSDN Extreme XML column you can find that any XPath expressions having namespace prefixes, like "/foo:bar" just can't be evaluated due to nasty System.ArgumentNullException deeply in the XPath engine.
The reason. It turned out that internal XPath classes, e.g. BaseAxisQuery expect custom XsltContext implementation to resolve namespaces prefixes (XsltContext extends XmlNamespaceManager) with respect to the NameTable, just as internal default XsltContext implementation - UndefinedXsltContext class does. The documentaion unfortunately omits that point and sample implementation in the above articles too.
The solution. Just override LookupNamespace(string prefix) method in your XsltContext implementation and pass given prefix through the NameTable:
public override string LookupNamespace(string prefix) {
if (prefix == String.Empty)
return String.Empty;
string uri = base.LookupNamespace(NameTable.Get(prefix));
if (uri == null)
throw new XsltException("Undeclared namespace prefix - " +
prefix, null);
return uri;
}
Easy, ain't it? I'm stupid spent two hours to get it.
Tim Bray on well-crafted spam: ongoing aloihin Backhuhn ambulant chopin. That's funny. You know, spam became a part of our life. But being behind mozilla's junk mail filtering I'd agree - we are winning.
Dare has published a new cool article at his MSDN Extreme XML column: "EXSLT: Enhancing the Power of XSLT". It's about Dare's implementation of 60+ EXSLT functions for .NET XSLT processor. Kudos! That was a pile of work due to number of functions, I'm sure the community will appreciate Dare's efforts to let users just write set:distinct(//foo) instead of using advanced Muenchian grouping method involving keys and fiddling with generated IDs just to get set of distinct nodes.
XSLT first of all is meant to be a declarative language, that's why such additional functionality worth much - it allows to keep declarative nature of the language in a real world allowing programmers to declare their intents and delegate actual implementation to an XSLT processor. Btw, forthcoming XPath 2.0 will provide even more: 200+ additional functions and operators!
One serious question is about function names: due to technical issues it's impossible in .NET to create XSLT extension function with hyphenated name, like add-duration(). That's because in .NET XSLT extension function names are reflected directly to extension object methods and afaik (I wish I'm wrong) there is no way to fake method's name other that hacking IL code in a compiled assembly. It really hurts portability, which is on the one hand what EXSLT initiative is about and I'm sure some people will say it's one more embrace-and-extend example of Microsoft politics. Come on, I'm not MSFT worker and believe me that's not the case, really. That's completely technical issue, I also desperately tried to find any clean workaround but with no success. Look at it from another point of view - XSLT programmers do really need these functions, and that's fine to give them EXSLT even if some functions have nonportable names.
Fortunately we've found a solution for another even more serious problem.
I believe Dare's implementation should outgrow article's boundaries and become a project on its own, e.g. at GotDotNet Workspaces, there is much room for enhancements and I'm sure more versions to come.
I'm going to provide EXSLT support to my nxslt pygmy - .NET XSLT command line utility, that should be handy to encapsulate (hacked to provide EXSLT-conformant function names?) Dare's implementation within nxslt and to get EXSLT-aware .NET XSLT processor. Tomorrow.
May Issue of .Net Developer Journal is available for free in PDF format. Good for those not subscribed like me.
[Via Roy Osherove].
Wow, while reading CORPORATE MOFO reloads THE MATRIX by Ken Mondschein I felt my flesh crawled when he shows how deep the ideas behind the Matrix movie can be. "cinematic ass-stomping" :) Worthwhile reading anyway. I knew it at the heart - the Matrix movie is just a postindustrial holy book evangelizing ancient ideas about the universe and insubstantial nature of the real world.
<silly-lyrical-digression>Before I became a programmer I was a guy mostly reading and trying to practice zen, gnostical apocryphs, Kastaneda, Gurdjieff and all that jazz. Prolonged rebel youth, hehe. Then being in a permanent deadlock I've modified myself into a techie, mostly reading and thinking about specs and practical life questions, that's who I am now. Actually I thought there is no way back and it was just a wacky wasted years, but now funny enough the Matrix movie makes me guessing it wasn't 180-degree turn and I'm still going my own way? Gurdjieff cannot be wrong after all: "There do exist enquiring minds, which long for the truth of the heart, seek it, strive to solve the problems set by life, try to penetrate to the essence of things and phenomena and to penetrate into themselves. If a man reasons and thinks soundly, no matter which path he follows in solving these problems, he must inevitably arrive back at himself, and begin with the solution of the problem of what he is himself and what his place is in the world around him."
</silly-lyrical-digression>
I like this from XSL-List by David Carlisle:
XSLT 2 appears to be based on user concerns and problems.
Apart from this character encoding feature (which is also useful in non
xml outout, eg outputting TeX commands in text output) It also has a lot
of help for grouping and of course user xslt defined portable extension
functions.
If only the same could be said for Xpath2....
Finally Matrix has been reloaded in Israel. Just back from the movie. Well, for sure I have to contemplate on that and to see it again, may be then I will be able to formulate my feelings...
Update: This hack is about .NET 1.X. In .NET 2.0 you don't need it. In .NET 2.0 with XslCompiledTransform class you can return a nodeset as XPathNodeNavigator[].
As all we know, unfortunately there is a confirmed bug in .NET Framework's XSLT implementation, which prevents returning a nodeset from an XSLT extension function. Basically the problem is that XSLT engine expects nodeset resulting from an extension function to be an object of internal ResetableIterator class. Full stop :(
Some workarounds were discovered, first one - to create new interim DOM object and query it by XPath, what returns instance of ResetableIterator class. Main deficiency - loss of nodes identity, because returned nodes belong to the interim DOM tree, not to input nodeset. Another workaround, discovered by Dimitre Novatchev is to to run interim XSL transformation within an extension function - this also allows to create instance of ResetableIterator class to return.
This morning I've found another workaround, which doesn't require creation of any interim objects. It's frontal attack and someone would call it a hack, but I wouldn't. Here it is. There is internal XPathArrayIterator class in System.Xml.XPath namespace, which represents XPathNodeIterator over ArrayList and also kindly implements our beloved ResetableIterator class. So why not just instantiate it by reflection and return from an extension function, huh?
Assembly systemXml = typeof(XPathNodeIterator).Assembly;
Type arrayIteratorType =
systemXml.GetType("System.Xml.XPath.XPathArrayIterator");
return (XPathNodeIterator)Activator.CreateInstance(
arrayIteratorType,
BindingFlags.Instance | BindingFlags.Public |
BindingFlags.CreateInstance,
null, new object[]{myArrayListofNodes},
null);
Below is proof-of-concept extension function to filter distinct nodes from a nodeset:
Extension function impl and test class:
using System;
using System.Xml.XPath;
using System.Xml.Xsl;
using System.IO;
using System.Reflection;
using System.Collections;
namespace Test2 {
class Test {
static void Main(string[] args){
XPathDocument doc = new XPathDocument(args[0]);
XslTransform trans = new XslTransform();
trans.Load(args[1]);
XsltArgumentList argList = new XsltArgumentList();
argList.AddExtensionObject("http://foo.com",
new MyXsltExtension());
trans.Transform(doc, argList, new StreamWriter(args[2]));
}
}
public class MyXsltExtension {
public XPathNodeIterator distinct(XPathNodeIterator nodeset) {
Hashtable nodelist = new Hashtable();
while(nodeset.MoveNext()) {
if(!nodelist.Contains(nodeset.Current.Value)) {
nodelist.Add(nodeset.Current.Value, nodeset.Current);
}
}
Assembly systemXml = typeof(XPathNodeIterator).Assembly;
Type arrayIteratorType =
systemXml.GetType("System.Xml.XPath.XPathArrayIterator");
return (XPathNodeIterator)Activator.CreateInstance(
arrayIteratorType,
BindingFlags.Instance | BindingFlags.Public |
BindingFlags.CreateInstance,
null, new object[]{new ArrayList(nodelist.Values)},
null);
}
}
}
Source xml doc (exsl:distinct()'s example):
<doc>
<city name="Paris"
country="France"/>
<city name="Madrid"
country="Spain"/>
<city name="Vienna"
country="Austria"/>
<city name="Barcelona"
country="Spain"/>
<city name="Salzburg"
country="Austria"/>
<city name="Bonn"
country="Germany"/>
<city name="Lyon"
country="France"/>
<city name="Hannover"
country="Germany"/>
<city name="Calais"
country="France"/>
<city name="Berlin"
country="Germany"/>
</doc>
Stylesheet:
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"
xmlns:ext="http://foo.com" extension-element-prefixes="ext">
<xsl:template match="/">
<distinct-countries>
<xsl:for-each select="ext:distinct(//@country)">
<xsl:value-of select="."/>
<xsl:if test="position() != last()">, </xsl:if>
</xsl:for-each>
</distinct-countries>
</xsl:template>
</xsl:stylesheet>
And the result is:
<distinct-countries>
Germany, Austria, Spain, France
</distinct-countries>
I like it. Comments?
Just released XInclude.NET 1.0beta.
Changes since 1.0alpha:
So enjoy.
Sometimes at rainy days of our life we can found ourself looking for a way to create something impossible, say a method containing dash in its name ;)
Well, if it seems to be impossible in one reality, try another one. It's impossible in C#, but it's possible in MSIL, so here is a hack:
- Disassemble your dll or executable using the MSIL Disassembler:
ildasm.exe /out=Lib.il Lib.dll
(Note, ildasm creates also resource file Lib.res along with Lib.il, you'll need this file afterwards).
-
Find your method in the decompliled MSIL (Lib.il), usually it looks like
.method public hidebysig instance string
FunnyMethod(string s) cil managed
and make its name more funny, inserting a dash (then you have to surround method's name by apostrophes to satisfy the syntax analyzer):
.method public hidebysig instance string
'Funny-Method'(string s) cil managed
- Now just assemble fixed MSIL file back to dll or executable using the MSIL Assembler:
ilasm.exe Lib.il /RESOURCE=Lib.res /DLL
That's it, you've created Lib.dll assembly, which contains Funny-Method(string) method in your class. Of course you can't invoke this method directly, but only through reflection, but sometimes that's enough.
Oh, and last thing - it's a hack, don't use it.
I've implemented XPointer support (shorthand pointer, xmlns(), element() and xpath1() schemas) for the XInclude.NET project.
(Btw, I'm wondering if XPointer may be useful not only in XInclude context?)
It was really fun and good exercise. Here are some details:
Parsing. XPointer grammar is actually one of the simplest and can be easily parsed even by regexp, as Gudge has demonstrated in his implementation. But I'm not regexp fan, especially for parsing. (I'm lex/yacc fan for ages). Instead I decided to write custom lexer and parser, just as .NET guys did for XPath and C#. Lexer (aka scanner) scans the expression char by char, taking care about escaping and builds low-level lexemes (NCName, QName, Number etc). Parser then assembles those lexemes into a higher-level grammar constructs (PointerPart, SchemaName, SchemaData etc) according to the grammar and builds XPointer object model, aka compiled XPointer pointer, ready for evaluation.
It took me the whole day, but now I can agree to some degree with Peter Hallam, when he explained why they didn't use lex/yacc in C# compiler - sometimes it's really more fast and maintainable than lex/yacc based solution.
Evaluating. Well, I chose easy way and implemented XPointer evaluation using XmlDocument, just as Gudge did. It's so attractively easy. XPathDocument though should be a better candidate from many points of view: performace (it's more optimized for XPath evaluation), memory footprint (it's read-only) and data model conformance (there are subtle differences between underlying XmlDocument and XPathDocument data models, e.g. about adjacent text nodes - DOM allows them, but XPath data model doesn't). I'll consider to move to XPathDocument later, that would additionally require XmlReader wrapper around XPathNavigator, but fortunately Don has solved that problem already.
That's it. It looks quite powerful and seems to be working fine. E.g.
<xi:inlcude href="test2.xml#xmlns(foo=http://foo.com)
xpath1(//foo:item[@name='bar'])
element(items3/2)"/>
This includes all item elements in "http://foo.com" namespace, which have "bar" as name attribute's value or if such not found for some reason it includes second child element of the element with "items3" ID.
Now cleaning, commenting, documenting, testing and releasing.
Working on XPointer parser for the XInclude.NET project I just realized there is no way (if I'm not mistaken) in .NET to check if a character is XML whitespace character. Plus all that functionality needed when parsing XML lexical constructs. No big deal, had to resort to old java trick:
public static bool IsWhitespace(char ch) {
return (ch <= 0x0020) &&
(((((1L << 0x0009) |
(1L << 0x000A) |
(1L << 0x000C) |
(1L << 0x000D) |
(1L << 0x0020)) >> ch) & 1L) != 0);
}
And that's a double pity, because XmlCharType class does implement all that XML-related lexical jazz in a very optimized way, but it's internal and not all of its power is exposed through other means (e.g. it's possible to verify a string as XML NCName using XmlConvert.VerifyNCName(string) method, which leverages XmlCharType underneath).
More good news: as Joshua Allen has confirmed, they are working on making XmlReader easier to implement. Primarily by "making some stuff that is currently abstract virtual". I look forward to see it.
New XSLT 2.0 Working Draft has been published. Interesting changes since November 2002 version:
- A new bunch of date/time formatting functions.
- "It is now a static error for xsl:call-template to supply a parameter whose name does not match the name of any parameter declared in the called template.". Wow, that's incompatible change, XSLT 1.0 allows it.
- All serialization questions are moved to the new "XSLT and XQuery Serialization" WD.
- "It is now an error to reference the context item from a global variable definition, if no initial context node is supplied to the stylesheet."
- New instruction, xsl:next-match, which allows to apply matching templates, but with lower precedence and/or priority.
- A replacement for notorious disable-output-escaping feature - xsl:character-map instruction.
- The xsl:value-of instruction and attribute value templates now output all values in the supplied sequence, unless backwards compatible behavior is enabled.
- New system properties: xsl:product-name, xsl:product-version, xsl:is-schema-aware, xsl:supports-serialization and xsl:supports-backwards-compatibility.
Also 9 (yes, nine) other XPath/XQuery/XSLT related Working Drafts have been published, see http://www.w3.org/TR.
Gudge
thinks it's better to expose synthetic xml:base attribute as first one in order to solve access-by-index problem. Sounds convincing. I actually didn't implement index-based access yet, but only access by navigational methods MoveToFirstAttribute()/MoveToNextAttribute()/MoveToAttribute(). Last one is obvious, and in first and second ones my logic was as follows - when core method call returns false, I treat it as there-is-no-more-attributes and switch the state machine to exposing synthetic xml:base attribute, so it's always latest one.
But I wasn't clear about my main concern in this topic - in fact xml:base attribute might not be
synthetic if a top-level included element has already xml:base attribute. In this case according to XInclude spec its value should be replaced hence in GetAttribute(int index)/this[int index] method if index is existing xml:base attribute's index, another value should be returned, so the question is how to find out existing xml:base attribute's index without resorting to interim attribute collection.
Quite interesting analysis by Chris Suellentrop, unexpected conclusion - Neo is an early adopter of the Matrix product.
[Via Robert McLaws.]
The world is getting better. And the Word too! Word 2003 Beta2 now understands not only those *.doc files, but XML also. It's all as it should be in open XML world (what makes some people suspicious): there is WordML vocabulary, its schema (well documented one, btw) is available as part of Microsoft Word XML Content Development Kit Beta 2. Having said that it's obvious to go on and to assume that Word documents now may be queried using XPath or XQuery as well as transformed and generated using XSLT. Isn't it fantastic?
So here is "Hello Word!" XSLT stylesheet, which generates minimal, while still valid Word 2003 document:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument
xmlns:w="http://schemas.microsoft.com/office/word/2003/2/wordml">
<w:body>
<w:p>
<w:r>
<w:t>Hello Word!</w:t>
</w:r>
</w:p>
</w:body>
</w:wordDocument>
</xsl:template>
</xsl:stylesheet>
That <?mso-application progid="Word.Document"?> processing instruction is important one - that's how Windows recognizes an XML document as Word document. Seems like they parse only XML document prolog looking for this PI. Good idea I think.
Now let's try something more interesting - transform some XML document to formatted Word document, containing heading, italic text and link. Consider the following source doc:
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<chapter title="XSLT Programming">
<para>It's <i>very</i> simple. Just ask <link
url="http://google.com">Google</link>.</para>
</chapter>
Then XSLT stylesheet (quite big one due to verbose element-based WordML syntax):
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:w="http://schemas.microsoft.com/office/word/2003/2/wordml">
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument>
<xsl:apply-templates/>
</w:wordDocument>
</xsl:template>
<xsl:template match="chapter">
<o:DocumentProperties>
<o:Title>
<xsl:value-of select="@title"/>
</o:Title>
</o:DocumentProperties>
<w:styles>
<w:style w:type="paragraph" w:styleId="Heading3">
<w:name w:val="heading 3"/>
<w:pPr>
<w:pStyle w:val="Heading3"/>
<w:keepNext/>
<w:spacing w:before="240" w:after="60"/>
<w:outlineLvl w:val="2"/>
</w:pPr>
<w:rPr>
<w:rFonts w:ascii="Arial" w:h-ansi="Arial"/>
<w:b/>
<w:sz w:val="26"/>
</w:rPr>
</w:style>
<w:style w:type="character" w:styleId="Hyperlink">
<w:rPr>
<w:color w:val="0000FF"/>
<w:u w:val="single"/>
</w:rPr>
</w:style>
</w:styles>
<w:body>
<w:p>
<w:pPr>
<w:pStyle w:val="Heading3"/>
</w:pPr>
<w:r>
<w:t>
<xsl:value-of select="@title"/>
</w:t>
</w:r>
</w:p>
<xsl:apply-templates/>
</w:body>
</xsl:template>
<xsl:template match="para">
<w:p>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="i">
<w:r>
<w:rPr>
<w:i/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</xsl:template>
<xsl:template match="text()">
<w:r>
<w:t xml:space="preserve"><xsl:value-of
select="."/></w:t>
</w:r>
</xsl:template>
<xsl:template match="link">
<w:hlink w:dest="{@url}">
<w:r>
<w:rPr>
<w:rStyle w:val="Hyperlink"/>
<w:i/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</w:hlink>
</xsl:template>
</xsl:stylesheet>
And the resulting WordML document, opened in Word 2003:
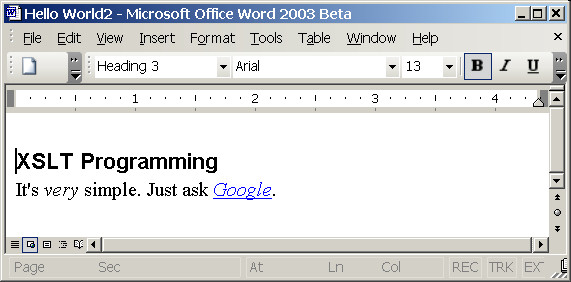
Not bad.
Gudge is mediatating on exposing synthetic attributes in XmlReader.
Here are some details on how I've implemented synthetic xml:base attribute in the XIncludingReader.
List of members implementing the logic:
MoveToAttribute(), MoveToFirstAttribute(), MoveToNextAttribute(), ReadAttributeValue(), HasValue, IsDefault, Name, LocalName, NamespaceURI, NodeType, Prefix, QuoteChar, MoveToNextAttribute(), ReadAttributeValue(), Value, ReadInnerXml(), ReadOuterXml(), ReadString(), AttributeCount, GetAttribute().
It's 20 (+ overloaded ones), yeah, in SAX it's much easier, but anyway that's not a rocket engineering - it's only 2-3 lines in each member after all. I wonder if in V2 XML API something would be changed, they say they are working on improving the piping also.
Another point - I'm exposing xml:base on the fly, as last attribute (as Gudge has properly supposed), but this approach doesn't help with GetAttribute(int)/MoveToAttribute(int) methods, probably I have to collect all existing attributes to some collection once and operate only on it afterwards.
I've released first alpha version of XInclude.NET library today. Once I got xml:base working and meekly passed through XInclude Conformance Test Suite with almost no fails I decided to release this stuff. There is still plenty room for optimizations and XPointer is still not supported, anyway I like "release early/often" motto. So enjoy and file bugs :).
Exposing a virtual xml:base attribute in XmlReader was really a showstopper. I solved it by introducing simple state machine and fiddling with it in MoveToNextAttribute(), ReadAttributeValue() and other attribute-related methods.
So, XPointer is now the agenda. I still believe it's possible to avoid using
XmlDocument's or XPathDocument facilities, because that assumes loading the whole document into memory. element() schema and shorthand pointer both should be implementable in a forward-only manner, the only problem here is how to determine ID-typed attributes, which would require reading DTD or even schema. Hmmm, well, will see.
Everyone seems to be talking about WordML these days and it sounds really intriguing. Dare has posted a link to the Microsoft Word XML Content Development Kit Beta 2, which contains WordML XML schema.
Don Box is transforming WordML to RSS20+XHTML and says it's easier than transfroming HTML+CSS due to nonXML CSS format.
My interest though is quite opposite - to see if it's possible to transform another XML data to WordML or to put it into another way - how to implement XSLT users' ancient dream - to transform to a Word document.
WordML schema is well documented one - that's great news, well done guys. And as far as I can see it's not more complicated that XSL-FO format is, so it should be pretty doable.
So I'll give it a shot some time next week, after XInclude.NET 1.0alpha release.
|
|

Recent Comments